Refine listing
Actions for selected content:
186 results in 62Pxx
The teaching of statistical consulting
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 20-26
- Print publication:
- 2001
-
- Article
- Export citation
Estimating interannual variability arising from weather events
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 274-288
- Print publication:
- 2001
-
- Article
- Export citation
A study of the role of the transmission mechanism in macroparasite aggregation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 249-262
- Print publication:
- 2001
-
- Article
- Export citation
Point process convergence of stochastic volatility processes with application to sample autocorrelation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 93-104
- Print publication:
- 2001
-
- Article
- Export citation
Martingales versus PDEs in finance: an equivalence result with examples
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 4 / December 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 947-957
- Print publication:
- December 2000
-
- Article
- Export citation
An insensitivity property of Lundberg's estimate for delayed claims
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 3 / September 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 914-917
- Print publication:
- September 2000
-
- Article
- Export citation
Recursive estimation of distributional fix-points
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 1 / March 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 73-87
- Print publication:
- March 2000
-
- Article
- Export citation
-
In various stochastic models the random equation
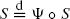 of implicit renewal theory appears where the real random variable S and the stochastic process Ψ with index space and state space R are independent. By use of stochastic approximation the distribution function of S is recursively estimated on the basis of independent or ergodic copies of Ψ. Under integrability assumptions almost sure L 1-convergence is proved. The choice of gains in the recursion is discussed. Applications are given to insurance mathematics (perpetuities) and queueing theory (stationary waiting and queueing times).
of implicit renewal theory appears where the real random variable S and the stochastic process Ψ with index space and state space R are independent. By use of stochastic approximation the distribution function of S is recursively estimated on the basis of independent or ergodic copies of Ψ. Under integrability assumptions almost sure L 1-convergence is proved. The choice of gains in the recursion is discussed. Applications are given to insurance mathematics (perpetuities) and queueing theory (stationary waiting and queueing times).
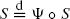 of implicit renewal theory appears where the real random variable
of implicit renewal theory appears where the real random variable Extensions of the bifurcating autoregressive model for cell lineage studies
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 4 / December 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1225-1233
- Print publication:
- December 1999
-
- Article
- Export citation
Modelling hierarchical systems by a continuous-time homogeneous Markov chain using two-wave panel data
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 3 / September 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 644-653
- Print publication:
- September 1999
-
- Article
- Export citation
-
An open hierarchical (manpower) system divided into a totally ordered set of k grades is discussed. The transitions occur only from one grade to the next or to an additional (k+1)th grade representing the external environment of the system. The model used to describe the dynamics of the system is a continuous-time homogeneous Markov chain with k+1 states and infinitesimal generator R = (r ij ) satisfying r ij = 0 if i > j or i + 1 < j ≤ k (i, j = 1,…,k+1), the transition matrix P between times 0 and 1 being P = expR . In this paper, two-wave panel data about the hierarchical system are considered and the resulting fact that, in general, the maximum-likelihood estimated transition matrix
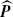 cannot be written as an exponential of an infinitesimal generator R having the form described above. The purpose of this paper is to investigate when this can be ascribed to the effect of sampling variability.
cannot be written as an exponential of an infinitesimal generator R having the form described above. The purpose of this paper is to investigate when this can be ascribed to the effect of sampling variability.
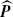 cannot be written as an exponential of an infinitesimal generator
cannot be written as an exponential of an infinitesimal generator Ornstein–Uhlenbeck type processes with non-normal distribution
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 2 / June 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 389-402
- Print publication:
- June 1999
-
- Article
- Export citation
Inequalities for the score constant in matching random sequences
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 2 / June 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 601-606
- Print publication:
- June 1999
-
- Article
- Export citation
Markov Chain Monte Carlo simulation of the distribution of some perpetuities
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 31 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 01 July 2016, pp. 112-134
- Print publication:
- March 1999
-
- Article
- Export citation
Bounds for the total variation distance between the binomial and the Poisson distribution in case of medium-sized success probabilities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 36 / Issue 1 / March 1999
- Published online by Cambridge University Press:
- 14 July 2016, pp. 97-104
- Print publication:
- March 1999
-
- Article
- Export citation
Estimation of the parameters of a branching process from migrating binomial observations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 30 / Issue 4 / December 1998
- Published online by Cambridge University Press:
- 01 July 2016, pp. 948-967
- Print publication:
- December 1998
-
- Article
- Export citation
Stochastic indicator analysis of contaminated sites
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 4 / December 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 988-1008
- Print publication:
- December 1997
-
- Article
- Export citation
A Stochastic Model of Carcinogenesis and Tumor Size at Detection
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 29 / Issue 3 / September 1997
- Published online by Cambridge University Press:
- 01 July 2016, pp. 607-628
- Print publication:
- September 1997
-
- Article
- Export citation
Large deviations of heavy-tailed random sums with applications in insurance and finance
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 2 / June 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 293-308
- Print publication:
- June 1997
-
- Article
- Export citation
-
We prove large deviation results for the random sum
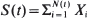 ,
, 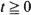 , where
, where 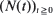 are non-negative integer-valued random variables and are
are non-negative integer-valued random variables and are 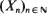 i.i.d. non-negative random variables with common distribution function F, independent of
i.i.d. non-negative random variables with common distribution function F, independent of 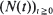 . Special attention is paid to the compound Poisson process and its ramifications. The right tail of the distribution function F is supposed to be of Pareto type (regularly or extended regularly varying). The large deviation results are applied to certain problems in insurance and finance which are related to large claims.
. Special attention is paid to the compound Poisson process and its ramifications. The right tail of the distribution function F is supposed to be of Pareto type (regularly or extended regularly varying). The large deviation results are applied to certain problems in insurance and finance which are related to large claims.
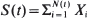 ,
, 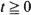 , where
, where 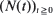 are non-negative integer-valued random variables and are
are non-negative integer-valued random variables and are 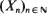 i.i.d. non-negative random variables with common distribution function
i.i.d. non-negative random variables with common distribution function 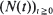 . Special attention is paid to the compound Poisson process and its ramifications. The right tail of the distribution function
. Special attention is paid to the compound Poisson process and its ramifications. The right tail of the distribution function Some majorization orderings of heterogeneity in a class of epidemics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 1 / March 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 84-93
- Print publication:
- March 1997
-
- Article
- Export citation
Confidence bounds for the adjustment coefficient
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 28 / Issue 3 / September 1996
- Published online by Cambridge University Press:
- 01 July 2016, pp. 802-827
- Print publication:
- September 1996
-
- Article
- Export citation
Randomized multihit models and their identification
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 2 / September 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 458-471
- Print publication:
- September 1996
-
- Article
- Export citation
