Refine listing
Actions for selected content:
15 results in 65Jxx
Instability in deep learning – when algorithms cannot compute uncertainty quantifications for neural networks
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 37 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 20 November 2025, pp. 290-312
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In deep learning, interval neural networks are used to quantify the uncertainty of a pre-trained neural network. Suppose we are given a computational problem
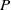 $P$ and a pre-trained neural network
$P$ and a pre-trained neural network 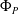 $\Phi _P$ that aims to solve
$\Phi _P$ that aims to solve 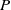 $P$. An interval neural network is then a pair of neural networks
$P$. An interval neural network is then a pair of neural networks 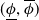 $(\underline {\phi }, \overline {\phi })$, with the property that
$(\underline {\phi }, \overline {\phi })$, with the property that 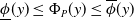 $\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs
$\underline {\phi }(y) \leq \Phi _P(y) \leq \overline {\phi }(y)$ for all inputs 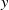 $y$, where the inequalities are meant componentwise.
$y$, where the inequalities are meant componentwise. 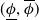 $(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of
$(\underline {\phi }, \overline {\phi })$ are specifically trained to quantify the uncertainty of 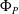 $\Phi _P$, in the sense that the size of the interval
$\Phi _P$, in the sense that the size of the interval 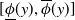 $[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction
$[\underline {\phi }(y),\overline {\phi }(y)]$ quantifies the uncertainty of the prediction 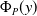 $\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network
$\Phi _P(y)$. In this paper, we investigate the phenomenon when algorithms cannot compute interval neural networks in the setting of inverse problems. We show that in the typical setting of a linear inverse problem, the problem of constructing an optimal pair of interval neural networks is non-computable, even with the assumption that the pre-trained neural network 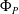 $\Phi _P$ is an optimal solution. In other words, there exist classes of training sets
$\Phi _P$ is an optimal solution. In other words, there exist classes of training sets  $\Omega$, such that there is no algorithm, even randomised (with probability
$\Omega$, such that there is no algorithm, even randomised (with probability 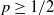 $p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set
$p \geq 1/2$), that computes an optimal pair of interval neural networks for each training set 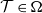 ${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network
${\mathcal{T}} \in \Omega$. This phenomenon happens even when we are given a pre-trained neural network 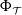 $\Phi _{{\mathcal{T}}}$ that is optimal for
$\Phi _{{\mathcal{T}}}$ that is optimal for 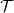 $\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
$\mathcal{T}$. This phenomenon is intimately linked to instability in deep learning.
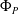
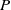
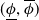
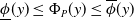
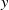
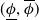
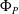
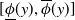
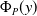
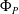

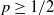
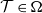
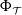
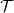
Low-rank tensor methods for partial differential equations
- Part of
-
- Journal:
- Acta Numerica / Volume 32 / May 2023
- Published online by Cambridge University Press:
- 11 May 2023, pp. 1-121
-
- Article
-
- You have access
- Open access
- Export citation
Perturbation Analysis of Orthogonal Least Squares
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 62 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 22 March 2019, pp. 780-797
- Print publication:
- December 2019
-
- Article
-
- You have access
- Export citation
-
The Orthogonal Least Squares (OLS) algorithm is an efficient sparse recovery algorithm that has received much attention in recent years. On one hand, this paper considers that the OLS algorithm recovers the supports of sparse signals in the noisy case. We show that the OLS algorithm exactly recovers the support of
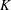 $K$-sparse signal
$K$-sparse signal  $\boldsymbol{x}$ from
$\boldsymbol{x}$ from 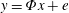 $\boldsymbol{y}=\boldsymbol{\unicode[STIX]{x1D6F7}}\boldsymbol{x}+\boldsymbol{e}$ in
$\boldsymbol{y}=\boldsymbol{\unicode[STIX]{x1D6F7}}\boldsymbol{x}+\boldsymbol{e}$ in 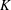 $K$ iterations, provided that the sensing matrix
$K$ iterations, provided that the sensing matrix 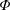 $\boldsymbol{\unicode[STIX]{x1D6F7}}$ satisfies the restricted isometry property (RIP) with restricted isometry constant (RIC)
$\boldsymbol{\unicode[STIX]{x1D6F7}}$ satisfies the restricted isometry property (RIP) with restricted isometry constant (RIC) 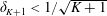 $\unicode[STIX]{x1D6FF}_{K+1}<1/\sqrt{K+1}$, and the minimum magnitude of the nonzero elements of
$\unicode[STIX]{x1D6FF}_{K+1}<1/\sqrt{K+1}$, and the minimum magnitude of the nonzero elements of  $\boldsymbol{x}$ satisfies some constraint. On the other hand, this paper demonstrates that the OLS algorithm exactly recovers the support of the best
$\boldsymbol{x}$ satisfies some constraint. On the other hand, this paper demonstrates that the OLS algorithm exactly recovers the support of the best  $K$-term approximation of an almost sparse signal
$K$-term approximation of an almost sparse signal  $\boldsymbol{x}$ in the general perturbations case, which means both
$\boldsymbol{x}$ in the general perturbations case, which means both 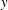 $\boldsymbol{y}$ and
$\boldsymbol{y}$ and 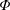 $\boldsymbol{\unicode[STIX]{x1D6F7}}$ are perturbed. We show that the support of the best
$\boldsymbol{\unicode[STIX]{x1D6F7}}$ are perturbed. We show that the support of the best 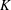 $K$-term approximation of
$K$-term approximation of  $\boldsymbol{x}$ can be recovered under reasonable conditions based on the restricted isometry property (RIP).
$\boldsymbol{x}$ can be recovered under reasonable conditions based on the restricted isometry property (RIP).

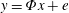
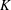
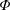
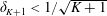

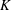

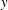
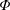
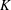

Minimal convex extensions and finite difference discretisation of the quadratic Monge–Kantorovich problem
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 30 / Issue 6 / December 2019
- Published online by Cambridge University Press:
- 21 September 2018, pp. 1041-1078
-
- Article
- Export citation
Forward-reverse expectation-maximization algorithm for Markov chains: convergence and numerical analysis
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 50 / Issue 2 / June 2018
- Published online by Cambridge University Press:
- 26 July 2018, pp. 621-644
- Print publication:
- June 2018
-
- Article
- Export citation
Hybrid Variational Model for Texture Image Restoration
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 07 September 2017, pp. 629-642
- Print publication:
- August 2017
-
- Article
- Export citation
Exponentially accurate Hamiltonian embeddings of symplectic A-stable Runge–Kutta methods for Hamiltonian semilinear evolution equations
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 146 / Issue 6 / December 2016
- Published online by Cambridge University Press:
- 25 October 2016, pp. 1265-1301
- Print publication:
- December 2016
-
- Article
- Export citation
Two-Stage Image Segmentation Scheme Based on Inexact Alternating Direction Method
- Part of
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 9 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 451-469
- Print publication:
- August 2016
-
- Article
- Export citation
A Full Space-Time Convergence Order Analysis of Operator Splittings for Linear Dissipative Evolution Equations
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 19 / Issue 5 / May 2016
- Published online by Cambridge University Press:
- 17 May 2016, pp. 1302-1316
- Print publication:
- May 2016
-
- Article
- Export citation
An Inverse Diffraction Problem: Shape Reconstruction
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 5 / Issue 4 / November 2015
- Published online by Cambridge University Press:
- 10 November 2015, pp. 342-360
- Print publication:
- November 2015
-
- Article
- Export citation
A NOTE ON THE SEMILOCAL CONVERGENCE OF CHEBYSHEV’S METHOD
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 88 / Issue 1 / August 2013
- Published online by Cambridge University Press:
- 15 October 2012, pp. 98-105
- Print publication:
- August 2013
-
- Article
-
- You have access
- Export citation
ITERATED LAVRENTIEV REGULARIZATION FOR NONLINEAR ILL-POSED PROBLEMS
- Part of
-
- Journal:
- The ANZIAM Journal / Volume 51 / Issue 2 / October 2009
- Published online by Cambridge University Press:
- 19 April 2010, pp. 191-217
-
- Article
-
- You have access
- Export citation
-
We consider an iterated form of Lavrentiev regularization, using a null sequence (αk) of positive real numbers to obtain a stable approximate solution for ill-posed nonlinear equations of the form F(x)=y, where F:D(F)⊆X→X is a nonlinear operator and X is a Hilbert space. Recently, Bakushinsky and Smirnova [“Iterative regularization and generalized discrepancy principle for monotone operator equations”, Numer. Funct. Anal. Optim.28 (2007) 13–25] considered an a posteriori strategy to find a stopping index kδ corresponding to inexact data yδ with
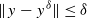 resulting in the convergence of the method as δ→0. However, they provided no error estimates. We consider an alternate strategy to find a stopping index which not only leads to the convergence of the method, but also provides an order optimal error estimate under a general source condition. Moreover, the condition that we impose on (αk) is weaker than that considered by Bakushinsky and Smirnova.
resulting in the convergence of the method as δ→0. However, they provided no error estimates. We consider an alternate strategy to find a stopping index which not only leads to the convergence of the method, but also provides an order optimal error estimate under a general source condition. Moreover, the condition that we impose on (αk) is weaker than that considered by Bakushinsky and Smirnova.
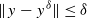 resulting in the convergence of the method as
resulting in the convergence of the method as Stable perturbation in Banach algebras
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 83 / Issue 2 / October 2007
- Published online by Cambridge University Press:
- 09 April 2009, pp. 271-284
-
- Article
-
- You have access
- Export citation
-
Let
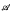 be a unital Banach algebra. Assume that a has a generalized inverse a+. Then
be a unital Banach algebra. Assume that a has a generalized inverse a+. Then 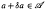 is said to be a stable perturbation of a if
is said to be a stable perturbation of a if 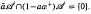 . In this paper we give various conditions for stable perturbation of a generalized invertible element and show that the equation is closely related to the gap function
. In this paper we give various conditions for stable perturbation of a generalized invertible element and show that the equation is closely related to the gap function 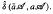 . These results will be applied to error estimates for perturbations of the Moore-Penrose inverse in C*–algebras and the Drazin inverse in Banach algebras.
. These results will be applied to error estimates for perturbations of the Moore-Penrose inverse in C*–algebras and the Drazin inverse in Banach algebras.
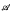 be a unital Banach algebra. Assume that a has
be a unital Banach algebra. Assume that a has 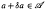 is said to be a stable perturbation of a if
is said to be a stable perturbation of a if 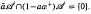 . In this paper we give various conditions for stable perturbation of a generalized invertible element and show that the equation
. In this paper we give various conditions for stable perturbation of a generalized invertible element and show that the equation 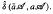 . These results will be applied to error estimates for perturbations of the Moore-Penrose inverse in C*–algebras and the Drazin inverse in Banach algebras.
. These results will be applied to error estimates for perturbations of the Moore-Penrose inverse in C*–algebras and the Drazin inverse in Banach algebras.The saturation phenomena for Tikhonov regularization
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society. Series A. Pure Mathematics and Statistics / Volume 35 / Issue 2 / October 1983
- Published online by Cambridge University Press:
- 09 April 2009, pp. 254-262
-
- Article
-
- You have access
- Export citation
ON MOROZOV’S DISCREPANCY PRINCIPLE FOR NONLINEAR ILL-POSED EQUATIONS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 79 / Issue 2 / April 2009
- Published online by Cambridge University Press:
- 13 March 2009, pp. 337-342
- Print publication:
- April 2009
-
- Article
-
- You have access
- Export citation
