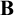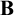Refine search
Actions for selected content:
4250 results in Numerical analysis and computational science
Deep learning: a statistical viewpoint
-
- Journal:
- Acta Numerica / Volume 30 / May 2021
- Published online by Cambridge University Press:
- 04 August 2021, pp. 87-201
-
- Article
-
- You have access
- Open access
- Export citation
Neural network approximation
-
- Journal:
- Acta Numerica / Volume 30 / May 2021
- Published online by Cambridge University Press:
- 04 August 2021, pp. 327-444
-
- Article
-
- You have access
- Open access
- Export citation
ANU volume 30 Cover and Back matter
-
- Journal:
- Acta Numerica / Volume 30 / May 2021
- Published online by Cambridge University Press:
- 04 August 2021, p. b1
-
- Article
-
- You have access
- Export citation
ANU volume 30 Cover and Front matter
-
- Journal:
- Acta Numerica / Volume 30 / May 2021
- Published online by Cambridge University Press:
- 04 August 2021, pp. f1-f6
-
- Article
-
- You have access
- Export citation
Numerical homogenization beyond scale separation
-
- Journal:
- Acta Numerica / Volume 30 / May 2021
- Published online by Cambridge University Press:
- 04 August 2021, pp. 1-86
-
- Article
-
- You have access
- Open access
- Export citation
CONDITIONAL LOGIC IS COMPLETE FOR CONVEXITY IN THE PLANE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 08 July 2021, pp. 529-552
- Print publication:
- June 2023
-
- Article
- Export citation
THREE MODEL-THEORETIC CONSTRUCTIONS FOR GENERALIZED EPSTEIN SEMANTICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 08 July 2021, pp. 1023-1032
- Print publication:
- December 2022
-
- Article
- Export citation
-
This paper introduces three model-theoretic constructions for generalized Epstein semantics: reducts, ultramodels and
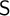 $\textsf {S}$-sets. We apply these notions to obtain metatheoretical results. We prove connective inexpressibility by means of a reduct, compactness by an ultramodel and definability theorem which states that a set of generalized Epstein models is definable iff it is closed under ultramodels and
$\textsf {S}$-sets. We apply these notions to obtain metatheoretical results. We prove connective inexpressibility by means of a reduct, compactness by an ultramodel and definability theorem which states that a set of generalized Epstein models is definable iff it is closed under ultramodels and 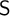 $\textsf {S}$-sets. Furthermore, a corollary concerning definability of a set of models by a single formula is given on the basis of the main theorem and the compactness theorem. We also provide an example of a natural set of generalized Epstein models which is undefinable. Its undefinability is proven by means of an
$\textsf {S}$-sets. Furthermore, a corollary concerning definability of a set of models by a single formula is given on the basis of the main theorem and the compactness theorem. We also provide an example of a natural set of generalized Epstein models which is undefinable. Its undefinability is proven by means of an 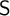 $\textsf {S}$-set.
$\textsf {S}$-set.
HIERARCHICAL INCOMPLETENESS RESULTS FOR ARITHMETICALLY DEFINABLE EXTENSIONS OF FRAGMENTS OF ARITHMETIC
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 02 July 2021, pp. 624-644
- Print publication:
- September 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
There has been a recent interest in hierarchical generalizations of classic incompleteness results. This paper provides evidence that such generalizations are readily obtainable from suitably formulated hierarchical versions of the principles used in the original proofs. By collecting such principles, we prove hierarchical versions of Mostowski’s theorem on independent formulae, Kripke’s theorem on flexible formulae, Woodin’s theorem on the universal algorithm, and a few related results. As a corollary, we obtain the expected result that the formula expressing “
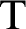 $\mathrm {T}$ is
$\mathrm {T}$ is 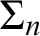 $\Sigma _n$-ill” is a canonical example of a
$\Sigma _n$-ill” is a canonical example of a 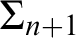 $\Sigma _{n+1}$ formula that is
$\Sigma _{n+1}$ formula that is 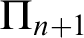 $\Pi _{n+1}$-conservative over
$\Pi _{n+1}$-conservative over 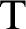 $\mathrm {T}$.
$\mathrm {T}$.
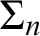
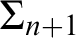
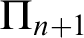
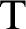
NEIGHBOURHOOD CANONICITY FOR EK, ECK, AND RELATIVES: A CONSTRUCTIVE PROOF
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 July 2021, pp. 607-623
- Print publication:
- September 2022
-
- Article
- Export citation
-
We prove neighbourhood canonicity and strong completeness for the logics
 $\mathbf {EK}$ and
$\mathbf {EK}$ and 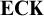 $\mathbf {ECK}$, obtained by adding axiom (K), resp. adding both (K) and (C), to the minimal modal logic
$\mathbf {ECK}$, obtained by adding axiom (K), resp. adding both (K) and (C), to the minimal modal logic 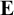 $\textbf {E}$. In contrast to an earlier proof in [10], ours is constructive. More precisely, we construct minimal characteristic models for both logics and do not rely on compactness of first order logic. The proof involves a specific circumscription technique and quite some set-theoretic maneuvers to establish that the models satisfy the appropriate frame conditions. After giving both proofs, we briefly spell out how they generalize to four stronger logics and to the extensions of the resulting six logics with a global modality.
$\textbf {E}$. In contrast to an earlier proof in [10], ours is constructive. More precisely, we construct minimal characteristic models for both logics and do not rely on compactness of first order logic. The proof involves a specific circumscription technique and quite some set-theoretic maneuvers to establish that the models satisfy the appropriate frame conditions. After giving both proofs, we briefly spell out how they generalize to four stronger logics and to the extensions of the resulting six logics with a global modality.

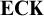
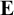
A CORRECTNESS PROOF FOR AL-BARAKĀT’S LOGICAL DIAGRAMS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 02 July 2021, pp. 369-384
- Print publication:
- June 2023
-
- Article
- Export citation
IMPROVING STRONG NEGATION
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 July 2021, pp. 951-977
- Print publication:
- September 2023
-
- Article
- Export citation
A MATHEMATICAL COMMITMENT WITHOUT COMPUTATIONAL STRENGTH
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 02 July 2021, pp. 880-906
- Print publication:
- December 2022
-
- Article
- Export citation
-
We present a new manifestation of Gödel’s second incompleteness theorem and discuss its foundational significance, in particular with respect to Hilbert’s program. Specifically, we consider a proper extension of Peano arithmetic (
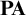 $\mathbf {PA}$) by a mathematically meaningful axiom scheme that consists of
$\mathbf {PA}$) by a mathematically meaningful axiom scheme that consists of 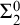 $\Sigma ^0_2$-sentences. These sentences assert that each computably enumerable (
$\Sigma ^0_2$-sentences. These sentences assert that each computably enumerable (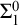 $\Sigma ^0_1$-definable without parameters) property of finite binary trees has a finite basis. Since this fact entails the existence of polynomial time algorithms, it is relevant for computer science. On a technical level, our axiom scheme is a variant of an independence result due to Harvey Friedman. At the same time, the meta-mathematical properties of our axiom scheme distinguish it from most known independence results: Due to its logical complexity, our axiom scheme does not add computational strength. The only known method to establish its independence relies on Gödel’s second incompleteness theorem. In contrast, Gödel’s theorem is not needed for typical examples of
$\Sigma ^0_1$-definable without parameters) property of finite binary trees has a finite basis. Since this fact entails the existence of polynomial time algorithms, it is relevant for computer science. On a technical level, our axiom scheme is a variant of an independence result due to Harvey Friedman. At the same time, the meta-mathematical properties of our axiom scheme distinguish it from most known independence results: Due to its logical complexity, our axiom scheme does not add computational strength. The only known method to establish its independence relies on Gödel’s second incompleteness theorem. In contrast, Gödel’s theorem is not needed for typical examples of 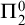 $\Pi ^0_2$-independence (such as the Paris–Harrington principle), since computational strength provides an extensional invariant on the level of
$\Pi ^0_2$-independence (such as the Paris–Harrington principle), since computational strength provides an extensional invariant on the level of 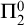 $\Pi ^0_2$-sentences.
$\Pi ^0_2$-sentences.
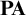
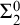
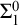
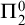
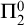
RUSSELLIAN DEFINITE DESCRIPTION THEORY—A PROOF THEORETIC APPROACH
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 02 July 2021, pp. 624-649
- Print publication:
- June 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SUBATOMIC INFERENCES: AN INFERENTIALIST SEMANTICS FOR ATOMICS, PREDICATES, AND NAMES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 02 July 2021, pp. 672-699
- Print publication:
- September 2023
-
- Article
- Export citation
INTERPRETATION, LOGIC AND PHILOSOPHY: JEAN NICOD’S GEOMETRY IN THE SENSIBLE WORLD
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 July 2021, pp. 1080-1109
- Print publication:
- December 2023
-
- Article
- Export citation
LOGICS OF FORMAL INCONSISTENCY ENRICHED WITH REPLACEMENT: AN ALGEBRAIC AND MODAL ACCOUNT
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 July 2021, pp. 771-806
- Print publication:
- September 2022
-
- Article
- Export citation
-
It is customary to expect from a logical system that it can be algebraizable, in the sense that an algebraic companion of the deductive machinery can always be found. Since the inception of da Costa’s paraconsistent calculi, algebraic equivalents for such systems have been sought. It is known, however, that these systems are not self-extensional (i.e., they do not satisfy the replacement property). More than this, they are not algebraizable in the sense of Blok–Pigozzi. The same negative results hold for several systems of the hierarchy of paraconsistent logics known as Logics of Formal Inconsistency (LFIs). Because of this, several systems belonging to this class of logics are only characterizable by semantics of a non-deterministic nature. This paper offers a solution for two open problems in the domain of paraconsistency, in particular connected to algebraization of LFIs, by extending with rules several LFIs weaker than
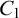 $C_1$, thus obtaining the replacement property (that is, such LFIs turn out to be self-extensional). Moreover, these logics become algebraizable in the standard Lindenbaum–Tarski’s sense by a suitable variety of Boolean algebras extended with additional operations. The weakest LFI satisfying replacement presented here is called RmbC, which is obtained from the basic LFI called mbC. Some axiomatic extensions of RmbC are also studied. In addition, a neighborhood semantics is defined for such systems. It is shown that RmbC can be defined within the minimal bimodal non-normal logic
$C_1$, thus obtaining the replacement property (that is, such LFIs turn out to be self-extensional). Moreover, these logics become algebraizable in the standard Lindenbaum–Tarski’s sense by a suitable variety of Boolean algebras extended with additional operations. The weakest LFI satisfying replacement presented here is called RmbC, which is obtained from the basic LFI called mbC. Some axiomatic extensions of RmbC are also studied. In addition, a neighborhood semantics is defined for such systems. It is shown that RmbC can be defined within the minimal bimodal non-normal logic  $\mathbf {E} {\oplus } \mathbf {E}$ defined by the fusion of the non-normal modal logic E with itself. Finally, the framework is extended to first-order languages. RQmbC, the quantified extension of RmbC, is shown to be sound and complete w.r.t. the proposed algebraic semantics.
$\mathbf {E} {\oplus } \mathbf {E}$ defined by the fusion of the non-normal modal logic E with itself. Finally, the framework is extended to first-order languages. RQmbC, the quantified extension of RmbC, is shown to be sound and complete w.r.t. the proposed algebraic semantics.

THE COPERNICAN MULTIVERSE OF SETS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 14 June 2021, pp. 1033-1069
- Print publication:
- December 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We develop an untyped framework for the multiverse of set theory.
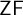 $\mathsf {ZF}$ is extended with semantically motivated axioms utilizing the new symbols
$\mathsf {ZF}$ is extended with semantically motivated axioms utilizing the new symbols 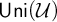 $\mathsf {Uni}(\mathcal {U})$ and
$\mathsf {Uni}(\mathcal {U})$ and 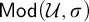 $\mathsf {Mod}(\mathcal {U, \sigma })$, expressing that
$\mathsf {Mod}(\mathcal {U, \sigma })$, expressing that 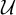 $\mathcal {U}$ is a universe and that
$\mathcal {U}$ is a universe and that 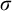 $\sigma $ is true in the universe
$\sigma $ is true in the universe 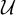 $\mathcal {U}$, respectively. Here
$\mathcal {U}$, respectively. Here 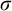 $\sigma $ ranges over the augmented language, leading to liar-style phenomena that are analyzed. The framework is both compatible with a broad range of multiverse conceptions and suggests its own philosophically and semantically motivated multiverse principles. In particular, the framework is closely linked with a deductive rule of Necessitation expressing that the multiverse theory can only prove statements that it also proves to hold in all universes. We argue that this may be philosophically thought of as a Copernican principle that the background theory does not hold a privileged position over the theories of its internal universes. Our main mathematical result is a lemma encapsulating a technique for locally interpreting a wide variety of extensions of our basic framework in more familiar theories. We apply this to show, for a range of such semantically motivated extensions, that their consistency strength is at most slightly above that of the base theory
$\sigma $ ranges over the augmented language, leading to liar-style phenomena that are analyzed. The framework is both compatible with a broad range of multiverse conceptions and suggests its own philosophically and semantically motivated multiverse principles. In particular, the framework is closely linked with a deductive rule of Necessitation expressing that the multiverse theory can only prove statements that it also proves to hold in all universes. We argue that this may be philosophically thought of as a Copernican principle that the background theory does not hold a privileged position over the theories of its internal universes. Our main mathematical result is a lemma encapsulating a technique for locally interpreting a wide variety of extensions of our basic framework in more familiar theories. We apply this to show, for a range of such semantically motivated extensions, that their consistency strength is at most slightly above that of the base theory 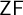 $\mathsf {ZF}$, and thus not seriously limiting to the diversity of the set-theoretic multiverse. We end with case studies applying the framework to two multiverse conceptions of set theory: arithmetic absoluteness and Joel D. Hamkins’ multiverse theory.
$\mathsf {ZF}$, and thus not seriously limiting to the diversity of the set-theoretic multiverse. We end with case studies applying the framework to two multiverse conceptions of set theory: arithmetic absoluteness and Joel D. Hamkins’ multiverse theory.
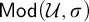
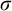
RSL volume 14 issue 2 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 15 July 2021, pp. b1-b2
- Print publication:
- June 2021
-
- Article
-
- You have access
- Export citation
RSL volume 14 issue 2 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 15 July 2021, pp. f1-f4
- Print publication:
- June 2021
-
- Article
-
- You have access
- Export citation
QUANTIFIED MODAL RELEVANT LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 23 April 2021, pp. 210-240
- Print publication:
- March 2023
-
- Article
- Export citation
-
Here, I combine the semantics of Mares and Goldblatt [20] and Seki [29, 30] to develop a semantics for quantified modal relevant logics extending
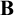 ${\bf B}$. The combination requires demonstrating that the Mares–Goldblatt approach is apt for quantified extensions of
${\bf B}$. The combination requires demonstrating that the Mares–Goldblatt approach is apt for quantified extensions of 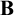 ${\bf B}$ and other relevant logics, but no significant bridging principles are needed. The result is a single semantic approach for quantified modal relevant logics. Within this framework, I discuss the requirements a quantified modal relevant logic must satisfy to be “sufficiently classical” in its modal fragment, where frame conditions are given that work for positive fragments of logics. The roles of the Barcan formula and its converse are also investigated.
${\bf B}$ and other relevant logics, but no significant bridging principles are needed. The result is a single semantic approach for quantified modal relevant logics. Within this framework, I discuss the requirements a quantified modal relevant logic must satisfy to be “sufficiently classical” in its modal fragment, where frame conditions are given that work for positive fragments of logics. The roles of the Barcan formula and its converse are also investigated.