Refine search
Actions for selected content:
48274 results in Computer Science
Argumentation models and their use in corpus annotation: Practice, prospects, and challenges
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 1150-1187
-
- Article
- Export citation
8 - Active Labour Market Programmes and Employer Engagement in the UK and Germany
-
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp 126-144
-
- Chapter
- Export citation
A new lifetime distribution by maximizing entropy: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 28 February 2023, pp. 189-206
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
List of Figures and Tables
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp v-vi
-
- Chapter
- Export citation
List of Abbreviations
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp vii-viii
-
- Chapter
- Export citation
2 - Varieties of Policy Approaches to Employer Engagement in Activation Policies
-
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp 15-33
-
- Chapter
- Export citation
6 - The Weakest Link? Job Quality and Active Labour Market Policy in the UK
-
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp 87-105
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Employer Engagement
- Published by:
- Bristol University Press
- Published online:
- 18 January 2024
- Print publication:
- 28 February 2023, pp i-ii
-
- Chapter
- Export citation
Quinductor: A multilingual data-driven method for generating reading-comprehension questions using Universal Dependencies
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 27 February 2023, pp. 217-255
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Obtaining molecular hydrogen from water radiolysis in the nano-SiO2(d = 20 nm)/H2O system under the influence of γ-quanta
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE ZHOU ORDINAL OF LABELLED MARKOV PROCESSES OVER SEPARABLE SPACES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 27 February 2023, pp. 1011-1032
- Print publication:
- December 2023
-
- Article
- Export citation
-
There exist two notions of equivalence of behavior between states of a Labelled Markov Process (LMP): state bisimilarity and event bisimilarity. The first one can be considered as an appropriate generalization to continuous spaces of Larsen and Skou’s probabilistic bisimilarity, whereas the second one is characterized by a natural logic. C. Zhou expressed state bisimilarity as the greatest fixed point of an operator
 $\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of
$\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of 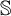 $\mathbb {S}$,
$\mathbb {S}$, 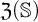 $\mathfrak {Z}(\mathbb {S})$. When
$\mathfrak {Z}(\mathbb {S})$. When 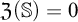 $\mathfrak {Z}(\mathbb {S})=0$,
$\mathfrak {Z}(\mathbb {S})=0$, 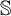 $\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP
$\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP 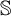 $\mathbb {S}$ with
$\mathbb {S}$ with 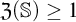 $\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs
$\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs 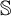 $\mathbb {S}$ over separable metrizable spaces having arbitrary large countable
$\mathbb {S}$ over separable metrizable spaces having arbitrary large countable 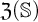 $\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of
$\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of 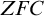 $\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.
$\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.

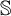
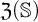
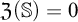
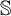
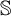
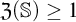
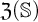
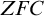
First checklist triggering the inventory of marine fish ectoparasites in the Syrian coast (Eastern Mediterranean)
-
- Journal:
- Experimental Results / Accepted manuscript
- Published online by Cambridge University Press:
- 27 February 2023, pp. 1-17
-
- Article
-
- You have access
- Open access
- Export citation
Joining forces: the value of design partnering with operational research to improve healthcare delivery
-
- Journal:
- Design Science / Volume 9 / 2023
- Published online by Cambridge University Press:
- 27 February 2023, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AXIOMS FOR TYPE-FREE SUBJECTIVE PROBABILITY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 17 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 February 2023, pp. 493-508
- Print publication:
- June 2024
-
- Article
- Export citation

Inference and Learning from Data
- Learning
-
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022
-
- Textbook
- Export citation
Chapter 9 - Hecate
- from Part III - Public Reimaginings
-
-
- Book:
- Reimagining Shakespeare Education
- Published online:
- 02 February 2023
- Print publication:
- 23 February 2023, pp 145-158
-
- Chapter
- Export citation
Introduction
- from Part IV - Digital Reimaginings
-
-
- Book:
- Reimagining Shakespeare Education
- Published online:
- 02 February 2023
- Print publication:
- 23 February 2023, pp 205-208
-
- Chapter
- Export citation
Notes on Contributors
-
- Book:
- Reimagining Shakespeare Education
- Published online:
- 02 February 2023
- Print publication:
- 23 February 2023, pp xiii-xxii
-
- Chapter
- Export citation
Chapter 7 - The Warwick–Monash Co-teaching Initiative
- from Part II - Reimagining Shakespeare with/in Universities
-
-
- Book:
- Reimagining Shakespeare Education
- Published online:
- 02 February 2023
- Print publication:
- 23 February 2023, pp 113-126
-
- Chapter
- Export citation
