Refine search
Actions for selected content:
91 results
Phase transition in preferential attachment–detachment through embedding
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 08 June 2026, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Extremal Graph Theory
-
- Book:
- Basic Graph Theory
- Published online:
- 15 March 2026
- Print publication:
- 26 March 2026, pp 44-79
-
- Chapter
- Export citation
5 - Random Graphs
-
- Book:
- Basic Graph Theory
- Published online:
- 15 March 2026
- Print publication:
- 26 March 2026, pp 174-212
-
- Chapter
- Export citation

Basic Graph Theory
-
- Published online:
- 15 March 2026
- Print publication:
- 26 March 2026
2 - Concentration of Sums of Independent Random Variables
-
- Book:
- High-Dimensional Probability
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 24-57
-
- Chapter
- Export citation
Canonization of a random circulant graph by counting walks
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 35 / Issue 2 / March 2026
- Published online by Cambridge University Press:
- 26 November 2025, pp. 178-206
-
- Article
- Export citation
-
It is well known that almost all graphs are canonizable by a simple combinatorial routine known as colour refinement, also referred to as the 1-dimensional Weisfeiler–Leman algorithm. With high probability, this method assigns a unique label to each vertex of a random input graph and, hence, it is applicable only to asymmetric graphs. The strength of combinatorial refinement techniques becomes a subtle issue if the input graphs are highly symmetric. We prove that the combination of colour refinement and vertex individualization yields a canonical labelling for almost all circulant digraphs (i.e., Cayley digraphs of a cyclic group). This result provides first evidence of good average-case performance of combinatorial refinement within the class of vertex-transitive graphs. Remarkably, we do not even need the full power of the colour refinement algorithm. We show that the canonical label of a vertex
 $v$ can be obtained just by counting walks of each length from
$v$ can be obtained just by counting walks of each length from  $v$ to an individualized vertex. Our analysis also implies that almost all circulant graphs are compact in the sense of Tinhofer, that is, their polytops of fractional automorphisms are integral. Finally, we show that a canonical Cayley representation can be constructed for almost all circulant graphs by the more powerful 2-dimensional Weisfeiler–Leman algorithm.
$v$ to an individualized vertex. Our analysis also implies that almost all circulant graphs are compact in the sense of Tinhofer, that is, their polytops of fractional automorphisms are integral. Finally, we show that a canonical Cayley representation can be constructed for almost all circulant graphs by the more powerful 2-dimensional Weisfeiler–Leman algorithm.


The distance on the slightly supercritical random series–parallel graph
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 58 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 09 September 2025, pp. 80-121
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the random series–parallel graph introduced by Hambly and Jordan (2004 Adv. Appl. Probab. 36, 824–838), which is a hierarchical graph with a parameter
 $p\in [0, \, 1]$. The graph is built recursively: at each step, every edge in the graph is either replaced with probability p by a series of two edges, or with probability
$p\in [0, \, 1]$. The graph is built recursively: at each step, every edge in the graph is either replaced with probability p by a series of two edges, or with probability 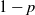 $1-p$ by two parallel edges, and the replacements are independent of each other and of everything up to then. At the nth step of the recursive procedure, the distance between the extremal points on the graph is denoted by
$1-p$ by two parallel edges, and the replacements are independent of each other and of everything up to then. At the nth step of the recursive procedure, the distance between the extremal points on the graph is denoted by  $D_n (p)$. It is known that
$D_n (p)$. It is known that  $D_n(p)$ possesses a phase transition at
$D_n(p)$ possesses a phase transition at  $p=p_c \;:\!=\;\frac{1}{2}$; more precisely,
$p=p_c \;:\!=\;\frac{1}{2}$; more precisely,  $\frac{1}{n}\log {{\mathbb{E}}}[D_n(p)] \to \alpha(p)$ when
$\frac{1}{n}\log {{\mathbb{E}}}[D_n(p)] \to \alpha(p)$ when  $n \to \infty$, with
$n \to \infty$, with  $\alpha(p) >0$ for
$\alpha(p) >0$ for  $p>p_c$ and
$p>p_c$ and  $\alpha(p)=0$ for
$\alpha(p)=0$ for  $p\le p_c$. We study the exponent
$p\le p_c$. We study the exponent  $\alpha(p)$ in the slightly supercritical regime
$\alpha(p)$ in the slightly supercritical regime 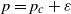 $p=p_c+\varepsilon$. Our main result says that as
$p=p_c+\varepsilon$. Our main result says that as  $\varepsilon\to 0^+$,
$\varepsilon\to 0^+$,  $\alpha(p_c+\varepsilon)$ behaves like
$\alpha(p_c+\varepsilon)$ behaves like 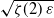 $\sqrt{\zeta(2) \, \varepsilon}$, where
$\sqrt{\zeta(2) \, \varepsilon}$, where  $\zeta(2) \;:\!=\; \frac{\pi^2}{6}$.
$\zeta(2) \;:\!=\; \frac{\pi^2}{6}$.











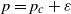


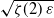

Online matching for the multiclass stochastic block model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 21 July 2025, pp. 1360-1381
- Print publication:
- December 2025
-
- Article
- Export citation
Cokernel statistics for walk matrices of directed and weighted random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 18 October 2024, pp. 131-150
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The walk matrix associated to an
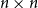 $n\times n$ integer matrix
$n\times n$ integer matrix 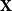 $\mathbf{X}$ and an integer vector
$\mathbf{X}$ and an integer vector 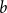 $b$ is defined by
$b$ is defined by 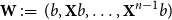 ${\mathbf{W}} \,:\!=\, (b,{\mathbf{X}} b,\ldots, {\mathbf{X}}^{n-1}b)$. We study limiting laws for the cokernel of
${\mathbf{W}} \,:\!=\, (b,{\mathbf{X}} b,\ldots, {\mathbf{X}}^{n-1}b)$. We study limiting laws for the cokernel of 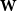 $\mathbf{W}$ in the scenario where
$\mathbf{W}$ in the scenario where 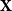 $\mathbf{X}$ is a random matrix with independent entries and
$\mathbf{X}$ is a random matrix with independent entries and 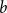 $b$ is deterministic. Our first main result provides a formula for the distribution of the
$b$ is deterministic. Our first main result provides a formula for the distribution of the 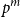 $p^m$-torsion part of the cokernel, as a group, when
$p^m$-torsion part of the cokernel, as a group, when 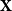 $\mathbf{X}$ has independent entries from a specific distribution. The second main result relaxes the distributional assumption and concerns the
$\mathbf{X}$ has independent entries from a specific distribution. The second main result relaxes the distributional assumption and concerns the 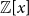 ${\mathbb{Z}}[x]$-module structure.
${\mathbb{Z}}[x]$-module structure.The motivation for this work arises from an open problem in spectral graph theory, which asks to show that random graphs are often determined up to isomorphism by their (generalised) spectrum. Sufficient conditions for generalised spectral determinacy can, namely, be stated in terms of the cokernel of a walk matrix. Extensions of our results could potentially be used to determine how often those conditions are satisfied. Some remaining challenges for such extensions are outlined in the paper.
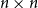
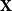
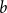
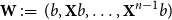
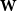
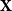
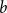
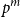
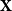
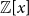
Behaviour of the minimum degree throughout the
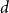 ${\textit{d}}$-process
${\textit{d}}$-process
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 22 April 2024, pp. 564-582
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The
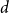 $d$-process generates a graph at random by starting with an empty graph with
$d$-process generates a graph at random by starting with an empty graph with  $n$ vertices, then adding edges one at a time uniformly at random among all pairs of vertices which have degrees at most
$n$ vertices, then adding edges one at a time uniformly at random among all pairs of vertices which have degrees at most 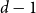 $d-1$ and are not mutually joined. We show that, in the evolution of a random graph with
$d-1$ and are not mutually joined. We show that, in the evolution of a random graph with  $n$ vertices under the
$n$ vertices under the 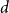 $d$-process with
$d$-process with 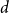 $d$ fixed, with high probability, for each
$d$ fixed, with high probability, for each 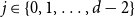 $j \in \{0,1,\dots,d-2\}$, the minimum degree jumps from
$j \in \{0,1,\dots,d-2\}$, the minimum degree jumps from 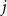 $j$ to
$j$ to 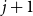 $j+1$ when the number of steps left is on the order of
$j+1$ when the number of steps left is on the order of 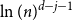 $\ln (n)^{d-j-1}$. This answers a question of Ruciński and Wormald. More specifically, we show that, when the last vertex of degree
$\ln (n)^{d-j-1}$. This answers a question of Ruciński and Wormald. More specifically, we show that, when the last vertex of degree 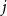 $j$ disappears, the number of steps left divided by
$j$ disappears, the number of steps left divided by 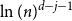 $\ln (n)^{d-j-1}$ converges in distribution to the exponential random variable of mean
$\ln (n)^{d-j-1}$ converges in distribution to the exponential random variable of mean 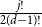 $\frac{j!}{2(d-1)!}$; furthermore, these
$\frac{j!}{2(d-1)!}$; furthermore, these 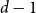 $d-1$ distributions are independent.
$d-1$ distributions are independent.
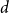

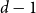

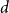
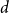
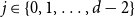
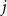
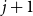
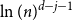
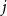
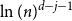
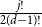
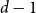
Limiting empirical spectral distribution for the non-backtracking matrix of an Erdős-Rényi random graph
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 31 July 2023, pp. 956-973
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this note, we give a precise description of the limiting empirical spectral distribution for the non-backtracking matrices for an Erdős-Rényi graph
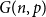 $G(n,p)$ assuming
$G(n,p)$ assuming 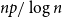 $np/\log n$ tends to infinity. We show that derandomizing part of the non-backtracking random matrix simplifies the spectrum considerably, and then, we use Tao and Vu’s replacement principle and the Bauer-Fike theorem to show that the partly derandomized spectrum is, in fact, very close to the original spectrum.
$np/\log n$ tends to infinity. We show that derandomizing part of the non-backtracking random matrix simplifies the spectrum considerably, and then, we use Tao and Vu’s replacement principle and the Bauer-Fike theorem to show that the partly derandomized spectrum is, in fact, very close to the original spectrum.
Random multi-hooking networks
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 13 February 2023, pp. 100-114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Girth, magnitude homology and phase transition of diagonality
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 1 / February 2024
- Published online by Cambridge University Press:
- 09 February 2023, pp. 221-247
- Print publication:
- February 2024
-
- Article
- Export citation
Random networks grown by fusing edges via urns
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 03 November 2022, pp. 347-360
-
- Article
- Export citation
On connectivity and robustness of random graphs with inhomogeneity
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 05 September 2022, pp. 284-294
- Print publication:
- March 2023
-
- Article
- Export citation
Unusually large components in near-critical Erdős–Rényi graphs via ballot theorems
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 11 February 2022, pp. 840-869
-
- Article
- Export citation
-
We consider the near-critical Erdős–Rényi random graph G(n, p) and provide a new probabilistic proof of the fact that, when p is of the form
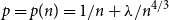 $p=p(n)=1/n+\lambda/n^{4/3}$ and A is large,where
$p=p(n)=1/n+\lambda/n^{4/3}$ and A is large,where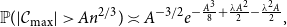 \begin{equation*}\mathbb{P}(|\mathcal{C}_{\max}|>An^{2/3})\asymp A^{-3/2}e^{-\frac{A^3}{8}+\frac{\lambda A^2}{2}-\frac{\lambda^2A}{2}},\end{equation*}
\begin{equation*}\mathbb{P}(|\mathcal{C}_{\max}|>An^{2/3})\asymp A^{-3/2}e^{-\frac{A^3}{8}+\frac{\lambda A^2}{2}-\frac{\lambda^2A}{2}},\end{equation*}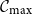 $\mathcal{C}_{\max}$ is the largest connected component of the graph. Our result allows A and
$\mathcal{C}_{\max}$ is the largest connected component of the graph. Our result allows A and 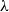 $\lambda$ to depend on n. While this result is already known, our proof relies only on conceptual and adaptable tools such as ballot theorems, whereas the existing proof relies on a combinatorial formula specific to Erdős–Rényi graphs, together with analytic estimates.
$\lambda$ to depend on n. While this result is already known, our proof relies only on conceptual and adaptable tools such as ballot theorems, whereas the existing proof relies on a combinatorial formula specific to Erdős–Rényi graphs, together with analytic estimates.
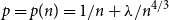
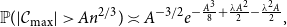
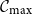
Prevalence of deficiency-zero reaction networks in an Erdös–Rényi framework
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 28 January 2022, pp. 384-398
- Print publication:
- June 2022
-
- Article
- Export citation
-
Reaction networks are commonly used within the mathematical biology and mathematical chemistry communities to model the dynamics of interacting species. These models differ from the typical graphs found in random graph theory since their vertices are constructed from elementary building blocks, i.e. the species. We consider these networks in an Erdös–Rényi framework and, under suitable assumptions, derive a threshold function for the network to have a deficiency of zero, which is a property of great interest in the reaction network community. Specifically, if the number of species is denoted by n and the edge probability by
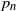 $p_n$, then we prove that the probability of a random binary network being deficiency zero converges to 1 if
$p_n$, then we prove that the probability of a random binary network being deficiency zero converges to 1 if 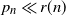 $p_n\ll r(n)$ as
$p_n\ll r(n)$ as 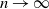 $n \to \infty$, and converges to 0 if
$n \to \infty$, and converges to 0 if 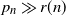 $p_n \gg r(n)$ as
$p_n \gg r(n)$ as 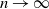 $n \to \infty$, where
$n \to \infty$, where 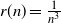 $r(n)=\frac{1}{n^3}$.
$r(n)=\frac{1}{n^3}$.
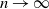
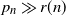
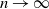
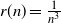
On model selection for dense stochastic block models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 14 January 2022, pp. 202-226
- Print publication:
- March 2022
-
- Article
- Export citation
Depths in hooking networks
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 4 / October 2022
- Published online by Cambridge University Press:
- 11 May 2021, pp. 941-949
-
- Article
- Export citation
THE NEAREST UNVISITED VERTEX WALK ON RANDOM GRAPHS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 3 / July 2022
- Published online by Cambridge University Press:
- 05 April 2021, pp. 851-867
-
- Article
-
- You have access
- Open access
- Export citation
