Refine search
Actions for selected content:
48285 results in Computer Science
Single-class genera of positive integral lattices
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 August 2013, pp. 172-186
-
- Article
-
- You have access
- Export citation
-
We give an enumeration of all positive definite primitive
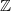 $ \mathbb{Z} $ -lattices in dimension
$ \mathbb{Z} $ -lattices in dimension 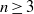 $n\geq 3$ whose genus consists of a single isometry class. This is achieved by using bounds obtained from the Smith–Minkowski–Siegel mass formula to computationally construct the square-free determinant lattices with this property, and then repeatedly calculating pre-images under a mapping first introduced by G. L. Watson.
$n\geq 3$ whose genus consists of a single isometry class. This is achieved by using bounds obtained from the Smith–Minkowski–Siegel mass formula to computationally construct the square-free determinant lattices with this property, and then repeatedly calculating pre-images under a mapping first introduced by G. L. Watson.We hereby complete the classification of single-class genera in dimensions 4 and 5 and correct some mistakes in Watson’s classifications in other dimensions. A list of all single-class primitive
 $ \mathbb{Z} $ -lattices has been compiled and incorporated into the Catalogue of Lattices.
$ \mathbb{Z} $ -lattices has been compiled and incorporated into the Catalogue of Lattices.
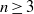
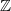
Explicit application of Waldspurger’s theorem
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 August 2013, pp. 216-245
-
- Article
-
- You have access
- Export citation
-
For a given cusp form
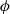 $\phi $ of even integral weight satisfying certain hypotheses, Waldspurger’s theorem relates the critical value of the
$\phi $ of even integral weight satisfying certain hypotheses, Waldspurger’s theorem relates the critical value of the  $\mathrm{L} $ -function of the
$\mathrm{L} $ -function of the 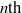 $n\mathrm{th} $ quadratic twist of
$n\mathrm{th} $ quadratic twist of 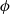 $\phi $ to the
$\phi $ to the 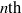 $n\mathrm{th} $ coefficient of a certain modular form of half-integral weight. Waldspurger’s recipes for these modular forms of half-integral weight are far from being explicit. In particular, they are expressed in the language of automorphic representations and Hecke characters. We translate these recipes into congruence conditions involving easily computable values of Dirichlet characters. We illustrate the practicality of our ‘simplified Waldspurger’ by giving several examples.
$n\mathrm{th} $ coefficient of a certain modular form of half-integral weight. Waldspurger’s recipes for these modular forms of half-integral weight are far from being explicit. In particular, they are expressed in the language of automorphic representations and Hecke characters. We translate these recipes into congruence conditions involving easily computable values of Dirichlet characters. We illustrate the practicality of our ‘simplified Waldspurger’ by giving several examples.
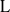
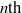
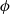
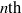
Computing level one Hecke eigensystems (mod
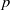 $p$ )
$p$ )
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 August 2013, pp. 246-270
-
- Article
-
- You have access
- Export citation
-
We describe an algorithm for enumerating the set of level one systems of Hecke eigenvalues arising from modular forms (mod
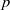 $p$ ).
$p$ ).
Modular subgroups, dessins d’enfants and elliptic K3 surfaces
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 August 2013, pp. 271-318
-
- Article
-
- You have access
- Export citation
-
We consider the 33 conjugacy classes of genus zero, torsion-free modular subgroups, computing ramification data and Grothendieck’s dessins d’enfants. In the particular case of the index 36 subgroups, the corresponding Calabi–Yau threefolds are identified, in analogy with the index 24 cases being associated to K3 surfaces. In a parallel vein, we study the 112 semi-stable elliptic fibrations over
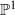 ${ \mathbb{P} }^{1} $ as extremal K3 surfaces with six singular fibres. In each case, a representative of the corresponding class of subgroups is identified by specifying a generating set for that representative.
${ \mathbb{P} }^{1} $ as extremal K3 surfaces with six singular fibres. In each case, a representative of the corresponding class of subgroups is identified by specifying a generating set for that representative.
The decomposed affiliation exposure model: A network approach to segregating peer influences from crowds and organized sports
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 154-169
-
- Article
-
- You have access
- Open access
- Export citation
Unsupervised acquisition of entailment relations from the Web
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 30 July 2013, pp. 3-47
-
- Article
- Export citation
A variable neighborhood search method for a two-mode blockmodeling problem in social network analysis
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 191-212
-
- Article
- Export citation
Diagrams in biology
-
- Journal:
- The Knowledge Engineering Review / Volume 28 / Issue 3 / September 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 273-286
-
- Article
- Export citation
Thinking through drawing: Diagram constructions as epistemic mediators in geometrical discovery
-
- Journal:
- The Knowledge Engineering Review / Volume 28 / Issue 3 / September 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 303-326
-
- Article
- Export citation
Independence-Friendly Logic: A Game-Theoretic Approach, Allen L. Mann , Gabriel Sanduand Merlijn Sevenster , Cambridge University Press, 2011. Paperback, ISBN 9780521149341, 216 pp.
-
- Journal:
- Theory and Practice of Logic Programming / Volume 14 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 30 July 2013, pp. 137-140
-
- Article
- Export citation
Engineering social contagions: Optimal network seeding in the presence of homophily
-
- Journal:
- Network Science / Volume 1 / Issue 2 / August 2013
- Published online by Cambridge University Press:
- 30 July 2013, pp. 125-153
-
- Article
-
- You have access
- Export citation
8 - Controlled Simulation Analysis
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 207-244
-
- Chapter
- Export citation
5 - Simplification Tactics
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 106-139
-
- Chapter
- Export citation
Section 2 - Harvesting Intelligence
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 61-62
-
- Chapter
- Export citation
7 - Complex Optimization
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 177-204
-
- Chapter
- Export citation
Section 3 - Leveraging Dynamic Analysis
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 205-206
-
- Chapter
- Export citation
Appendix: Shortcut (Hot Key) Reference
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 389-390
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp xi-xii
-
- Chapter
- Export citation
Glossary of Key Terms
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp 381-388
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Excel Basics to Blackbelt
- Published online:
- 05 August 2013
- Print publication:
- 29 July 2013, pp i-iv
-
- Chapter
- Export citation
