Refine search
Actions for selected content:
101325 results in Language and Linguistics
World Languages*
-
- Article
- Export citation
Det isländska accenttecknet: En historisk-ortografisk studie. By Gustav Lindblad. (Lunds Universitets Årsskrift, NF, Avd. 1, Bd. 48, Nr. 1.) Pp. 230. Lund: C. W. K. Gleerup, 1952.
-
- Journal:
- Language / Volume 30 / Issue 1-Part1 / March 1954
- Published online by Cambridge University Press:
- 22 April 2026, pp. 166-167
-
- Article
- Export citation
Simplified Czechoslovak Grammar and Conversation Book. Pp. 320. By O. Štěpánek. Omaha: The Czech Historical Society of Nebraska, 1930.
-
- Journal:
- Language / Volume 9 / Issue 1-Part1 / March 1933
- Published online by Cambridge University Press:
- 22 April 2026, p. 99
-
- Article
- Export citation
The Vedic imperatives in -si
-
- Article
- Export citation
-
Within the Vedic verbal system there is a series of second singular forms made by suffixing -si to the full-grade root, which differ from the present type ási ‘thou art’ in that they function primarily as imperatives; e.g. yákṣi ‘sacrifice’. This archaic formation is found frequently in the Rigveda, where approximately 150 forms occur from 23 roots (§2); in other Vedic texts -si imperatives occur only for roots which have such forms in the Rigveda and predominantly in Rigvedic mantras; e.g.
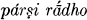 maghónām ‘bring safely across the gift-giving of the patrons’ (RV 8.103.7, 9.1.3);
maghónām ‘bring safely across the gift-giving of the patrons’ (RV 8.103.7, 9.1.3); 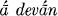 vakṣi yákṣi ca ‘bring the gods and sacrifice’ (.5.21.6, 6.16.2, 8.102.16); see Bloomfield, Concordance sv. párṣi,
vakṣi yákṣi ca ‘bring the gods and sacrifice’ (.5.21.6, 6.16.2, 8.102.16); see Bloomfield, Concordance sv. párṣi, 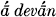 .
.
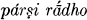
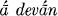 vakṣi yákṣi ca
vakṣi yákṣi ca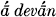 .
.A Grammar of Lakota, the language of the Teton Sioux Indians. By Eugene Buechel, S.J. Pp. [x] + 372. Saint Francis, S. D.: Saint Francis Mission, 1939. - The Kalispel language: an outline of the grammar with texts, translations, and dictionary. By Hans Vogt. (Det Norske Videnskaps-Akademi i Oslo.) Pp. 178. Oslo: Jacob Dybwad, 1940.
-
- Journal:
- Language / Volume 18 / Issue 1-Part1 / March 1942
- Published online by Cambridge University Press:
- 22 April 2026, pp. 69-73
-
- Article
- Export citation
Aufgaben und Methoden der modernen vulgärlateinisichen Forschung. By Helmut Schmeck. Pp. 34. Heidelberg: Carl Winter, Universitätsverlag, 1955.
-
- Journal:
- Language / Volume 32 / Issue 2-Part1 / June 1956
- Published online by Cambridge University Press:
- 22 April 2026, pp. 330-331
-
- Article
- Export citation
LAN volume 1 Issue 3-Part2 Cover and Front matter
-
- Journal:
- Language / Volume 1 / Issue 3-Part2 / November 1925
- Published online by Cambridge University Press:
- 22 April 2026, pp. f1-f7
-
- Article
-
- You have access
- Export citation
Books Received
-
- Journal:
- Language / Volume 12 / Issue 1-Part1 / March 1936
- Published online by Cambridge University Press:
- 22 April 2026, pp. 85-88
-
- Article
- Export citation
Statistics, Indo-European, and Taxonomy
-
- Journal:
- Language / Volume 36 / Issue 1-Part1 / March 1960
- Published online by Cambridge University Press:
- 22 April 2026, pp. 1-21
-
- Article
- Export citation
