Refine search
Actions for selected content:
48286 results in Computer Science
Adaptivity in high-performance embedded systems: a reactive control model for reliable and flexible design
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 433-451
-
- Article
- Export citation
Trends in high-performance computing and communications for ubiquitous computing
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 407-408
-
- Article
- Export citation
QoS-based active dropping mechanism for NGN video streaming optimization
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 484-495
-
- Article
- Export citation
Mobility-aware balanced scheduling algorithm in mobile Grid based on mobile agent
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 4 / September 2014
- Published online by Cambridge University Press:
- 03 October 2014, pp. 409-432
-
- Article
- Export citation
Introduction to the art of programming using Scala, by Mark C. Lewis, Chapman and Hall/CRC Press, 2012, £ 46.99 (paperback) ISBN-10:1439896666
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 02 October 2014, pp. 608-609
-
- Article
-
- You have access
- Export citation
Near Perfect Matchings in k-Uniform Hypergraphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 5 / September 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 723-732
-
- Article
- Export citation
Resolution of T. Ward's Question and the Israel–Finch Conjecture: Precise Analysis of an Integer Sequence Arising in Dynamics
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 195-215
-
- Article
- Export citation
-
We analyse the first-order asymptotic growth of
The integer an appears as the main term in a weighted average of the number of orbits in a particular quasihyperbolic automorphism of a 2n-torus, which has applications to ergodic and analytic number theory. The combinatorial structure of an is also of interest, as the ‘signed’ number of ways in which 0 can be represented as the sum of ϵjj for −n ≤ j ≤ n (with j ≠ 0), with ϵj ∈ {0, 1}. Our result answers a question of Thomas Ward (no relation to the fourth author) and confirms a conjecture of Robert Israel and Steven Finch.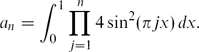 \[a_{n}=\int_{0}^{1}\prod_{j=1}^{n}4\sin^{2}(\pi jx)\, dx.\]
\[a_{n}=\int_{0}^{1}\prod_{j=1}^{n}4\sin^{2}(\pi jx)\, dx.\]
Quantitative Equidistribution for Certain Quadruples in Quasi-Random Groups
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 2 / March 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 376-381
-
- Article
- Export citation
An Alternative Proof of the Linearity of the Size-Ramsey Number of Paths
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 551-555
-
- Article
- Export citation
-
The size-Ramsey number
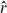 $\^{r} $(F) of a graph F is the smallest integer m such that there exists a graph G on m edges with the property that every colouring of the edges of G with two colours yields a monochromatic copy of F. In 1983, Beck provided a beautiful argument that shows that $\^{r} $(Pn) is linear, solving a problem of Erdős. In this note, we provide another proof of this fact that actually gives a better bound, namely, $\^{r} $(Pn) < 137n for n sufficiently large.
$\^{r} $(F) of a graph F is the smallest integer m such that there exists a graph G on m edges with the property that every colouring of the edges of G with two colours yields a monochromatic copy of F. In 1983, Beck provided a beautiful argument that shows that $\^{r} $(Pn) is linear, solving a problem of Erdős. In this note, we provide another proof of this fact that actually gives a better bound, namely, $\^{r} $(Pn) < 137n for n sufficiently large.
Improved Bounds for Incidences Between Points and Circles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 490-520
-
- Article
- Export citation
-
We establish an improved upper bound for the number of incidences between m points and n circles in three dimensions. The previous best known bound, originally established for the planar case and later extended to any dimension ≥ 2, is O*(m2/3n2/3 + m6/11n9/11 + m + n), where the O*(⋅) notation hides polylogarithmic factors. Since all the points and circles may lie on a common plane (or sphere), it is impossible to improve the bound in ℝ3 without first improving it in the plane.
Nevertheless, we show that if the set of circles is required to be ‘truly three-dimensional’ in the sense that no sphere or plane contains more than q of the circles, for some q ≪ n, then for any ϵ > 0 the bound can be improved to
For various ranges of parameters (e.g., when m = Θ(n) and q = o(n7/9)), this bound is smaller than the lower bound Ω*(m2/3n2/3 + m + n), which holds in two dimensions.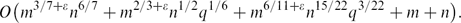 \[O\bigl(m^{3/7+\eps}n^{6/7} + m^{2/3+\eps}n^{1/2}q^{1/6} + m^{6/11+\eps}n^{15/22}q^{3/22} + m + n\bigr).\]
\[O\bigl(m^{3/7+\eps}n^{6/7} + m^{2/3+\eps}n^{1/2}q^{1/6} + m^{6/11+\eps}n^{15/22}q^{3/22} + m + n\bigr).\]We present several extensions and applications of the new bound.
(i) For the special case where all the circles have the same radius, we obtain the improved bound O(m5/11+ϵn9/11 + m2/3+ϵn1/2q1/6 + m + n).
(ii) We present an improved analysis that removes the subpolynomial factors from the bound when m = O(n3/2−ϵ) for any fixed ϵ < 0.
(iii) We use our results to obtain the improved bound O(m15/7) for the number of mutually similar triangles determined by any set of m points in ℝ3.
ON WEAK GROUND
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 4 / December 2014
- Published online by Cambridge University Press:
- 02 October 2014, pp. 713-744
- Print publication:
- December 2014
-
- Article
- Export citation
Longest Increasing Subsequences of Randomly Chosen Multi-Row Arrays
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 02 October 2014, pp. 254-293
-
- Article
- Export citation
-
A two-row array of integers
is said to be in lexicographic order if its columns are in lexicographic order (where character significance decreases from top to bottom, i.e., either ak < a k+1, or bk ≤ b k+1 when ak = a k+1). A length ℓ (strictly) increasing subsequence of αn is a set of indices i 1 < i 2 < ⋅⋅⋅ < i ℓ such that a i1 < a i2 < ⋅⋅⋅ < a iℓ and b i1 < b i2 < ⋅⋅⋅ < b iℓ . We are interested in the statistics of the length of a longest increasing subsequence of αn chosen according to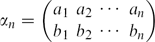 \[\alpha_{n}= \begin{pmatrix}a_1 & a_2 & \cdots & a_n\\ b_1 & b_2 & \cdots & b_n \end{pmatrix}\]
\[\alpha_{n}= \begin{pmatrix}a_1 & a_2 & \cdots & a_n\\ b_1 & b_2 & \cdots & b_n \end{pmatrix}\]  ${\cal D}$ n , for different families of distributions
${\cal D}$ n , for different families of distributions 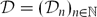 ${\cal D} = ({\cal D}_{n})_{n\in\NN}$ , and when n goes to infinity. This general framework encompasses well-studied problems such as the so-called longest increasing subsequence problem, the longest common subsequence problem, and problems concerning directed bond percolation models, among others. We define several natural families of different distributions and characterize the asymptotic behaviour of the length of a longest increasing subsequence chosen according to them. In particular, we consider generalizations to d-row arrays as well as symmetry-restricted two-row arrays.
${\cal D} = ({\cal D}_{n})_{n\in\NN}$ , and when n goes to infinity. This general framework encompasses well-studied problems such as the so-called longest increasing subsequence problem, the longest common subsequence problem, and problems concerning directed bond percolation models, among others. We define several natural families of different distributions and characterize the asymptotic behaviour of the length of a longest increasing subsequence chosen according to them. In particular, we consider generalizations to d-row arrays as well as symmetry-restricted two-row arrays.
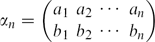
Computing symmetry groups of polyhedra
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 October 2014, pp. 565-581
-
- Article
-
- You have access
- Export citation
Computation on elliptic curves with complex multiplication
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 October 2014, pp. 509-535
-
- Article
-
- You have access
- Export citation
AIE volume 28 issue 4 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Improving the systems engineering process with multilevel analysis of interactions
-
- Article
-
- You have access
- HTML
- Export citation
Design of complex engineered systems
-
- Article
-
- You have access
- HTML
- Export citation
