Refine search
Actions for selected content:
101325 results in Language and Linguistics
The Uses of the Present Tense Forms in English
-
- Journal:
- Language / Volume 22 / Issue 4-Part1 / December 1946
- Published online by Cambridge University Press:
- 22 April 2026, pp. 317-325
-
- Article
- Export citation
LAN volume 38 issue 1 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Psilosis Again
-
- Article
- Export citation
Pidgin and creole languages. By Robert A. HallJr. Pp. xv, 188. Ithaca, New York: Cornell University Press, 1966. $7.50.
-
- Journal:
- Language / Volume 43 / Issue 3-Part1 / September 1967
- Published online by Cambridge University Press:
- 22 April 2026, pp. 817-824
-
- Article
- Export citation
LAN volume 14 issue 2-Part2 Cover and Front matter
-
- Journal:
- Language / Volume 14 / Issue 2-Part2 / June 1938
- Published online by Cambridge University Press:
- 22 April 2026, pp. f1-f9
-
- Article
-
- You have access
- Export citation
A Dravidian etymological dictionary. By T. Burrow and M. B. Emeneau. Pp. xxix, 609. Oxford: At the Clarendon Press, 1961.
-
- Journal:
- Language / Volume 39 / Issue 3-Part1 / September 1963
- Published online by Cambridge University Press:
- 22 April 2026, pp. 556-564
-
- Article
- Export citation
Germanic Influence on Old French Syntax
-
- Journal:
- Language / Volume 9 / Issue 2-Part1 / June 1933
- Published online by Cambridge University Press:
- 22 April 2026, pp. 162-170
-
- Article
- Export citation
Latin uncia
-
- Article
- Export citation
-
On the basis of Varro's etymology ‘uncia ab uno’ (LL 5.171), it has been said that Lat. uncia ‘
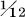 of anything, esp. as a weight (
of anything, esp. as a weight (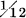 of a pound) and monetary unit (
of a pound) and monetary unit (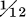 of an as)‘ represents an earlier *oiniciā. There are two possibilities of development: *oiniciā > *ōnciā > *ŏnciā > uncia, or *oiniciā > *ūnciā > uncia. The first requires a change known only in nōn < noenum (provided this etymology of nōn is accepted) and three regular changes—syncope, shortening of a long vowel before nasal plus consonant, and ŏ > ŭ before /η/. The second is not debatable, for oi > ū and shortening of the long vowel are both regular; given the etymon, therefore, it is the preferable development.
of an as)‘ represents an earlier *oiniciā. There are two possibilities of development: *oiniciā > *ōnciā > *ŏnciā > uncia, or *oiniciā > *ūnciā > uncia. The first requires a change known only in nōn < noenum (provided this etymology of nōn is accepted) and three regular changes—syncope, shortening of a long vowel before nasal plus consonant, and ŏ > ŭ before /η/. The second is not debatable, for oi > ū and shortening of the long vowel are both regular; given the etymon, therefore, it is the preferable development.
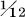 of anything, esp. as a weight (
of anything, esp. as a weight (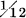 of a pound) and monetary unit (
of a pound) and monetary unit (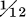 of an as)‘ represents an earlier
of an as)‘ represents an earlier Non-Initial k in the North of England
-
- Journal:
- Language / Volume 23 / Issue 1-Part1 / March 1947
- Published online by Cambridge University Press:
- 22 April 2026, pp. 43-49
-
- Article
- Export citation
Oneida verb morphology. By Floyd G. Lounsbury. (Yale University publications in anthropology, No. 48.) Pp. 111. New Haven: Yale University Press, 1953.
-
- Journal:
- Language / Volume 30 / Issue 1-Part1 / March 1954
- Published online by Cambridge University Press:
- 22 April 2026, pp. 182-185
-
- Article
- Export citation
List of Members 1953
-
- Journal:
- Language / Volume 30 / Issue 2-Part2 / June 1954
- Published online by Cambridge University Press:
- 22 April 2026, pp. 21-70
-
- Article
- Export citation
For Publications of the Linguistic Society of America
-
- Journal:
- Language / Volume 44 / Issue 2-Part2 / June 1968
- Published online by Cambridge University Press:
- 22 April 2026, pp. 1-5
-
- Article
- Export citation
A Greek-English Lexicon compiled by Henry George Liddell and Robert Scott. A new edition revised and augmented throughout by Henry Stuart Jones with the assistance of Roderick McKenzie and with the co-operation of many scholars. Part 1: A-’Aπoβaívω. Oxford: the Clarendon Press (Oxford University Press, American Branch) 1925.
-
- Article
- Export citation
