Refine search
Actions for selected content:
53197 results in Statistics and Probability
Estimating excess septicaemia mortality and hospitalisation burden associated with influenza in Hong Kong, 1998 to 2019
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 27 April 2022, e101
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spatial meta-analysis of the occurrence and distribution of tsetse-transmitted animal trypanosomiasis in Cameroon over the last 30 years
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 27 April 2022, e97
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiple molecular characteristics of circulating enterovirus types among paediatric hand, foot and mouth disease patients after EV71 vaccination campaign in Wuxi, China
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 27 April 2022, e98
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
HOW RELIABLE ARE BOOTSTRAP-BASED HETEROSKEDASTICITY ROBUST TESTS?
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 27 April 2022, pp. 789-847
-
- Article
-
- You have access
- Open access
- Export citation
MULTIVARIATE DISTRIBUTIONS WITH TIME AND CROSS-DEPENDENCE: AGGREGATION AND CAPITAL ALLOCATION
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 2 / May 2022
- Published online by Cambridge University Press:
- 27 April 2022, pp. 669-706
- Print publication:
- May 2022
-
- Article
- Export citation
Data mining and knowledge discovery in chemical processes: Effect of alternative processing techniques
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 26 April 2022, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Increasing Resilience via the Use of Personal Data: Lessons from COVID-19 Dashboards on Data Governance for the Public Good – Corrigendum
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 26 April 2022, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Giant descendant trees, matchings, and independent sets in age-biased attachment graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 25 April 2022, pp. 299-324
- Print publication:
- June 2022
-
- Article
- Export citation
-
We study two models of an age-biased graph process: the
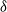 $\delta$-version of the preferential attachment graph model (PAM) and the uniform attachment graph model (UAM), with m attachments for each of the incoming vertices. We show that almost surely the scaled size of a breadth-first (descendant) tree rooted at a fixed vertex converges, for
$\delta$-version of the preferential attachment graph model (PAM) and the uniform attachment graph model (UAM), with m attachments for each of the incoming vertices. We show that almost surely the scaled size of a breadth-first (descendant) tree rooted at a fixed vertex converges, for 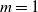 $m=1$, to a limit whose distribution is a mixture of two beta distributions and a single beta distribution respectively, and that for
$m=1$, to a limit whose distribution is a mixture of two beta distributions and a single beta distribution respectively, and that for 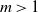 $m>1$ the limit is 1. We also analyze the likely performance of two greedy (online) algorithms, for a large matching set and a large independent set, and determine – for each model and each greedy algorithm – both a limiting fraction of vertices involved and an almost sure convergence rate.
$m>1$ the limit is 1. We also analyze the likely performance of two greedy (online) algorithms, for a large matching set and a large independent set, and determine – for each model and each greedy algorithm – both a limiting fraction of vertices involved and an almost sure convergence rate.
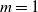
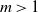
Thermoacoustic stability prediction using classification algorithms
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 25 April 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Disorder detection with costly observations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 25 April 2022, pp. 338-349
- Print publication:
- June 2022
-
- Article
- Export citation
SECOND-ORDER BIAS REDUCTION FOR NONLINEAR PANEL DATA MODELS WITH FIXED EFFECTS BASED ON EXPECTED QUANTITIES
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 25 April 2022, pp. 693-736
-
- Article
-
- You have access
- Open access
- Export citation
Seroprevalence and dynamics of anti-SARS-CoV-2 antibody among healthcare workers following ChAdOx1 nCoV-19 vaccination
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 25 April 2022, e83
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Validation of a clinical and genetic model for predicting severe COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 25 April 2022, e91
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editors’ Note
-
- Journal:
- Network Science / Volume 10 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 April 2022, pp. 1-2
-
- Article
-
- You have access
- HTML
- Export citation
Circulating sex-steroids and Staphylococcus aureus nasal carriage in a general male population
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 22 April 2022, e93
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A theoretical and empirical comparison of the temporal exponential random graph model and the stochastic actor-oriented model – Corrigendum
-
- Journal:
- Network Science / Volume 10 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 April 2022, p. 111
-
- Article
-
- You have access
- HTML
- Export citation
Winning during a pandemic: epidemiology of SARS-CoV-2 during EURO2020 in Italy
- Part of
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 22 April 2022, e166
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Role detection in bicycle-sharing networks using multilayer stochastic block models
-
- Journal:
- Network Science / Volume 10 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 April 2022, pp. 46-81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Immunity acquired by a minority active fraction of the population could explain COVID-19 spread in Greater Buenos Aires (June–November 2020)
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 22 April 2022, e84
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NWS volume 10 issue 1 Cover and Front matter
-
- Journal:
- Network Science / Volume 10 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 22 April 2022, pp. f1-f3
-
- Article
-
- You have access
- Export citation
