Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
Reconstruction of polytopes by convex pastings
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 9-18
- Print publication:
- December 2000
-
- Article
- Export citation
-
Consider a convex polytope X and a family
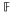 of convex sets, satisfying a given property P. Moreover, assume that is closed under operations of cutting and convex pasting along hyperplanes. Necessary and sufficient conditions are given to have
of convex sets, satisfying a given property P. Moreover, assume that is closed under operations of cutting and convex pasting along hyperplanes. Necessary and sufficient conditions are given to have 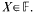 . As a consequence, it follows that, if all simplices or small enough simplices have the property in question, then X also has that property.
. As a consequence, it follows that, if all simplices or small enough simplices have the property in question, then X also has that property.
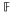 of convex sets, satisfying a given property P. Moreover, assume that
of convex sets, satisfying a given property P. Moreover, assume that 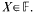 . As a consequence, it follows that, if all simplices or small enough simplices have the property in question, then
. As a consequence, it follows that, if all simplices or small enough simplices have the property in question, then Scattering of tidal waves by reefs and spits
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 355-370
- Print publication:
- December 2000
-
- Article
- Export citation
Maximal sections and centrally symmetric bodies
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 19-30
- Print publication:
- December 2000
-
- Article
- Export citation
Inscribing cubes and covering by rhombic dodecahedra via equivariant topology
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 371-397
- Print publication:
- December 2000
-
- Article
- Export citation
Combinatorics and linear algebra of Freiman's isomorphism
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 39-51
- Print publication:
- December 2000
-
- Article
- Export citation
-
An original linear algebraic approach to the basic notion of Freiman's isomorphism is developed and used in conjunction with a combinatorial argument to answer two questions, posed by Freiman about 35 years ago.
First, the order of growth is established of t(n), the number of classes isomorphic n-element sets of integers: t(n) = n(2 + σ(1))n. Second, it is proved linear Roth sets (sets of integers free of arithmetic progressions and having Freiman rank 1) exist and, moreover, the number
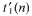 of classes of such cardinality n is amazingly large; in fact, it is “the same as above”:
of classes of such cardinality n is amazingly large; in fact, it is “the same as above”: 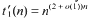 .
.
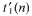 of classes of such cardinality
of classes of such cardinality 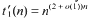 .
.Lusternik-Schnirelmann category and Morse decompositions
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 299-305
- Print publication:
- December 2000
-
- Article
- Export citation
Frequency of oscillations of an error term related to the Euler function
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 161-164
- Print publication:
- December 2000
-
- Article
- Export citation
-
Let φ be the Euler function, and consider the error term H in the asymptotic formula
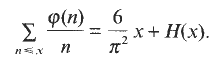
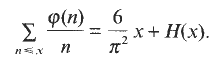
A functional analytic interpretation of the number of faces of a polyhedron
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 1-7
- Print publication:
- December 2000
-
- Article
- Export citation
-
Let P⊂ℝ2 be a polyhedron, that is, the intersection of a finite number of closed half-spaces, and suppose that its characteristic function lP can be expressed as a linear combination
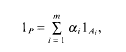
where each Ai is a relatively open and convex set. Let n(P) be the number of all non-empty facets of P. One of the main objectives of this paper is to show that

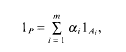

Factorization over local fields and the irreducibility of generalized difference polynomials
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 173-196
- Print publication:
- December 2000
-
- Article
- Export citation
Un nouveau critère pour l'équation de Catalan
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 63-73
- Print publication:
- December 2000
-
- Article
- Export citation
-
A new criterion on Catalan's equation is proved by elementary means

This shows, without appealing either to the theory of linear forms in logarithms, or to any computation, that (C) has no solution (x, y, p, q) with min {p, q}≤41, except (3,2, 2, 3).

The discrete fractional Fourier transform and Harper's equation
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 281-297
- Print publication:
- December 2000
-
- Article
- Export citation
Bounds for the points of spectral concentration of Sturm–Liouville problems
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 327-337
- Print publication:
- December 2000
-
- Article
- Export citation
-
§1. Introduction. We consider the spectral function ρα(λ) associated with the Sturm–Liouville equation
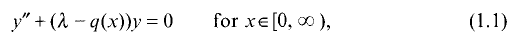
with the boundary condition
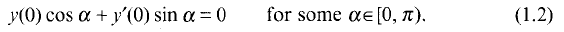
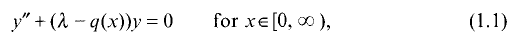
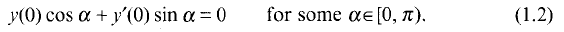
The convexity of the spectral function in Sturm–Liouville problems
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 319-326
- Print publication:
- December 2000
-
- Article
- Export citation
-
§1. Introduction. The spectral function ρα(μ) (−∞<μ<∞) associated with the Sturm–Liouville equation
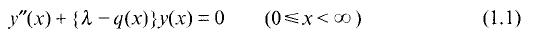
and a boundary condition
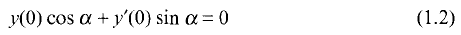
is a non-decreasing function of μ which is defined in terms of the Titchmarsh–Weyl function mα(λ) for (1.1) and (1.2).
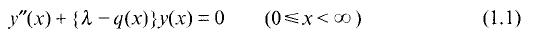
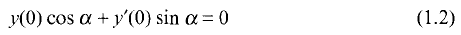
N-fold sums of Cantor sets
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 243-250
- Print publication:
- December 2000
-
- Article
- Export citation
Character sums with exponential functions
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 75-85
- Print publication:
- December 2000
-
- Article
- Export citation
-
Let ϑ be an integer of multiplicative order t≥1 modulo a prime p. Sums of the form
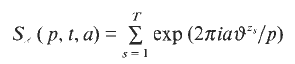
are introduced and estimated, with
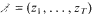 a sequence such that kz1, …, kzT is a permutation of z1, …, zT, both sequences taken modulo t, for sufficiently many distinct modulo t values of k. Such sequences include
a sequence such that kz1, …, kzT is a permutation of z1, …, zT, both sequences taken modulo t, for sufficiently many distinct modulo t values of k. Such sequences includexn for x = 1 ,…,t with an integer n≥1;
xn for x = 1 ,…,t and gcd (x, t) = 1 with an integer n≥1;
ex for x = 1 ,…,T with an integer e, where T is the period of the sequence ex modulo t.
Some of the results can be extended to composite moduli and to sums of multiplicative characters as well. Character sums with the above sequences have some cryptographic motivation and applications and have been considered in several papers by J. B. Friedlander, D. Lieman and I. E. Shparlinski. In particular several previous bounds are generalized and improved.
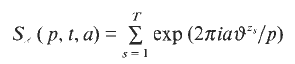
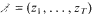 a sequence such that
a sequence such that The order of inverses mod q
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 87-108
- Print publication:
- December 2000
-
- Article
- Export citation
-
Let q be a prime number and let a = (a1, …, as) be an s-tuple of distinct integers modulo q. For any x coprime with q, let
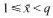 be such that
be such that 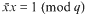 . For fixed s and q→∞ an asymptotic formula is given for the number of residue classes x modulo q for which
. For fixed s and q→∞ an asymptotic formula is given for the number of residue classes x modulo q for which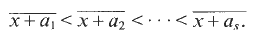
The more general case, when q is not necessarily prime and x is restricted to lie in a given subinterval of [1, q], is also treated.
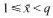 be such that
be such that 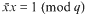 . For fixed
. For fixed 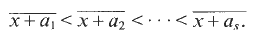
Index to volume 47
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 411-412
- Print publication:
- December 2000
-
- Article
- Export citation
The order of groups satisfying a converse to Lagrange's theorem
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 197-204
- Print publication:
- December 2000
-
- Article
- Export citation
On properties of metrizable spaces X preserved by t-equivalence
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 273-279
- Print publication:
- December 2000
-
- Article
- Export citation
Density and covering properties of intervals of ℝn
- Part of
-
- Journal:
- Mathematika / Volume 47 / Issue 1-2 / December 2000
- Published online by Cambridge University Press:
- 26 February 2010, pp. 229-242
- Print publication:
- December 2000
-
- Article
- Export citation
-
The key result of this paper proves the existence of functions ρn(h) for which, whenever H is a (Lebesgue) measurable subset of the n-dimensional unit cube In with measure |H| > h and ℛ is a class of subintervals (n-dimensional axis-parallel rectangles) of In that covers H, then there exists an interval R∈ℛ in which the density of H is greater than ρn(h); that is, |H∩R|/|R|>ρn (h) (=(h/2n)2). It is shown how to use this result to find 4 points of a measurable subset of the unit square which are the vertices of an axis-parallel rectangle that has quite large intersection with the original set. Density and covering properties of classes of subsets of ℝn are introduced and investigated. As a consequence, a covering property of the class of intervals of ℝn is obtained: if ℛ is a family of n-dimensional intervals with
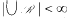 , then there is a finite sequence R1, …, Rm∈ℛ such that
, then there is a finite sequence R1, …, Rm∈ℛ such that 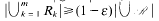 and
and 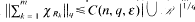 .
.
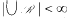 , then there is a finite sequence
, then there is a finite sequence 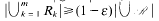 and
and 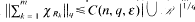 .
.