Refine search
Actions for selected content:
48581 results in Computer Science
ERRATUM
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 3 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, p. 393
- Print publication:
- October 2008
-
- Article
-
- You have access
- Export citation
Strengths and weaknesses of finite-state technology: a case study in morphological grammar development
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 457-469
-
- Article
- Export citation
Exponentiable morphisms of domains
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 1005-1016
-
- Article
- Export citation
Type-based flow analysis and context-free language reachability
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 823-894
-
- Article
- Export citation
BELIEF REVISION IN NON-CLASSICAL LOGICS
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 3 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 267-304
- Print publication:
- October 2008
-
- Article
- Export citation
-
In this article, we propose a belief revision approach for families of (non-classical) logics whose semantics are first-order axiomatisable. Given any such (non-classical) logic
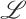 , the approach enables the definition of belief revision operators for
, the approach enables the definition of belief revision operators for 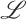 , in terms of a belief revision operation satisfying the postulates for revision theory proposed by Alchourrón, Gärdenfors and Makinson (AGM revision, Alchourrón et al. (1985)). The approach is illustrated by considering the modal logic K, Belnap's four-valued logic, and Łukasiewicz's many-valued logic. In addition, we present a general methodology to translate algebraic logics into classical logic. For the examples provided, we analyse in what circumstances the properties of the AGM revision are preserved and discuss the advantages of the approach from both theoretical and practical viewpoints.
, in terms of a belief revision operation satisfying the postulates for revision theory proposed by Alchourrón, Gärdenfors and Makinson (AGM revision, Alchourrón et al. (1985)). The approach is illustrated by considering the modal logic K, Belnap's four-valued logic, and Łukasiewicz's many-valued logic. In addition, we present a general methodology to translate algebraic logics into classical logic. For the examples provided, we analyse in what circumstances the properties of the AGM revision are preserved and discuss the advantages of the approach from both theoretical and practical viewpoints.
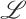 , the approach enables the definition of belief revision operators for
, the approach enables the definition of belief revision operators for 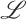 , in terms of a belief revision operation satisfying the postulates for revision theory proposed by Alchourrón, Gärdenfors and Makinson (AGM revision, Alchourrón
, in terms of a belief revision operation satisfying the postulates for revision theory proposed by Alchourrón, Gärdenfors and Makinson (AGM revision, Alchourrón Theory and applications of subtyping: Introduction
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 795-796
-
- Article
- Export citation
Graph lambda theories†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 975-1004
-
- Article
- Export citation
A structural approach to the automatic adjudication of word sense disagreements
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 547-573
-
- Article
- Export citation
Polarised subtyping for sized types
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 797-822
-
- Article
- Export citation
Structural subtyping for inductive types with functorial equality rules†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 18 / Issue 5 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 931-972
-
- Article
- Export citation
Automatic generation of weather forecast texts using comprehensive probabilistic generation-space models
-
- Journal:
- Natural Language Engineering / Volume 14 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 431-455
-
- Article
- Export citation
THE IDENTITY OF ARGUMENT-PLACES
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 3 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 335-354
- Print publication:
- October 2008
-
- Article
- Export citation
CUMULATIVITY WITHOUT CLOSURE OF THE DOMAIN UNDER FINITE UNIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 1 / Issue 3 / October 2008
- Published online by Cambridge University Press:
- 01 October 2008, pp. 372-392
- Print publication:
- October 2008
-
- Article
- Export citation
INFINITE-SERVER QUEUES WITH SYSTEM'S ADDITIONAL TASKS AND IMPATIENT CUSTOMERS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 22 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 25 September 2008, pp. 477-493
-
- Article
- Export citation
POLLING SYSTEMS WITH TWO-PHASE GATED SERVICE: HEAVY TRAFFIC RESULTS FOR THE WAITING TIME DISTRIBUTION
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 22 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 25 September 2008, pp. 623-651
-
- Article
- Export citation
RETRIAL NETWORKS WITH FINITE BUFFERS AND THEIR APPLICATION TO INTERNET DATA TRAFFIC
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 22 / Issue 4 / October 2008
- Published online by Cambridge University Press:
- 25 September 2008, pp. 519-536
-
- Article
- Export citation
