Refine search
Actions for selected content:
48285 results in Computer Science
3 - Numbers
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp 49-62
-
- Chapter
- Export citation
5 - A simple Sudoku solver
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp 89-109
-
- Chapter
- Export citation
9 - Infinite lists
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp 210-238
-
- Chapter
- Export citation
Contents
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp v-viii
-
- Chapter
- Export citation
11 - Parsing
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp 276-297
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp i-iv
-
- Chapter
- Export citation
12 - A simple equational calculator
-
- Book:
- Thinking Functionally with Haskell
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014, pp 298-337
-
- Chapter
- Export citation
Set Systems Containing Many Maximal Chains
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 09 October 2014, pp. 480-485
-
- Article
- Export citation
-
The purpose of this short problem paper is to raise the following extremal question on set systems: Which set systems of a given size maximise the number of (n + 1)-element chains in the power set
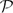 $\mathcal{P}$(1,2,. . .,n)? We will show that for each fixed α > 0 there is a family of α2n sets containing (α + o(1))n! such chains, and that this is asymptotically best possible. For smaller set systems we conjecture that a ‘tower of cubes’ construction is extremal. We finish by mentioning briefly a connection to an extremal problem on posets and a variant of our question for the grid graph.
$\mathcal{P}$(1,2,. . .,n)? We will show that for each fixed α > 0 there is a family of α2n sets containing (α + o(1))n! such chains, and that this is asymptotically best possible. For smaller set systems we conjecture that a ‘tower of cubes’ construction is extremal. We finish by mentioning briefly a connection to an extremal problem on posets and a variant of our question for the grid graph.
UIMA Ruta: Rapid development of rule-based information extraction applications
-
- Journal:
- Natural Language Engineering / Volume 22 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 08 October 2014, pp. 1-40
-
- Article
-
- You have access
- HTML
- Export citation
A Binary Deletion Channel With a Fixed Number of Deletions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 07 October 2014, pp. 486-489
-
- Article
- Export citation
SELF-REFERENCE IN ARITHMETIC I
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 4 / December 2014
- Published online by Cambridge University Press:
- 07 October 2014, pp. 671-691
- Print publication:
- December 2014
-
- Article
- Export citation
SELF-REFERENCE IN ARITHMETIC II
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 4 / December 2014
- Published online by Cambridge University Press:
- 07 October 2014, pp. 692-712
- Print publication:
- December 2014
-
- Article
- Export citation
-
In this sequel to Self-reference in arithmetic I we continue our discussion of the question: What does it mean for a sentence of arithmetic to ascribe to itself a property? We investigate how the properties of the supposedly self-referential sentences depend on the chosen coding, the formulae expressing the properties and the way a fixed point for the expressing formulae are obtained. In this second part we look at some further examples. In particular, we study sentences apparently expressing their Rosser-provability, their own
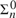 ${\rm{\Sigma }}_n^0$-truth or their own
${\rm{\Sigma }}_n^0$-truth or their own 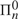 ${\rm{\Pi }}_n^0$-truth. Finally we offer an assessment of the results of both papers.
${\rm{\Pi }}_n^0$-truth. Finally we offer an assessment of the results of both papers.
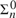
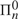
CPC volume 23 issue 6 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 06 October 2014, pp. b1-b8
-
- Article
-
- You have access
- Export citation
CPC volume 23 issue 6 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 06 October 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Conceptual modeling for knowledge management to support agile software development
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 496-511
-
- Article
- Export citation
Taxonomy of reputation assessment in peer-to-peer systems and analysis of their data retrieval
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 463-483
-
- Article
- Export citation
An efficient route scheduling mechanism for WiMAX network
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 452-462
-
- Article
- Export citation
Adaptivity in high-performance embedded systems: a reactive control model for reliable and flexible design
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 433-451
-
- Article
- Export citation
