Refine search
Actions for selected content:
48529 results in Computer Science
PROBABILISTIC STABILITY, AGM REVISION OPERATORS AND MAXIMUM ENTROPY
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 553-590
- Print publication:
- September 2022
-
- Article
- Export citation
On the impact of network size and average degree on the robustness of centrality measures
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 20 October 2020, pp. S61-S82
-
- Article
-
- You have access
- Open access
- Export citation

The Cambridge Handbook of the Law of Algorithms
-
- Published online:
- 19 October 2020
- Print publication:
- 05 November 2020

Wireless Edge Caching
- Modeling, Analysis, and Optimization
-
- Published online:
- 19 October 2020
- Print publication:
- 11 March 2021
Forward analysis for WSTS, part I: completions
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 7 / August 2020
- Published online by Cambridge University Press:
- 19 October 2020, pp. 752-832
-
- Article
- Export citation
Sensitivity analysis for network observations with applications to inferences of social influence effects
-
- Journal:
- Network Science / Volume 9 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 19 October 2020, pp. 73-98
-
- Article
- Export citation
From industry-wide parameters to aircraft-centric on-flight inference: Improving aeronautics performance prediction with machine learning
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 19 October 2020, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Mixing properties of colourings of the ℤd lattice
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 19 October 2020, pp. 360-373
-
- Article
- Export citation
-
We study and classify proper q-colourings of the ℤd lattice, identifying three regimes where different combinatorial behaviour holds. (1) When
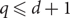 $q\le d+1$, there exist frozen colourings, that is, proper q-colourings of ℤd which cannot be modified on any finite subset. (2) We prove a strong list-colouring property which implies that, when
$q\le d+1$, there exist frozen colourings, that is, proper q-colourings of ℤd which cannot be modified on any finite subset. (2) We prove a strong list-colouring property which implies that, when 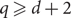 $q\ge d+2$, any proper q-colouring of the boundary of a box of side length
$q\ge d+2$, any proper q-colouring of the boundary of a box of side length 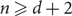 $n \ge d+2$ can be extended to a proper q-colouring of the entire box. (3) When
$n \ge d+2$ can be extended to a proper q-colouring of the entire box. (3) When 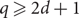 $q\geq 2d+1$, the latter holds for any
$q\geq 2d+1$, the latter holds for any 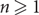 $n \ge 1$. Consequently, we classify the space of proper q-colourings of the ℤd lattice by their mixing properties.
$n \ge 1$. Consequently, we classify the space of proper q-colourings of the ℤd lattice by their mixing properties.
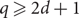
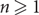
Frozen (Δ + 1)-colourings of bounded degree graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 19 October 2020, pp. 330-343
-
- Article
- Export citation
-
Let G be a graph on n vertices and with maximum degree Δ, and let k be an integer. The k-recolouring graph of G is the graph whose vertices are k-colourings of G and where two k-colourings are adjacent if they differ at exactly one vertex. It is well known that the k-recolouring graph is connected for
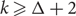 $k\geq \Delta+2$. Feghali, Johnson and Paulusma (J. Graph Theory 83 (2016) 340–358) showed that the (Δ + 1)-recolouring graph is composed by a unique connected component of size at least 2 and (possibly many) isolated vertices.
$k\geq \Delta+2$. Feghali, Johnson and Paulusma (J. Graph Theory 83 (2016) 340–358) showed that the (Δ + 1)-recolouring graph is composed by a unique connected component of size at least 2 and (possibly many) isolated vertices.In this paper, we study the proportion of isolated vertices (also called frozen colourings) in the (Δ + 1)-recolouring graph. Our first contribution is to show that if G is connected, the proportion of frozen colourings of G is exponentially smaller in n than the total number of colourings. This motivates the use of the Glauber dynamics to approximate the number of (Δ + 1)-colourings of a graph. In contrast to the conjectured mixing time of O(nlog n) for
$k\geq \Delta+2$ colours, we show that the mixing time of the Glauber dynamics for (Δ + 1)-colourings restricted to non-frozen colourings can be Ω(n2). Finally, we prove some results about the existence of graphs with large girth and frozen colourings, and study frozen colourings in random regular graphs.
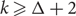
A non-increasing tree growth process for recursive trees and applications
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 19 October 2020, pp. 79-104
-
- Article
- Export citation
-
We introduce a non-increasing tree growth process
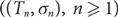 $((T_n,{\sigma}_n),\, n\ge 1)$, where Tn is a rooted labelled tree on n vertices and σn is a permutation of the vertex labels. The construction of (Tn, σn) from (Tn−1, σn−1) involves rewiring a random (possibly empty) subset of edges in Tn−1 towards the newly added vertex; as a consequence Tn−1 ⊄ Tn with positive probability. The key feature of the process is that the shape of Tn has the same law as that of a random recursive tree, while the degree distribution of any given vertex is not monotone in the process.
$((T_n,{\sigma}_n),\, n\ge 1)$, where Tn is a rooted labelled tree on n vertices and σn is a permutation of the vertex labels. The construction of (Tn, σn) from (Tn−1, σn−1) involves rewiring a random (possibly empty) subset of edges in Tn−1 towards the newly added vertex; as a consequence Tn−1 ⊄ Tn with positive probability. The key feature of the process is that the shape of Tn has the same law as that of a random recursive tree, while the degree distribution of any given vertex is not monotone in the process.We present two applications. First, while couplings between Kingman’s coalescent and random recursive trees were known for any fixed n, this new process provides a non-standard coupling of all finite Kingman’s coalescents. Second, we use the new process and the Chen–Stein method to extend the well-understood properties of degree distribution of random recursive trees to extremal-range cases. Namely, we obtain convergence rates on the number of vertices with degree at least
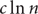 $c\ln n$, c ∈ (1, 2), in trees with n vertices. Further avenues of research are discussed.
$c\ln n$, c ∈ (1, 2), in trees with n vertices. Further avenues of research are discussed.
Isolation concepts applied to temporal clique enumeration
-
- Journal:
- Network Science / Volume 9 / Issue S1 / October 2021
- Published online by Cambridge University Press:
- 16 October 2020, pp. S83-S105
-
- Article
- Export citation
Enhancing industrial X-ray tomography by data-centric statistical methods
-
- Journal:
- Data-Centric Engineering / Volume 1 / 2020
- Published online by Cambridge University Press:
- 16 October 2020, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Document Sentiment Classification
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 55-88
-
- Chapter
- Export citation
9 - A Framework for Cyber-Physical System Security Situation Awareness
- from Part III - Privacy, Security, and Protection
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 229-251
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 376-426
-
- Chapter
- Export citation
Preface
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp xi-xv
-
- Chapter
- Export citation
Contents
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp v-xii
-
- Chapter
- Export citation
10 - Analysis of Debates and Comments
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 273-293
-
- Chapter
- Export citation
