Refine search
Actions for selected content:
53197 results in Statistics and Probability

Time Series Data Analysis in Oceanography
- Applications using MATLAB
-
- Published online:
- 21 April 2022
- Print publication:
- 05 May 2022
Forecasting the monthly incidence of scarlet fever in Chongqing, China using the SARIMA model
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 21 April 2022, e90
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Examining the association between socio-demographic factors, catheter use and antibiotic prescribing in Northern Ireland primary care: a cross-sectional multilevel analysis
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 21 April 2022, e92
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dependence comparisons of order statistics in the proportional hazards model
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 3 / July 2023
- Published online by Cambridge University Press:
- 21 April 2022, pp. 730-736
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $X_1, \ldots, X_n$ be mutually independent exponential random variables with distinct hazard rates
$X_1, \ldots, X_n$ be mutually independent exponential random variables with distinct hazard rates  $\lambda _1, \ldots, \lambda _n$ and let
$\lambda _1, \ldots, \lambda _n$ and let  $Y_1, \ldots, Y_n$ be a random sample from the exponential distribution with hazard rate
$Y_1, \ldots, Y_n$ be a random sample from the exponential distribution with hazard rate 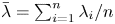 $\bar \lambda = \sum _{i=1}^{n} \lambda _i/n$. Also let
$\bar \lambda = \sum _{i=1}^{n} \lambda _i/n$. Also let  $X_{1:n} \lt \cdots \lt X_{n:n}$ and
$X_{1:n} \lt \cdots \lt X_{n:n}$ and  $Y_{1:n} \lt \cdots \lt Y_{n:n}$ be their associated order statistics. It is proved that for
$Y_{1:n} \lt \cdots \lt Y_{n:n}$ be their associated order statistics. It is proved that for 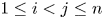 $1\le i \lt j \le n$, the generalized spacing
$1\le i \lt j \le n$, the generalized spacing 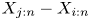 $X_{j:n} - X_{i:n}$ is more dispersed than
$X_{j:n} - X_{i:n}$ is more dispersed than  $Y_{j:n} - Y_{i:n}$ according to dispersive ordering and for
$Y_{j:n} - Y_{i:n}$ according to dispersive ordering and for 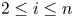 $2\le i \le n$, the dependence of
$2\le i \le n$, the dependence of 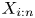 $X_{i:n}$ on
$X_{i:n}$ on 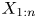 $X_{1:n}$ is less than that of
$X_{1:n}$ is less than that of 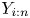 $Y_{i:n}$ on
$Y_{i:n}$ on 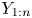 $Y_{1 :n}$, in the sense of the more stochastically increasing ordering. This dependence result is also extended to the proportional hazard rates (PHR) model. This extends the earlier work of Genest et al. [(2009)]. On the range of heterogeneous samples. Journal of Multivariate Analysis 100: 1587–1592] who proved this result for
$Y_{1 :n}$, in the sense of the more stochastically increasing ordering. This dependence result is also extended to the proportional hazard rates (PHR) model. This extends the earlier work of Genest et al. [(2009)]. On the range of heterogeneous samples. Journal of Multivariate Analysis 100: 1587–1592] who proved this result for  $i =n$.
$i =n$.



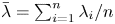


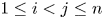
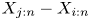

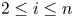
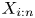
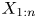
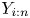
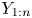

The impact of alcohol control policy on pneumonia mortality in Lithuania: an interrupted time-series analysis
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 April 2022, e96
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Outbreak of delta variant SARS-CoV-2 virus on a psychogeriatric ward in Helsinki, Finland, August 2021: two-dose vaccination reduces mortality and disease severity amongst the elderly
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 April 2022, e95
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Longitudinal study of SARS-CoV-2 infections in different employee groups of long distance train services from June 2020 until February 2021 in Germany
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 April 2022, e88
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maternal hepatitis B surface antigen carrier status and pregnancy outcome: a retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 20 April 2022, e89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COINTEGRATION AND REPRESENTATION OF COINTEGRATED AUTOREGRESSIVE PROCESSES IN BANACH SPACES
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 20 April 2022, pp. 737-788
-
- Article
-
- You have access
- Open access
- Export citation
-
We extend the notion of cointegration for time series taking values in a potentially infinite dimensional Banach space. Examples of such time series include stochastic processes in
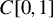 $C[0,1]$ equipped with the supremum distance and those in a finite dimensional vector space equipped with a non-Euclidean distance. We then develop versions of the Granger–Johansen representation theorems for I(1) and I(2) autoregressive (AR) processes taking values in such a space. To achieve this goal, we first note that an AR(p) law of motion can be characterized by a linear operator pencil (an operator-valued map with certain properties) via the companion form representation, and then study the spectral properties of a linear operator pencil to obtain a necessary and sufficient condition for a given AR(p) law of motion to admit I(1) or I(2) solutions. These operator-theoretic results form a fundamental basis for our representation theorems. Furthermore, it is shown that our operator-theoretic approach is in fact a closely related extension of the conventional approach taken in a Euclidean space setting. Our theoretical results may be especially relevant in a recently growing literature on functional time series analysis in Banach spaces.
$C[0,1]$ equipped with the supremum distance and those in a finite dimensional vector space equipped with a non-Euclidean distance. We then develop versions of the Granger–Johansen representation theorems for I(1) and I(2) autoregressive (AR) processes taking values in such a space. To achieve this goal, we first note that an AR(p) law of motion can be characterized by a linear operator pencil (an operator-valued map with certain properties) via the companion form representation, and then study the spectral properties of a linear operator pencil to obtain a necessary and sufficient condition for a given AR(p) law of motion to admit I(1) or I(2) solutions. These operator-theoretic results form a fundamental basis for our representation theorems. Furthermore, it is shown that our operator-theoretic approach is in fact a closely related extension of the conventional approach taken in a Euclidean space setting. Our theoretical results may be especially relevant in a recently growing literature on functional time series analysis in Banach spaces.
A greedy data collection scheme for linear dynamical systems
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 19 April 2022, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Statistical Hypothesis Testing in Context
- Reproducibility, Inference, and Science
-
- Published online:
- 17 April 2022
- Print publication:
- 05 May 2022
ECT volume 38 issue 2 Cover and Front matter
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 13 April 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
ECT volume 38 issue 2 Cover and Back matter
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 13 April 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
THE ECONOMETRIC THEORY AWARDS 2022
-
- Journal:
- Econometric Theory / Volume 38 / Issue 2 / April 2022
- Published online by Cambridge University Press:
- 13 April 2022, p. 418
-
- Article
-
- You have access
- Export citation
BACKWARD CUSUM FOR TESTING AND MONITORING STRUCTURAL CHANGE WITH AN APPLICATION TO COVID-19 PANDEMIC DATA
-
- Journal:
- Econometric Theory / Volume 39 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 12 April 2022, pp. 659-692
-
- Article
- Export citation
TARGET VOLATILITY STRATEGIES FOR GROUP SELF-ANNUITY PORTFOLIOS
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 52 / Issue 2 / May 2022
- Published online by Cambridge University Press:
- 11 April 2022, pp. 591-617
- Print publication:
- May 2022
-
- Article
- Export citation
Universal Digital Twin: Land Use – ADDENDUM
-
- Journal:
- Data-Centric Engineering / Volume 3 / 2022
- Published online by Cambridge University Press:
- 08 April 2022, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data responsibility, corporate social responsibility, and corporate digital responsibility
-
- Journal:
- Data & Policy / Volume 4 / 2022
- Published online by Cambridge University Press:
- 08 April 2022, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamic changes of SARS-CoV-2 specific IgM and IgG among population vaccinated with COVID-19 vaccine
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 08 April 2022, e74
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Epidemiological characteristics of mumps from 2004 to 2020 in Jiangsu, China: a flexible spatial and spatiotemporal analysis
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 08 April 2022, e86
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
