Refine search
Actions for selected content:
48585 results in Computer Science
Guest editorial preface: Software and system engineering: an ontological perspective
-
- Journal:
- The Knowledge Engineering Review / Volume 24 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 1-3
-
- Article
- Export citation
THE FINE STRUCTURE OF THE INTUITIONISTIC BOREL HIERARCHY
-
- Journal:
- The Review of Symbolic Logic / Volume 2 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 30-101
- Print publication:
- March 2009
-
- Article
- Export citation
-
In intuitionistic analysis, a subset of a Polish space like ℝ or
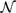 is called positively Borel if and only if it is an open subset of the space or a closed subset of the space or the result of forming either the countable union or the countable intersection of an infinite sequence of (earlier constructed) positively Borel subsets of the space. The operation of taking the complement is absent from this inductive definition, and, in fact, the complement of a positively Borel set is not always positively Borel itself (see Veldman, 2008a). The main result of Veldman (2008a) is that, assuming Brouwer's Continuity Principle and an Axiom of Countable Choice, one may prove that the hierarchy formed by the positively Borel sets is genuinely growing: every level of the hierarchy contains sets that do not occur at any lower level. The purpose of the present paper is a different one: we want to explore the truly remarkable fine structure of the hierarchy. Brouwer's Continuity Principle again is our main tool. A second axiom proposed by Brouwer, his Thesis on Bars is also used, but only incidentally.
is called positively Borel if and only if it is an open subset of the space or a closed subset of the space or the result of forming either the countable union or the countable intersection of an infinite sequence of (earlier constructed) positively Borel subsets of the space. The operation of taking the complement is absent from this inductive definition, and, in fact, the complement of a positively Borel set is not always positively Borel itself (see Veldman, 2008a). The main result of Veldman (2008a) is that, assuming Brouwer's Continuity Principle and an Axiom of Countable Choice, one may prove that the hierarchy formed by the positively Borel sets is genuinely growing: every level of the hierarchy contains sets that do not occur at any lower level. The purpose of the present paper is a different one: we want to explore the truly remarkable fine structure of the hierarchy. Brouwer's Continuity Principle again is our main tool. A second axiom proposed by Brouwer, his Thesis on Bars is also used, but only incidentally.
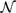 is called
is called Line-of-Sight Percolation
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 83-106
-
- Article
- Export citation
-
Given ω ≥ 1, let
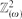 be the graph with vertex set
be the graph with vertex set 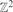 in which two vertices are joined if they agree in one coordinate and differ by at most ω in the other. (Thus
in which two vertices are joined if they agree in one coordinate and differ by at most ω in the other. (Thus 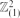 is precisely .) Let pc(ω) be the critical probability for site percolation on . Extending recent results of Frieze, Kleinberg, Ravi and Debany, we show that limω→∞ωpc(ω)=log(3/2). We also prove analogues of this result for the n-by-n grid and in higher dimensions, the latter involving interesting connections to Gilbert's continuum percolation model. To prove our results, we explore the component of the origin in a certain non-standard way, and show that this exploration is well approximated by a certain branching random walk.
is precisely .) Let pc(ω) be the critical probability for site percolation on . Extending recent results of Frieze, Kleinberg, Ravi and Debany, we show that limω→∞ωpc(ω)=log(3/2). We also prove analogues of this result for the n-by-n grid and in higher dimensions, the latter involving interesting connections to Gilbert's continuum percolation model. To prove our results, we explore the component of the origin in a certain non-standard way, and show that this exploration is well approximated by a certain branching random walk.
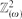 be the graph with vertex set
be the graph with vertex set 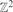 in which two vertices are joined if they agree in one coordinate and differ by at most ω in the other. (Thus
in which two vertices are joined if they agree in one coordinate and differ by at most ω in the other. (Thus 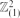 is precisely
is precisely RSL volume 2 issue 1 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 2 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 28 May 2009, pp. f1-f4
- Print publication:
- March 2009
-
- Article
-
- You have access
- Export citation
Programming Erlang – Software for a Concurrent World by Joe Armstrong, Pragmatic Bookshelf, 2007, p. 536. ISBN-10: 193435600X.
-
- Journal:
- Journal of Functional Programming / Volume 19 / Issue 2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 259-261
-
- Article
-
- You have access
- Export citation
A semantic web environment for components
-
- Journal:
- The Knowledge Engineering Review / Volume 24 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 59-75
-
- Article
- Export citation
The Probability That a Random Multigraph is Simple
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 205-225
-
- Article
- Export citation
-
Consider a random multigraph G* with given vertex degrees d1,. . .,dn, constructed by the configuration model. We show that, asymptotically for a sequence of such multigraphs with the number of edges
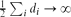 , the probability that the multigraph is simple stays away from 0 if and only if
, the probability that the multigraph is simple stays away from 0 if and only if 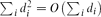 . This was previously known only under extra assumptions on the maximum degree maxidi. We also give an asymptotic formula for this probability, extending previous results by several authors.
. This was previously known only under extra assumptions on the maximum degree maxidi. We also give an asymptotic formula for this probability, extending previous results by several authors.
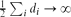 , the probability that the multigraph is simple stays away from 0 if and only if
, the probability that the multigraph is simple stays away from 0 if and only if 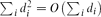 . This was previously known only under extra assumptions on the maximum degree max
. This was previously known only under extra assumptions on the maximum degree maxRELEVANCE LOGICS AND RELATION ALGEBRAS
-
- Journal:
- The Review of Symbolic Logic / Volume 2 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 102-131
- Print publication:
- March 2009
-
- Article
- Export citation
RSL volume 2 issue 1 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 2 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 28 May 2009, pp. b1-b2
- Print publication:
- March 2009
-
- Article
-
- You have access
- Export citation
FUNCTIONAL PEARL. Proof-directed debugging – Corrigendum
-
- Journal:
- Journal of Functional Programming / Volume 19 / Issue 2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, p. 262
-
- Article
-
- You have access
- Export citation
CPC volume 18 issue 1 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Deterministic Random Walks on the Two-Dimensional Grid
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 123-144
-
- Article
- Export citation
Majority Bootstrap Percolation on the Hypercube
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 17-51
-
- Article
- Export citation
JFP volume 19 issue 2 Cover and Back matter
-
- Journal:
- Journal of Functional Programming / Volume 19 / Issue 2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Type-safe pattern combinators
-
- Journal:
- Journal of Functional Programming / Volume 19 / Issue 2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 145-156
-
- Article
-
- You have access
- Export citation
KER volume 24 issue 1 Cover and Front matter
-
- Journal:
- The Knowledge Engineering Review / Volume 24 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. f1-f2
-
- Article
-
- You have access
- Export citation
MATRIX-BASED LOGIC FOR APPLICATION IN PHYSICS
-
- Journal:
- The Review of Symbolic Logic / Volume 2 / Issue 1 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 132-163
- Print publication:
- March 2009
-
- Article
- Export citation
CPC volume 18 issue 1 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. b1-b6
-
- Article
-
- You have access
- Export citation
Perturbed Identity Matrices Have High Rank: Proof and Applications
-
- Journal:
- Combinatorics, Probability and Computing / Volume 18 / Issue 1-2 / March 2009
- Published online by Cambridge University Press:
- 01 March 2009, pp. 3-15
-
- Article
- Export citation
