Refine search
Actions for selected content:
49522 results in Computer Science
7 - Artificial Intelligence Arms Races as Innovation Contests
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 199-222
-
- Chapter
- Export citation
Countability constraints in order-theoretic approaches to computability
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 6 / June 2024
- Published online by Cambridge University Press:
- 30 May 2024, pp. 491-528
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
About the Authors
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp xiii-xiv
-
- Chapter
- Export citation
Counting spanning subgraphs in dense hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 30 May 2024, pp. 729-741
-
- Article
- Export citation
-
We give a simple method to estimate the number of distinct copies of some classes of spanning subgraphs in hypergraphs with a high minimum degree. In particular, for each
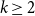 $k\geq 2$ and
$k\geq 2$ and 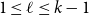 $1\leq \ell \leq k-1$, we show that every
$1\leq \ell \leq k-1$, we show that every 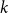 $k$-graph on
$k$-graph on  $n$ vertices with minimum codegree at leastcontains
$n$ vertices with minimum codegree at leastcontains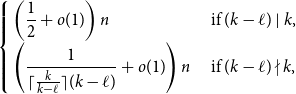 \begin{equation*} \left \{\begin {array}{l@{\quad}l} \left (\dfrac {1}{2}+o(1)\right )n & \text { if }(k-\ell )\mid k,\\[5pt] \left (\dfrac {1}{\lceil \frac {k}{k-\ell }\rceil (k-\ell )}+o(1)\right )n & \text { if }(k-\ell )\nmid k, \end {array} \right . \end{equation*}
\begin{equation*} \left \{\begin {array}{l@{\quad}l} \left (\dfrac {1}{2}+o(1)\right )n & \text { if }(k-\ell )\mid k,\\[5pt] \left (\dfrac {1}{\lceil \frac {k}{k-\ell }\rceil (k-\ell )}+o(1)\right )n & \text { if }(k-\ell )\nmid k, \end {array} \right . \end{equation*}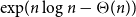 $\exp\!(n\log n-\Theta (n))$ Hamilton
$\exp\!(n\log n-\Theta (n))$ Hamilton 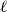 $\ell$-cycles as long as
$\ell$-cycles as long as 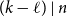 $(k-\ell )\mid n$. When
$(k-\ell )\mid n$. When 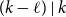 $(k-\ell )\mid k$, this gives a simple proof of a result of Glock, Gould, Joos, Kühn, and Osthus, while when
$(k-\ell )\mid k$, this gives a simple proof of a result of Glock, Gould, Joos, Kühn, and Osthus, while when 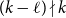 $(k-\ell )\nmid k$, this gives a weaker count than that given by Ferber, Hardiman, and Mond, or when
$(k-\ell )\nmid k$, this gives a weaker count than that given by Ferber, Hardiman, and Mond, or when 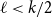 $\ell \lt k/2$, by Ferber, Krivelevich, and Sudakov, but one that holds for an asymptotically optimal minimum codegree bound.
$\ell \lt k/2$, by Ferber, Krivelevich, and Sudakov, but one that holds for an asymptotically optimal minimum codegree bound.
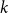

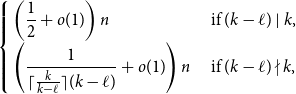
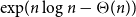
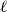
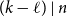
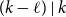
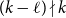
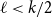
Contents
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp v-x
-
- Chapter
- Export citation
3 - Artificial Intelligence and the Economics of Decision-Making
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 60-82
-
- Chapter
- Export citation
9 - Artificial Intelligence, Big Data, and Public Policy
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 256-268
-
- Chapter
- Export citation
2 - Artificial Intelligence and Economics
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 22-59
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 1-21
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 315-353
-
- Chapter
- Export citation
5 - Artificial Intelligence, Growth, and Inequality
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 107-172
-
- Chapter
- Export citation
10 - The Future of Artificial Intelligence and Implications for Economics
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 269-314
-
- Chapter
- Export citation
Tables
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp xii-xii
-
- Chapter
- Export citation
Preface
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp xv-xvi
-
- Chapter
- Export citation
Figures
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp xi-xi
-
- Chapter
- Export citation
Index
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 354-360
-
- Chapter
- Export citation
A generalisation of Varnavides’s theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 29 May 2024, pp. 724-728
-
- Article
- Export citation
-
A linear equation
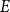 $E$ is said to be sparse if there is
$E$ is said to be sparse if there is 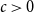 $c\gt 0$ so that every subset of
$c\gt 0$ so that every subset of 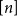 $[n]$ of size
$[n]$ of size 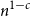 $n^{1-c}$ contains a solution of
$n^{1-c}$ contains a solution of 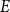 $E$ in distinct integers. The problem of characterising the sparse equations, first raised by Ruzsa in the 90s, is one of the most important open problems in additive combinatorics. We say that
$E$ in distinct integers. The problem of characterising the sparse equations, first raised by Ruzsa in the 90s, is one of the most important open problems in additive combinatorics. We say that 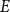 $E$ in
$E$ in 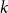 $k$ variables is abundant if every subset of
$k$ variables is abundant if every subset of 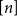 $[n]$ of size
$[n]$ of size 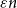 $\varepsilon n$ contains at least
$\varepsilon n$ contains at least 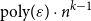 $\text{poly}(\varepsilon )\cdot n^{k-1}$ solutions of
$\text{poly}(\varepsilon )\cdot n^{k-1}$ solutions of 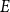 $E$. It is clear that every abundant
$E$. It is clear that every abundant 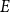 $E$ is sparse, and Girão, Hurley, Illingworth, and Michel asked if the converse implication also holds. In this note, we show that this is the case for every
$E$ is sparse, and Girão, Hurley, Illingworth, and Michel asked if the converse implication also holds. In this note, we show that this is the case for every 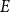 $E$ in four variables. We further discuss a generalisation of this problem which applies to all linear equations.
$E$ in four variables. We further discuss a generalisation of this problem which applies to all linear equations.
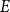
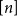
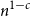
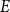
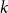
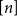
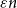
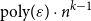
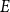
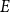
RSL volume 17 issue 2 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 May 2024, pp. f1-f4
- Print publication:
- June 2024
-
- Article
-
- You have access
- Export citation
RSL volume 17 issue 2 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 May 2024, pp. b1-b2
- Print publication:
- June 2024
-
- Article
-
- You have access
- Export citation
