Refine search
Actions for selected content:
48284 results in Computer Science

Thinking Functionally with Haskell
-
- Published online:
- 05 November 2014
- Print publication:
- 09 October 2014

Type Theory and Formal Proof
- An Introduction
-
- Published online:
- 05 November 2014
- Print publication:
- 06 November 2014

Principles of Automated Negotiation
-
- Published online:
- 05 November 2014
- Print publication:
- 13 November 2014
A classification of all 1-Salem graphs
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 November 2014, pp. 582-594
-
- Article
-
- You have access
- Export citation
-
One way to study certain classes of polynomials is by considering examples that are attached to combinatorial objects. Any graph
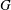 $G$ has an associated reciprocal polynomial
$G$ has an associated reciprocal polynomial 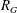 $R_{G}$ , and with two particular classes of reciprocal polynomials in mind one can ask the questions: (a) when is
$R_{G}$ , and with two particular classes of reciprocal polynomials in mind one can ask the questions: (a) when is 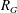 $R_{G}$ a product of cyclotomic polynomials (giving the cyclotomic graphs)? (b) when does
$R_{G}$ a product of cyclotomic polynomials (giving the cyclotomic graphs)? (b) when does 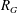 $R_{G}$ have the minimal polynomial of a Salem number as its only non-cyclotomic factor (the non-trivial Salem graphs)? Cyclotomic graphs were classified by Smith (Combinatorial structures and their applications, Proceedings of Calgary International Conference, Calgary, AB, 1969 (eds R. Guy, H. Hanani, H. Saver and J. Schönheim; Gordon and Breach, New York, 1970) 403–406); the maximal connected ones are known as Smith graphs. Salem graphs are ‘spectrally close’ to being cyclotomic, in that nearly all their eigenvalues are in the critical interval
$R_{G}$ have the minimal polynomial of a Salem number as its only non-cyclotomic factor (the non-trivial Salem graphs)? Cyclotomic graphs were classified by Smith (Combinatorial structures and their applications, Proceedings of Calgary International Conference, Calgary, AB, 1969 (eds R. Guy, H. Hanani, H. Saver and J. Schönheim; Gordon and Breach, New York, 1970) 403–406); the maximal connected ones are known as Smith graphs. Salem graphs are ‘spectrally close’ to being cyclotomic, in that nearly all their eigenvalues are in the critical interval 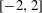 $[-2,2]$ . On the other hand, Salem graphs do not need to be ‘combinatorially close’ to being cyclotomic: the largest cyclotomic induced subgraph might be comparatively tiny.
$[-2,2]$ . On the other hand, Salem graphs do not need to be ‘combinatorially close’ to being cyclotomic: the largest cyclotomic induced subgraph might be comparatively tiny.We define an
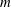 $m$ -Salem graph to be a connected Salem graph
$m$ -Salem graph to be a connected Salem graph 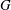 $G$ for which
$G$ for which 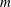 $m$ is minimal such that there exists an induced cyclotomic subgraph of
$m$ is minimal such that there exists an induced cyclotomic subgraph of 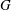 $G$ that has
$G$ that has 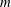 $m$ fewer vertices than
$m$ fewer vertices than 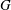 $G$ . The
$G$ . The 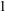 $1$ -Salem subgraphs are both spectrally close and combinatorially close to being cyclotomic. Moreover, every Salem graph contains a
$1$ -Salem subgraphs are both spectrally close and combinatorially close to being cyclotomic. Moreover, every Salem graph contains a 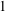 $1$ -Salem graph as an induced subgraph, so these
$1$ -Salem graph as an induced subgraph, so these 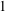 $1$ -Salem graphs provide some necessary substructure of all Salem graphs. The main result of this paper is a complete combinatorial description of all
$1$ -Salem graphs provide some necessary substructure of all Salem graphs. The main result of this paper is a complete combinatorial description of all 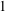 $1$ -Salem graphs: in the non-bipartite case there are
$1$ -Salem graphs: in the non-bipartite case there are 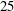 $25$ infinite families and
$25$ infinite families and 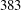 $383$ sporadic examples.
$383$ sporadic examples.
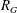
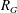
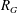
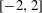
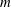
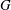
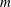
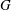
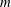
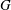
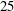
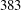
SCESS: a WFSA-based automated simplified chinese essay scoring system with incremental latent semantic analysis
-
- Journal:
- Natural Language Engineering / Volume 22 / Issue 2 / March 2016
- Published online by Cambridge University Press:
- 30 October 2014, pp. 291-319
-
- Article
- Export citation
XML clustering: a review of structural approaches
-
- Journal:
- The Knowledge Engineering Review / Volume 30 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 29 October 2014, pp. 297-323
-
- Article
- Export citation
A Gentle Guide to Constraint Logic Programming via ECLiPSe by Antoni Niederliński , xiii + 509 pages, published by Jacek Skalmierski Computer Studio, Third Edition, 2014.
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 29 October 2014, pp. 143-144
-
- Article
- Export citation
An Extension of the Hajnal–Szemerédi Theorem to Directed Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 5 / September 2015
- Published online by Cambridge University Press:
- 28 October 2014, pp. 754-773
-
- Article
- Export citation
-
Hajnal and Szemerédi proved that every graph G with |G| = ks and δ(G)⩾ k(s − 1) contains k disjoint s-cliques; moreover this degree bound is optimal. We extend their theorem to directed graphs by showing that every directed graph
 $\vv G$ with | $\vv G$ | = ks and δ( $\vv G$ ) ⩾ 2k(s − 1) − 1 contains k disjoint transitive tournaments on s vertices, where δ( $\vv G$ )= minv∈V ( $\vv G$ )d −(v)+d +(v). Our result implies the Hajnal–Szemerédi theorem, and its degree bound is optimal. We also make some conjectures regarding even more general results for multigraphs and partitioning into other tournaments. One of these conjectures is supported by an asymptotic result.
$\vv G$ with | $\vv G$ | = ks and δ( $\vv G$ ) ⩾ 2k(s − 1) − 1 contains k disjoint transitive tournaments on s vertices, where δ( $\vv G$ )= minv∈V ( $\vv G$ )d −(v)+d +(v). Our result implies the Hajnal–Szemerédi theorem, and its degree bound is optimal. We also make some conjectures regarding even more general results for multigraphs and partitioning into other tournaments. One of these conjectures is supported by an asymptotic result.
TLP volume 14 issue 6 Cover and Back matter
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 21 October 2014, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Query Complexity of Sampling and Small Geometric Partitions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 5 / September 2015
- Published online by Cambridge University Press:
- 21 October 2014, pp. 733-753
-
- Article
- Export citation
-
In this paper we study the following problem.
Discrete partitioning problem (DPP). Let
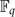 $\mathbb{F}_q$ Pn denote the n-dimensional finite projective space over $\mathbb{F}_q$ . For positive integer k ⩽ n, let {Ai }i = 1 N be a partition of ( $\mathbb{F}_q$ Pn )k such that:
$\mathbb{F}_q$ Pn denote the n-dimensional finite projective space over $\mathbb{F}_q$ . For positive integer k ⩽ n, let {Ai }i = 1 N be a partition of ( $\mathbb{F}_q$ Pn )k such that:-
(1) for all i ⩽ N, Ai = ∏ j=1 k Aj i (partition into product sets),
-
(2) for all i ⩽ N, there is a (k − 1)-dimensional subspace Li ⊆
$\mathbb{F}_q$ Pn such that Ai ⊆ (Li) k.
DPP arises in an approach that we propose for proving lower bounds for the query complexity of generating random points from convex bodies. It is also related to other partitioning problems in combinatorics and complexity theory. We conjecture an asymptotically optimal partition for DPP and show that it is optimal in two cases: when the dimension is low (k = n = 2) and when the factors of the parts are structured, namely factors of a part are close to being a subspace. These structured partitions arise naturally as partitions induced by query algorithms. Our problem does not seem to be directly amenable to previous techniques for partitioning lower bounds such as rank arguments, although rank arguments do lie at the core of our techniques.
-
TLP volume 14 issue 6 Cover and Front matter
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 6 / November 2014
- Published online by Cambridge University Press:
- 21 October 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Sperner's Problem for G-Independent Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 24 / Issue 3 / May 2015
- Published online by Cambridge University Press:
- 15 October 2014, pp. 528-550
-
- Article
- Export citation
(Un/Semi-)supervised SMS text message SPAM detection
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 4 / August 2015
- Published online by Cambridge University Press:
- 15 October 2014, pp. 553-567
-
- Article
- Export citation
