FirstView articles
Contents
Research Article
Dynamic response of redundant robot manipulators under impedance control with null-space control
-
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hip motor state-optimized jump trajectory planning algorithm for bipedal wheeled robots
-
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-19
-
- Article
- Export citation
Spiral structure design of a vascular interventional robot based on fluid-structure interaction
-
- Published online by Cambridge University Press:
- 25 June 2026, pp. 1-17
-
- Article
- Export citation
The effect of tail configuration and parameters on the aerodynamic performance of flapping-wing flying robots: design and experiment
-
- Published online by Cambridge University Press:
- 24 June 2026, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the design of AGRIMARO.Q, a reconfigurable omnidirectional rover for precision agriculture in greenhouses
-
- Published online by Cambridge University Press:
- 24 June 2026, pp. 1-15
-
- Article
- Export citation
Wobble control of a pendulum-based spherical robot
-
- Published online by Cambridge University Press:
- 24 June 2026, pp. 1-31
-
- Article
- Export citation
Mechanism design and trajectory planning of a kinematically redundant parallel climbing robot
-
- Published online by Cambridge University Press:
- 23 June 2026, pp. 1-20
-
- Article
- Export citation
Performance analysis and scale parameter optimization of a shipborne parallel stabilized platform
-
- Published online by Cambridge University Press:
- 16 June 2026, pp. 1-32
-
- Article
- Export citation
Addressing the deadlock problem of the optimal reciprocal collision avoidance algorithm in distributed multi-robot navigation
-
- Published online by Cambridge University Press:
- 11 June 2026, pp. 1-19
-
- Article
- Export citation
Cross-platform learnable fuzzy gain-scheduled proportional-integral-derivative controller tuning via physics-constrained meta-learning and reinforcement learning adaptation
-
- Published online by Cambridge University Press:
- 11 June 2026, pp. 1-42
-
- Article
- Export citation
-
Motivation and gap: PID-family controllers remain a pragmatic choice for many robotic systems due to their simplicity and interpretability, but tuning stable, high-performing gains is time consuming and typically non-transferable across robot morphologies, payloads, and deployment conditions. Fuzzy gain scheduling can provide interpretable online adjustment, yet its per-joint scaling and consequent parameters are platform dependent and difficult to tune systematically.
Proposed approach: We propose a hierarchical framework for cross-platform tuning of a learnable fuzzy gain-scheduled PID (LF-PID). The controller uses shared fuzzy membership partitions to preserve common error semantics, while learning per-joint scaling and Takagi–Sugeno consequent parameters that schedule PID gains online. Combined with physics-constrained virtual robot synthesis, meta-learning provides cross-platform initialization from robot physical features, and a lightweight reinforcement learning (RL) stage performs deployment-specific refinement under dynamics mismatch. Starting from three base simulated platforms, we generate 232 physically valid training variants via bounded perturbations of mass (
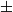 $\pm$10%), inertia (
$\pm$10%), inertia (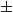 $\pm$15%), friction (
$\pm$15%), friction (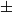 $\pm$20%), and damping (
$\pm$20%), and damping (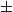 $\pm$30%).
$\pm$30%).Results and insight: We evaluate cross-platform generalization on two distinct systems (a 9-DOF serial manipulator and a 12-DOF quadruped) under multiple disturbance scenarios. The RL adaptation stage improves tracking performance on top of the meta-initialized controller, with up to 80.4% error reduction in challenging high-load joints (12.36
 $^\circ$
$^\circ$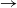 $\rightarrow$2.42
$\rightarrow$2.42 $^\circ$) and 19.2% improvement under parameter uncertainty. We further identify an optimization ceiling effect: online refinement yields substantial gains when the meta-initialized baseline exhibits localized deficiencies, but provides limited improvement when baseline quality is already uniformly strong.
$^\circ$) and 19.2% improvement under parameter uncertainty. We further identify an optimization ceiling effect: online refinement yields substantial gains when the meta-initialized baseline exhibits localized deficiencies, but provides limited improvement when baseline quality is already uniformly strong.
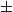

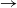

Functional arm compensation and fault tolerance for a hexapod robot with ipsilateral two-leg failure
-
- Published online by Cambridge University Press:
- 09 June 2026, pp. 1-18
-
- Article
- Export citation
A novel marine predator algorithm for robot task allocation problem
-
- Published online by Cambridge University Press:
- 09 June 2026, pp. 1-33
-
- Article
- Export citation
Corrigendum
Attitude stability control system for a hexapod bionic robot under hybrid disturbances – CORRIGENDUM
-
- Published online by Cambridge University Press:
- 02 June 2026, pp. 1-2
-
- Article
-
- You have access
- HTML
- Export citation
Research Article
Chain-flocking: navigation of multiple agents with local measurements in unknown environments
-
- Published online by Cambridge University Press:
- 01 June 2026, pp. 1-24
-
- Article
- Export citation