Refine search
Actions for selected content:
52707 results in Statistics and Probability
Chapter 12 - Challenges for Evidence-Based Diagnosis
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 303-317
-
- Chapter
- Export citation
Dedication
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp v-vi
-
- Chapter
- Export citation
RISK-BASED CAPITAL FOR VARIABLE ANNUITY UNDER STOCHASTIC INTEREST RATE
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 50 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 25 June 2020, pp. 959-999
- Print publication:
- September 2020
-
- Article
- Export citation
Appendix 2.4 - Formulas for Testing Thresholds for Dichotomous Tests
- from Chapter 2 - Dichotomous Tests
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 34-36
-
- Chapter
- Export citation
Appendix 2.1 - General Summary of Definitions and Formulas for Dichotomous Tests
- from Chapter 2 - Dichotomous Tests
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 31-31
-
- Chapter
- Export citation
Chapter 7 - Multiple Tests and Multivariable Risk Models
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 175-204
-
- Chapter
- Export citation
Chapter 9 - Alternatives to Randomized Trials for Estimating Treatment Effects
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 231-249
-
- Chapter
- Export citation
Chapter 3 - Multilevel and Continuous Tests
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 47-74
-
- Chapter
- Export citation
Chapter 1 - Introduction
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp 1-7
-
- Chapter
- Export citation
Mortality and survival of COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 25 June 2020, e123
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contents
-
- Book:
- Evidence-Based Diagnosis
- Published online:
- 02 May 2020
- Print publication:
- 25 June 2020, pp vii-viii
-
- Chapter
- Export citation
Hamiltonicity in random directed graphs is born resilient
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 24 June 2020, pp. 900-942
-
- Article
- Export citation
-
Let
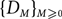 $\{D_M\}_{M\geq 0}$ be the n-vertex random directed graph process, where
$\{D_M\}_{M\geq 0}$ be the n-vertex random directed graph process, where 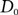 $D_0$ is the empty directed graph on n vertices, and subsequent directed graphs in the sequence are obtained by the addition of a new directed edge uniformly at random. For each
$D_0$ is the empty directed graph on n vertices, and subsequent directed graphs in the sequence are obtained by the addition of a new directed edge uniformly at random. For each 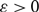 $$\varepsilon> 0$$, we show that, almost surely, any directed graph
$$\varepsilon> 0$$, we show that, almost surely, any directed graph 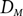 $D_M$ with minimum in- and out-degree at least 1 is not only Hamiltonian (as shown by Frieze), but remains Hamiltonian when edges are removed, as long as at most
$D_M$ with minimum in- and out-degree at least 1 is not only Hamiltonian (as shown by Frieze), but remains Hamiltonian when edges are removed, as long as at most 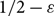 $1/2-\varepsilon$ of both the in- and out-edges incident to each vertex are removed. We say such a directed graph is
$1/2-\varepsilon$ of both the in- and out-edges incident to each vertex are removed. We say such a directed graph is 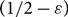 $(1/2-\varepsilon)$-resiliently Hamiltonian. Furthermore, for each
$(1/2-\varepsilon)$-resiliently Hamiltonian. Furthermore, for each 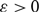 $\varepsilon > 0$, we show that, almost surely, each directed graph
$\varepsilon > 0$, we show that, almost surely, each directed graph 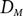 $D_M$ in the sequence is not
$D_M$ in the sequence is not 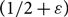 $(1/2+\varepsilon)$-resiliently Hamiltonian.
$(1/2+\varepsilon)$-resiliently Hamiltonian.This improves a result of Ferber, Nenadov, Noever, Peter and Škorić who showed, for each
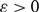 $\varepsilon > 0$, that the binomial random directed graph
$\varepsilon > 0$, that the binomial random directed graph 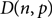 $D(n,p)$ is almost surely
$D(n,p)$ is almost surely 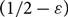 $(1/2-\varepsilon)$-resiliently Hamiltonian if
$(1/2-\varepsilon)$-resiliently Hamiltonian if 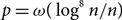 $p=\omega(\log^8n/n)$.
$p=\omega(\log^8n/n)$.
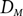
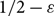
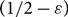
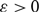
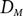
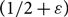
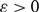
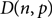
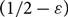
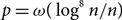
Towards the Kohayakawa–Kreuter conjecture on asymmetric Ramsey properties
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 24 June 2020, pp. 943-955
-
- Article
- Export citation
Response to the letter from Dr J. Wang
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 23 June 2020, e133
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NASH EQUILIBRIUM STRATEGIES REVISITED IN SOFTWARE RELEASE GAMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 23 June 2020, pp. 105-125
-
- Article
- Export citation
Supersaturation of even linear cycles in linear hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 23 June 2020, pp. 698-721
-
- Article
- Export citation
Deterministic counting of graph colourings using sequences of subgraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 22 June 2020, pp. 555-586
-
- Article
- Export citation
-
In this paper we propose a polynomial-time deterministic algorithm for approximately counting the k-colourings of the random graph G(n, d/n), for constant d>0. In particular, our algorithm computes in polynomial time a
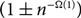 $(1\pm n^{-\Omega(1)})$-approximation of the so-called ‘free energy’ of the k-colourings of G(n, d/n), for
$(1\pm n^{-\Omega(1)})$-approximation of the so-called ‘free energy’ of the k-colourings of G(n, d/n), for 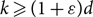 $k\geq (1+\varepsilon) d$ with probability
$k\geq (1+\varepsilon) d$ with probability 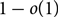 $1-o(1)$ over the graph instances.
$1-o(1)$ over the graph instances.Our algorithm uses spatial correlation decay to compute numerically estimates of marginals of the Gibbs distribution. Spatial correlation decay has been used in different counting schemes for deterministic counting. So far algorithms have exploited a certain kind of set-to-point correlation decay, e.g. the so-called Gibbs uniqueness. Here we deviate from this setting and exploit a point-to-point correlation decay. The spatial mixing requirement is that for a pair of vertices the correlation between their corresponding configurations becomes weaker with their distance.
Furthermore, our approach generalizes in that it allows us to compute the Gibbs marginals for small sets of nearby vertices. Also, we establish a connection between the fluctuations of the number of colourings of G(n, d/n) and the fluctuations of the number of short cycles and edges in the graph.
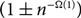
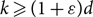
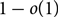
Association of spontaneous abortion and Ureaplasma parvum detected in placental tissue
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 22 June 2020, e126
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Treatment and preliminary outcomes of 150 acute care patients with COVID-19 in a rural health system in the Dakotas
-
- Journal:
- Epidemiology & Infection / Volume 148 / 2020
- Published online by Cambridge University Press:
- 22 June 2020, e124
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CBDX: a workhorse mortality model from the Cairns–Blake–Dowd family
-
- Journal:
- Annals of Actuarial Science / Volume 14 / Issue 2 / September 2020
- Published online by Cambridge University Press:
- 22 June 2020, pp. 445-460
-
- Article
- Export citation
