Refine listing
Actions for selected content:
26 results in 65Yxx
Time parallelization for hyperbolic and parabolic problems
- Part of
-
- Journal:
- Acta Numerica / Volume 34 / July 2025
- Published online by Cambridge University Press:
- 01 July 2025, pp. 385-489
-
- Article
-
- You have access
- Open access
- Export citation
MONTE CARLO VARIANCE REDUCTION METHODS WITH APPLICATIONS IN STRUCTURAL RELIABILITY ANALYSIS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 31 August 2023, pp. 518-521
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Floating-point arithmetic
- Part of
-
- Journal:
- Acta Numerica / Volume 32 / May 2023
- Published online by Cambridge University Press:
- 11 May 2023, pp. 203-290
-
- Article
-
- You have access
- Open access
- Export citation
Low-rank tensor methods for partial differential equations
- Part of
-
- Journal:
- Acta Numerica / Volume 32 / May 2023
- Published online by Cambridge University Press:
- 11 May 2023, pp. 1-121
-
- Article
-
- You have access
- Open access
- Export citation
Rigid continuation paths II. structured polynomial systems
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 14 April 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies the average complexity of solving structured polynomial systems that are characterised by a low evaluation cost, as opposed to the dense random model previously used. Firstly, we design a continuation algorithm that computes, with high probability, an approximate zero of a polynomial system given only as black-box evaluation program. Secondly, we introduce a universal model of random polynomial systems with prescribed evaluation complexity L. Combining both, we show that we can compute an approximate zero of a random structured polynomial system with n equations of degree at most
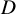 ${D}$ in n variables with only
${D}$ in n variables with only 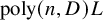 $\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
$\operatorname {poly}(n, {D}) L$ operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
Functional norms, condition numbers and numerical algorithms in algebraic geometry
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 22 November 2022, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In numerical linear algebra, a well-established practice is to choose a norm that exploits the structure of the problem at hand to optimise accuracy or computational complexity. In numerical polynomial algebra, a single norm (attributed to Weyl) dominates the literature. This article initiates the use of
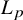 $L_p$ norms for numerical algebraic geometry, with an emphasis on
$L_p$ norms for numerical algebraic geometry, with an emphasis on 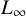 $L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing
$L_{\infty }$. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing 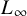 $L_{\infty }$-norm, the use of
$L_{\infty }$-norm, the use of 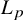 $L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
$L_p$-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
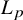
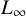
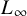
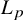
JASMIN-based Two-dimensional Adaptive Combined Preconditioner for Radiation Diffusion Equations in Inertial Fusion Research
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 07 September 2017, pp. 495-507
- Print publication:
- August 2017
-
- Article
- Export citation
-
We present a JASMIN-based two-dimensional parallel implementation of an adaptive combined preconditioner
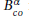 for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel -GMRES solver with the help of the default BoomerAMG in the HYPRE library. Numerical results demonstrate that our proposed parallel incomplete LU preconditioner (ILU) is of higher efficiency than the counterpart in the Euclid library, and that the proposed parallel -GMRES solver is more robust and more efficient than the default BoomerAMG-GMRES solver.
for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel -GMRES solver with the help of the default BoomerAMG in the HYPRE library. Numerical results demonstrate that our proposed parallel incomplete LU preconditioner (ILU) is of higher efficiency than the counterpart in the Euclid library, and that the proposed parallel -GMRES solver is more robust and more efficient than the default BoomerAMG-GMRES solver.
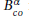 for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel
for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel GPU-Accelerated LOBPCG Method with Inexact Null-Space Filtering for Solving Generalized Eigenvalue Problems in Computational Electromagnetics Analysis with Higher-Order FEM
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 22 / Issue 4 / October 2017
- Published online by Cambridge University Press:
- 28 July 2017, pp. 997-1014
- Print publication:
- October 2017
-
- Article
- Export citation
Exponential Time Differencing Gauge Method for Incompressible Viscous Flows
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 22 / Issue 2 / August 2017
- Published online by Cambridge University Press:
- 21 June 2017, pp. 517-541
- Print publication:
- August 2017
-
- Article
- Export citation
Numerical Effects of the Gaussian Recursive Filters in Solving Linear Systems in the 3Dvar Case Study
- Part of
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 10 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 20 June 2017, pp. 520-540
- Print publication:
- August 2017
-
- Article
- Export citation
Modulus-based Synchronous Multisplitting Iteration Methods for an Implicit Complementarity Problem
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 2 / May 2017
- Published online by Cambridge University Press:
- 02 May 2017, pp. 363-375
- Print publication:
- May 2017
-
- Article
- Export citation
Designing Several Types of Oscillation-Less and High-Resolution Hybrid Schemes on Block-Structured Grids
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 21 / Issue 5 / May 2017
- Published online by Cambridge University Press:
- 27 March 2017, pp. 1376-1407
- Print publication:
- May 2017
-
- Article
- Export citation
Simulation of Maxwell's Equations on GPU Using a High-Order Error-Minimized Scheme
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 21 / Issue 4 / April 2017
- Published online by Cambridge University Press:
- 08 March 2017, pp. 1039-1064
- Print publication:
- April 2017
-
- Article
- Export citation
Efficient and Stable Exponential Runge-Kutta Methods for Parabolic Equations
- Part of
-
- Journal:
- Advances in Applied Mathematics and Mechanics / Volume 9 / Issue 1 / February 2017
- Published online by Cambridge University Press:
- 11 October 2016, pp. 157-172
- Print publication:
- February 2017
-
- Article
- Export citation
Finite Element Algorithm for Dynamic Thermoelasticity Coupling Problems and Application to Transient Response of Structure with Strong Aerothermodynamic Environment
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 20 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 31 August 2016, pp. 773-810
- Print publication:
- September 2016
-
- Article
- Export citation
Parallel Solution of Linear Systems
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 6 / Issue 3 / August 2016
- Published online by Cambridge University Press:
- 20 July 2016, pp. 278-289
- Print publication:
- August 2016
-
- Article
- Export citation
Reduced Basis Approaches in Time-Dependent Non-Coercive Settings for Modelling the Movement of Nuclear Reactor Control Rods
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 20 / Issue 1 / July 2016
- Published online by Cambridge University Press:
- 22 June 2016, pp. 23-59
- Print publication:
- July 2016
-
- Article
- Export citation
Simulation of Flow in Multi-Scale Porous Media Using the Lattice Boltzmann Method on Quadtree Grids
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 19 / Issue 4 / April 2016
- Published online by Cambridge University Press:
- 12 April 2016, pp. 998-1014
- Print publication:
- April 2016
-
- Article
- Export citation
Automated Parallel and Body-Fitted Mesh Generation in Finite Element Simulation of Macromolecular Systems
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 19 / Issue 3 / March 2016
- Published online by Cambridge University Press:
- 16 March 2016, pp. 582-602
- Print publication:
- March 2016
-
- Article
- Export citation
High Order Numerical Methods for the Dynamic SGS Model of Turbulent Flows with Shocks
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 19 / Issue 2 / February 2016
- Published online by Cambridge University Press:
- 01 February 2016, pp. 273-300
- Print publication:
- February 2016
-
- Article
- Export citation
