Refine search
Actions for selected content:
49487 results in Computer Science
Influence of confining stress on different diameters of disc cutters in rock cutting
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Differentiable causal computations via delayed trace (extended version)
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e10
-
- Article
- Export citation
-
We investigate causal computations, which take sequences of inputs to sequences of outputs such that the
 $n$th output depends on the first
$n$th output depends on the first  $n$ inputs only. We model these in category theory via a construction taking a Cartesian category
$n$ inputs only. We model these in category theory via a construction taking a Cartesian category  $\mathbb{C}$ to another category
$\mathbb{C}$ to another category  $\mathrm{St}(\mathbb{C})$ with a novel trace-like operation called “delayed trace,” which misses yanking and dinaturality axioms of the usual trace. The delayed trace operation provides a feedback mechanism in
$\mathrm{St}(\mathbb{C})$ with a novel trace-like operation called “delayed trace,” which misses yanking and dinaturality axioms of the usual trace. The delayed trace operation provides a feedback mechanism in  $\mathrm{St}(\mathbb{C})$ with an implicit guardedness guarantee. When
$\mathrm{St}(\mathbb{C})$ with an implicit guardedness guarantee. When  $\mathbb{C}$ is equipped with a Cartesian differential operator, we construct a differential operator for
$\mathbb{C}$ is equipped with a Cartesian differential operator, we construct a differential operator for  $\mathrm{St}(\mathbb{C})$ using an abstract version of backpropagation through time (BPTT), a technique from machine learning based on unrolling of functions. This obtains a swath of properties for BPTT, including a chain rule and Schwartz theorem. Our differential operator is also able to compute the derivative of a stateful network without requiring the network to be unrolled.
$\mathrm{St}(\mathbb{C})$ using an abstract version of backpropagation through time (BPTT), a technique from machine learning based on unrolling of functions. This obtains a swath of properties for BPTT, including a chain rule and Schwartz theorem. Our differential operator is also able to compute the derivative of a stateful network without requiring the network to be unrolled.







Decision support for the identification of testate amoebae in microscopy images to detect peat presence in horticultural substrates
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robust machine-learned algorithms for efficient grid operation
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 22 April 2025, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The set of maximal points of an
 $\boldsymbol{\omega}$-domain need not be a
$\boldsymbol{\omega}$-domain need not be a  $\boldsymbol{G}_{\boldsymbol{\delta}}$-set
$\boldsymbol{G}_{\boldsymbol{\delta}}$-set
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e5
-
- Article
- Export citation
-
A topological space has a domain model if it is homeomorphic to the maximal point space
 $\mbox{Max}(P)$ of a domain
$\mbox{Max}(P)$ of a domain  $P$. Lawson proved that every Polish space
$P$. Lawson proved that every Polish space  $X$ has an
$X$ has an  $\omega$-domain model
$\omega$-domain model  $P$ and for such a model
$P$ and for such a model  $P$,
$P$,  $\mbox{Max}(P)$ is a
$\mbox{Max}(P)$ is a  $G_{\delta }$-set of the Scott space of
$G_{\delta }$-set of the Scott space of  $P$. Martin (2003) then asked whether it is true that for every
$P$. Martin (2003) then asked whether it is true that for every  $\omega$-domain
$\omega$-domain  $Q$,
$Q$,  $\mbox{Max}(Q)$ is
$\mbox{Max}(Q)$ is  $G_{\delta }$-set of the Scott space of
$G_{\delta }$-set of the Scott space of  $Q$. In this paper, we give a negative answer to Martin’s long-standing open problem by constructing a counterexample. The counterexample here actually shows that the answer is no even for
$Q$. In this paper, we give a negative answer to Martin’s long-standing open problem by constructing a counterexample. The counterexample here actually shows that the answer is no even for  $\omega$-algebraic domains. In addition, we also construct an
$\omega$-algebraic domains. In addition, we also construct an  $\omega$-ideal domain
$\omega$-ideal domain  $\widetilde{Q}$ for the constructed
$\widetilde{Q}$ for the constructed  $Q$ such that their maximal point spaces are homeomorphic. Therefore,
$Q$ such that their maximal point spaces are homeomorphic. Therefore,  $\textrm{Max}(Q)$ is a
$\textrm{Max}(Q)$ is a  $G_\delta$-set of the Scott space of the new model
$G_\delta$-set of the Scott space of the new model  $\widetilde{Q}$ .
$\widetilde{Q}$ .























A CLASSICAL-MODAL INTERPRETATION OF SMOOTH INFINITESIMAL ANALYSIS
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 21 April 2025, pp. 367-397
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Algorithmic regulation at the city level in China
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reinstating trust in elections in the era of artificial intelligence and emerging technologies
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 April 2025, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Rotation Sequences and the Theory of Vectors and Coordinates
-
- Published online:
- 17 April 2025
- Print publication:
- 24 April 2025
Leveraging causality and explainability in digital agriculture
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 17 April 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sharing photographs on social media enhances recollection of photograph-related details
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 15 April 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 12 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Advancing early warning mechanisms: an augmented intelligence-driven model for predicting multidimensional vulnerability levels in Afghanistan – CORRIGENDUM
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 14 April 2025, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exponentially preferential trees
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 14 April 2025, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce the exponentially preferential recursive tree and study some properties related to the degree profile of nodes in the tree. The definition of the tree involves a radix
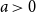 $a\gt 0$. In a tree of size
$a\gt 0$. In a tree of size  $n$ (nodes), the nodes are labeled with the numbers
$n$ (nodes), the nodes are labeled with the numbers 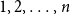 $1,2, \ldots ,n$. The node labeled
$1,2, \ldots ,n$. The node labeled 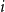 $i$ attracts the future entrant
$i$ attracts the future entrant 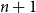 $n+1$ with probability proportional to
$n+1$ with probability proportional to 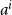 $a^i$.
$a^i$.We dedicate an early section for algorithms to generate and visualize the trees in different regimes. We study the asymptotic distribution of the outdegree of node
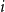 $i$, as
$i$, as 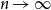 $n\to \infty$, and find three regimes according to whether
$n\to \infty$, and find three regimes according to whether 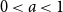 $0 \lt a \lt 1$ (subcritical regime),
$0 \lt a \lt 1$ (subcritical regime), 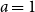 $a=1$ (critical regime), or
$a=1$ (critical regime), or 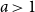 $a\gt 1$ (supercritical regime). Within any regime, there are also phases depending on a delicate interplay between
$a\gt 1$ (supercritical regime). Within any regime, there are also phases depending on a delicate interplay between 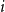 $i$ and
$i$ and  $n$, ramifying the asymptotic distribution within the regime into “early,” “intermediate” and “late” phases. In certain phases of certain regimes, we find asymptotic Gaussian laws. In certain phases of some other regimes, small oscillations in the asymototic laws are detected by the Poisson approximation techniques.
$n$, ramifying the asymptotic distribution within the regime into “early,” “intermediate” and “late” phases. In certain phases of certain regimes, we find asymptotic Gaussian laws. In certain phases of some other regimes, small oscillations in the asymototic laws are detected by the Poisson approximation techniques.

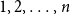
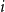
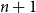
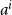
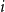
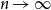
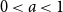
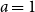
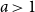
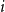

Historical review of 40 years of Robotica and its way ahead
- Part of
-
- Article
-
- You have access
- HTML
- Export citation
ROB volume 42 issue 12 Cover and Front matter
-
- Article
-
- You have access
- Export citation
A design method for tendon-driven serial manipulators using controllable block triangular form of structure null space matrix
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
