Refine search
Actions for selected content:
3404 results in Artificial Intelligence and Natural Language Processing
Improving aspect-based neural sentiment classification with lexicon enhancement, attention regularization and sentiment induction
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 12 September 2022, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Leveraging machine translation for cross-lingual fine-grained cyberbullying classification amongst pre-adolescents
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 07 September 2022, pp. 1458-1480
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From theories on styles to their transfer in text: Bridging the gap with a hierarchical survey
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 26 August 2022, pp. 849-908
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RoLEX: The development of an extended Romanian lexical dataset and its evaluation at predicting concurrent lexical information
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 26 August 2022, pp. 720-745
-
- Article
- Export citation
Recognition of visual scene elements from a story text in Persian natural language
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 24 August 2022, pp. 693-719
-
- Article
- Export citation
Quantifying the impact of context on the quality of manual hate speech annotation
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 22 August 2022, pp. 1481-1494
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NLE volume 28 issue 5 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. b1-b3
-
- Article
-
- You have access
- Export citation
Emerging trends: Deep nets thrive on scale
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. 673-682
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Deep nets are becoming larger and larger in practice, with no respect for (non)-factors that ought to limit growth including the so-called curse of dimensionality (CoD). Donoho suggested that dimensionality can be a blessing as well as a curse. Current practice in industry is well ahead of theory, but there are some recent theoretical results from Weinan E’s group suggesting that errors may be independent of dimensions
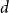 $d$. Current practice suggests an even stronger conjecture: deep nets are not merely immune to CoD, but actually, deep nets thrive on scale.
$d$. Current practice suggests an even stronger conjecture: deep nets are not merely immune to CoD, but actually, deep nets thrive on scale.
NLE volume 28 issue 5 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 5 / September 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Killing me softly: Creative and cognitive aspects of implicitness in abusive language online
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 03 August 2022, pp. 1516-1537
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From unified phrase representation to bilingual phrase alignment in an unsupervised manner
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 643-668
-
- Article
- Export citation
An empirical study of incorporating syntactic constraints into BERT-based location metonymy resolution
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 669-692
-
- Article
- Export citation
Named-entity recognition in Turkish legal texts
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 11 July 2022, pp. 615-642
-
- Article
- Export citation
Neural automated writing evaluation for Korean L2 writing
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 07 July 2022, pp. 1341-1363
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Construction Grammar Conceptual Network: Coordination-based graph method for semantic association analysis
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 04 July 2022, pp. 584-614
-
- Article
- Export citation
Artificial fine-tuning tasks for yes/no question answering
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 30 June 2022, pp. 73-95
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automated hate speech detection and span extraction in underground hacking and extremist forums
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 20 June 2022, pp. 1247-1274
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NLE volume 28 issue 4 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 4 / July 2022
- Published online by Cambridge University Press:
- 16 June 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
NLE volume 28 issue 4 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 28 / Issue 4 / July 2022
- Published online by Cambridge University Press:
- 16 June 2022, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Comparison of text preprocessing methods
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 3 / May 2023
- Published online by Cambridge University Press:
- 13 June 2022, pp. 509-553
-
- Article
- Export citation
