Refine search
Actions for selected content:
212758 results in Engineering
28 - Basics of Statistical Decision Theory
- from Part VI - Statistical Applications
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 571-587
-
- Chapter
- Export citation
12 - Entropy of Ergodic Processes
- from Part II - Lossless Data Compression
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 231-244
-
- Chapter
- Export citation
14 - Neyman–Pearson Lemma
- from Part III - Hypothesis Testing and Large Deviations
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 281-295
-
- Chapter
- Export citation
11 - Fixed-Length Compression and Slepian–Wolf Theorem
- from Part II - Lossless Data Compression
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 214-230
-
- Chapter
- Export citation
Part I - Information Measures
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 5-6
-
- Chapter
- Export citation
19 - Channel Capacity
- from Part IV - Channel Coding
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 378-401
-
- Chapter
- Export citation
Optimizing radiation patterns of mechanically reconfigurable phased arrays using flexible meta-gaps
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 16 / Issue 5 / June 2024
- Published online by Cambridge University Press:
- 02 January 2025, pp. 838-851
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - Entropy
- from Part I - Information Measures
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 7-18
-
- Chapter
- Export citation
2 - Divergence
- from Part I - Information Measures
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 19-40
-
- Chapter
- Export citation
Exercises for Part IV
- from Part IV - Channel Coding
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 471-484
-
- Chapter
- Export citation
Multi-parametric characterization of proton bunches above 50 MeV generated by helical coil targets
-
- Journal:
- High Power Laser Science and Engineering / Volume 12 / 2024
- Published online by Cambridge University Press:
- 02 January 2025, e88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Tightly focused proton beams generated from helical coil targets have been shown to be highly collimated across small distances, and display characteristic spectral bunching. We show, for the first time, proton spectra from such targets at high resolution via a Thomson parabola spectrometer. The proton spectral peaks reach energies above 50 MeV, with cutoffs approaching 70 MeV and particle numbers greater than 10
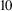 ${}^{10}$. The spectral bunch width has also been measured as low as approximately 8.5 MeV (17% energy spread). The proton beam pointing and divergence measured at metre-scale distances are found to be stable with the average pointing stability below 10 mrad, and average half-angle beam divergences of approximately 6 mrad. Evidence of the influence of the final turn of the coil on beam pointing over long distances is also presented, corroborated by particle tracing simulations, indicating the scope for further improvement and control of the beam pointing with modifying target parameters.
${}^{10}$. The spectral bunch width has also been measured as low as approximately 8.5 MeV (17% energy spread). The proton beam pointing and divergence measured at metre-scale distances are found to be stable with the average pointing stability below 10 mrad, and average half-angle beam divergences of approximately 6 mrad. Evidence of the influence of the final turn of the coil on beam pointing over long distances is also presented, corroborated by particle tracing simulations, indicating the scope for further improvement and control of the beam pointing with modifying target parameters.
13 - Universal Compression
- from Part II - Lossless Data Compression
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 245-266
-
- Chapter
- Export citation
15 - Information Projection and Large Deviations
- from Part III - Hypothesis Testing and Large Deviations
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 296-316
-
- Chapter
- Export citation
20 - Channels with Input Constraints and Gaussian Channels
- from Part IV - Channel Coding
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp 402-418
-
- Chapter
- Export citation
Dedication
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp v-vi
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Information Theory
- Published online:
- 09 January 2025
- Print publication:
- 02 January 2025, pp i-iv
-
- Chapter
- Export citation
NAV volume 78 issue 1 Cover and Front matter
-
- Journal:
- The Journal of Navigation / Volume 78 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 02 October 2025, pp. f1-f2
- Print publication:
- January 2025
-
- Article
-
- You have access
- Export citation
Adaptive robust trajectory tracking control with states-estimation for DJI-F450 quadrotor under multiple unknown disturbances
-
- Journal:
- The Journal of Navigation / Volume 78 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 30 June 2025, pp. 37-57
- Print publication:
- January 2025
-
- Article
- Export citation
Improving the assessment of slopes and flatness of the surfaces of runways and highway
-
- Journal:
- The Journal of Navigation / Volume 78 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 July 2025, pp. 80-100
- Print publication:
- January 2025
-
- Article
- Export citation
Flight test assessment of L1 and dual-frequency multi-constellation SBAS for civil aviation in Australia
-
- Journal:
- The Journal of Navigation / Volume 78 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 02 October 2025, pp. 123-148
- Print publication:
- January 2025
-
- Article
- Export citation
