Refine search
Actions for selected content:
4250 results in Numerical analysis and computational science
ON THE TRUTH-CONVERGENCE OF OPEN-MINDED BAYESIANISM
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 February 2021, pp. 64-100
- Print publication:
- March 2022
-
- Article
-
- You have access
- Open access
- Export citation
GÖDEL ON MANY-VALUED LOGIC
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 22 February 2021, pp. 655-671
- Print publication:
- September 2023
-
- Article
- Export citation
THE SEMANTIC FOUNDATIONS OF PHILOSOPHICAL ANALYSIS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 22 February 2021, pp. 603-623
- Print publication:
- June 2023
-
- Article
- Export citation
WHAT IS A RULE OF INFERENCE?
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 21 December 2020, pp. 307-346
- Print publication:
- June 2021
-
- Article
- Export citation
-
We explore the problems that confront any attempt to explain or explicate exactly what a primitive logical rule of inference is, or consists in. We arrive at a proposed solution that places a surprisingly heavy load on the prospect of being able to understand and deal with specifications of rules that are essentially self-referring. That is, any rule
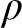 $\rho $ is to be understood via a specification that involves, embedded within it, reference to rule
$\rho $ is to be understood via a specification that involves, embedded within it, reference to rule 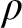 $\rho $ itself. Just how we arrive at this position is explained by reference to familiar rules as well as less familiar ones with unusual features. An inquiry of this kind is surprisingly absent from the foundations of inferentialism—the view that meanings of expressions (especially logical ones) are to be characterized by the rules of inference that govern them.
$\rho $ itself. Just how we arrive at this position is explained by reference to familiar rules as well as less familiar ones with unusual features. An inquiry of this kind is surprisingly absent from the foundations of inferentialism—the view that meanings of expressions (especially logical ones) are to be characterized by the rules of inference that govern them.
BINARY KRIPKE SEMANTICS FOR A STRONG LOGIC FOR NAIVE TRUTH
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 December 2020, pp. 668-692
- Print publication:
- September 2022
-
- Article
- Export citation
-
I show that the logic
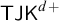 $\textsf {TJK}^{d+}$, one of the strongest logics currently known to support the naive theory of truth, is obtained from the Kripke semantics for constant domain intuitionistic logic by (i) dropping the requirement that the accessibility relation is reflexive and (ii) only allowing reflexive worlds to serve as counterexamples to logical consequence. In addition, I provide a simplified natural deduction system for
$\textsf {TJK}^{d+}$, one of the strongest logics currently known to support the naive theory of truth, is obtained from the Kripke semantics for constant domain intuitionistic logic by (i) dropping the requirement that the accessibility relation is reflexive and (ii) only allowing reflexive worlds to serve as counterexamples to logical consequence. In addition, I provide a simplified natural deduction system for  $\textsf {TJK}^{d+}$, in which a restricted form of conditional proof is used to establish conditionals.
$\textsf {TJK}^{d+}$, in which a restricted form of conditional proof is used to establish conditionals.

TWO ARGUMENTS AGAINST THE GENERIC MULTIVERSE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 02 December 2020, pp. 347-379
- Print publication:
- June 2021
-
- Article
- Export citation
Numerical methods for nonlocal and fractional models
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 1-124
-
- Article
- Export citation
ANU volume 29 Cover and Front matter
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. f1-f6
-
- Article
-
- You have access
- Export citation
The numerics of phase retrieval
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 125-228
-
- Article
- Export citation
Fast algorithms using orthogonal polynomials
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 573-699
-
- Article
- Export citation
Randomized numerical linear algebra: Foundations and algorithms
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 403-572
-
- Article
- Export citation
ANU volume 29 Cover and Back matter
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Essentially non-oscillatory and weighted essentially non-oscillatory schemes
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 701-762
-
- Article
- Export citation
Computing quantum dynamics in the semiclassical regime
-
- Journal:
- Acta Numerica / Volume 29 / May 2020
- Published online by Cambridge University Press:
- 30 November 2020, pp. 229-401
-
- Article
- Export citation
RSL volume 13 issue 4 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 20 November 2020, pp. b1-b2
- Print publication:
- December 2020
-
- Article
-
- You have access
- Export citation
RSL volume 13 issue 4 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 20 November 2020, pp. f1-f4
- Print publication:
- December 2020
-
- Article
-
- You have access
- Export citation
DOING WITHOUT ACTION TYPES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 380-410
- Print publication:
- June 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SUPPORT FOR GEOMETRIC POOLING
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 21 October 2020, pp. 298-337
- Print publication:
- March 2023
-
- Article
- Export citation
EXPLORING THE LANDSCAPE OF RELATIONAL SYLLOGISTIC LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 728-765
- Print publication:
- September 2021
-
- Article
- Export citation
SEMANTICS FOR PURE THEORIES OF CONNEXIVE IMPLICATION
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 591-606
- Print publication:
- September 2022
-
- Article
- Export citation
