Refine search
Actions for selected content:
49522 results in Computer Science
Incorporating changeability for value-robust product-service systems: an integrative review
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 12 March 2024, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dimension in team semantics
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 5 / May 2024
- Published online by Cambridge University Press:
- 12 March 2024, pp. 410-454
-
- Article
- Export citation
-
We introduce three measures of complexity for families of sets. Each of the three measures, which we call dimensions, is defined in terms of the minimal number of convex subfamilies that are needed for covering the given family. For upper dimension, the subfamilies are required to contain a unique maximal set, for dual upper dimension a unique minimal set, and for cylindrical dimension both a unique maximal and a unique minimal set. In addition to considering dimensions of particular families of sets, we study the behavior of dimensions under operators that map families of sets to new families of sets. We identify natural sufficient criteria for such operators to preserve the growth class of the dimensions. We apply the theory of our dimensions for proving new hierarchy results for logics with team semantics. To this end we associate each atom with a natural notion or arity. First, we show that the standard logical operators preserve the growth classes of the families arising from the semantics of formulas in such logics. Second, we show that the upper dimension of
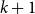 $k+1$-ary dependence, inclusion, independence, anonymity, and exclusion atoms is in a strictly higher growth class than that of any k-ary atoms, whence the
$k+1$-ary dependence, inclusion, independence, anonymity, and exclusion atoms is in a strictly higher growth class than that of any k-ary atoms, whence the 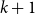 $k+1$-ary atoms are not definable in terms of any atoms of smaller arity.
$k+1$-ary atoms are not definable in terms of any atoms of smaller arity.
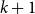
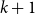
A generalized hypothesis test for community structure in networks
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 11 March 2024, pp. 122-138
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tattoos embody autobiographical memories
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 3 / 2024
- Published online by Cambridge University Press:
- 11 March 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Selected Papers from the 5th International Joint Conference on Rules and Reasoning (RuleML+RR 2021)
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 08 March 2024, pp. 310-312
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Methodological moderators of average outdegree centrality: A meta-analysis of child and adolescent friendship networks
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 08 March 2024, pp. 107-121
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - Examples Using More-of-the-Input Loop Invariants
- from Part I - Iterative Algorithms and Loop Invariants
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 33-46
-
- Chapter
- Export citation
Multitask feature selection within structural datasets
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 07 March 2024, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
27 - Solution Is a Tree
- from Part III - Optimization Problems
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 390-401
-
- Chapter
- Export citation
39 - Recurrence Relations
- from Part IV - Additional Topics
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 540-548
-
- Chapter
- Export citation
35 - Time Complexity
- from Part IV - Additional Topics
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 508-514
-
- Chapter
- Export citation
42 - Partial Solutions to Additional Exercises: Part IV
- from Part IV - Additional Topics
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 556-560
-
- Chapter
- Export citation
Notation
-
- Book:
- Topological Duality for Distributive Lattices
- Published online:
- 16 February 2024
- Print publication:
- 07 March 2024, pp 339-345
-
- Chapter
- Export citation
7 - The Loop Invariant for Lower Bounds
- from Part I - Iterative Algorithms and Loop Invariants
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 88-96
-
- Chapter
- Export citation
37 - Asymptotic Growth
- from Part IV - Additional Topics
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 518-528
-
- Chapter
- Export citation
Part I - Iterative Algorithms and Loop Invariants
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 3-4
-
- Chapter
- Export citation
6 - More Iterative Algorithms
- from Part I - Iterative Algorithms and Loop Invariants
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 80-87
-
- Chapter
- Export citation
20 - Graph Search Algorithms
- from Part III - Optimization Problems
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp 243-267
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- How to Think about Algorithms
- Published online:
- 10 October 2024
- Print publication:
- 07 March 2024, pp i-iv
-
- Chapter
- Export citation
2 - Topology and Order
-
- Book:
- Topological Duality for Distributive Lattices
- Published online:
- 16 February 2024
- Print publication:
- 07 March 2024, pp 29-50
-
- Chapter
- Export citation
