Refine search
Actions for selected content:
48532 results in Computer Science
Effect of Rinsing Canned Foods on Bisphenol-A Exposure: The Hummus Experiment
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 15 October 2020, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
14 - In Silico and In Vitro Modeling Platforms for Stimulation of Emergent Processes in Neuronal Networks
- from Part IV - Frameworks and Testbeds
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 387-414
-
- Chapter
- Export citation
Independent dominating sets in graphs of girth five
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 15 October 2020, pp. 344-359
-
- Article
- Export citation
-
Let
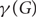 $\gamma(G)$ and
$\gamma(G)$ and 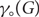 $${\gamma _ \circ }(G)$$ denote the sizes of a smallest dominating set and smallest independent dominating set in a graph G, respectively. One of the first results in probabilistic combinatorics is that if G is an n-vertex graph of minimum degree at least d, then
$${\gamma _ \circ }(G)$$ denote the sizes of a smallest dominating set and smallest independent dominating set in a graph G, respectively. One of the first results in probabilistic combinatorics is that if G is an n-vertex graph of minimum degree at least d, then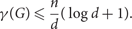 $$\begin{equation}\gamma(G) \leq \frac{n}{d}(\log d + 1).\end{equation}$$
$$\begin{equation}\gamma(G) \leq \frac{n}{d}(\log d + 1).\end{equation}$$In this paper the main result is that if G is any n-vertex d-regular graph of girth at least five, then
for some constant c independent of d. This result is sharp in the sense that as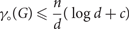 $$\begin{equation}\gamma_(G) \leq \frac{n}{d}(\log d + c)\end{equation}$$
$$\begin{equation}\gamma_(G) \leq \frac{n}{d}(\log d + c)\end{equation}$$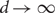 $d \rightarrow \infty$, almost all d-regular n-vertex graphs G of girth at least five have
$d \rightarrow \infty$, almost all d-regular n-vertex graphs G of girth at least five have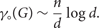 $$\begin{equation}\gamma_(G) \sim \frac{n}{d}\log d.\end{equation}$$
$$\begin{equation}\gamma_(G) \sim \frac{n}{d}\log d.\end{equation}$$Furthermore, if G is a disjoint union of
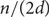 ${n}/{(2d)}$ complete bipartite graphs
${n}/{(2d)}$ complete bipartite graphs 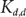 $K_{d,d}$, then
$K_{d,d}$, then 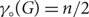 ${\gamma_\circ}(G) = \frac{n}{2}$. We also prove that there are n-vertex graphs G of minimum degree d and whose maximum degree grows not much faster than d log d such that
${\gamma_\circ}(G) = \frac{n}{2}$. We also prove that there are n-vertex graphs G of minimum degree d and whose maximum degree grows not much faster than d log d such that 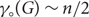 ${\gamma_\circ}(G) \sim {n}/{2}$ as
${\gamma_\circ}(G) \sim {n}/{2}$ as 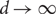 $d \rightarrow \infty$. Therefore both the girth and regularity conditions are required for the main result.
$d \rightarrow \infty$. Therefore both the girth and regularity conditions are required for the main result.
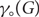
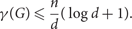
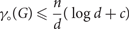
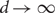
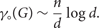
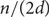
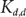
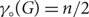
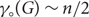
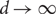
2 - The Problem of Sentiment Analysis
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 18-54
-
- Chapter
- Export citation
13 - Middleware for the Internet of Things
- from Part IV - Frameworks and Testbeds
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 363-386
-
- Chapter
- Export citation
List of Contributors
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp xiii-xviii
-
- Chapter
- Export citation
1 - From Physical Processes to Theoretical Foundations of Cyber-Physical Systems Design and Optimization
- from Part I - Overcoming Uncertainty
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 3-24
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 1-17
-
- Chapter
- Export citation
Appendix
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 365-375
-
- Chapter
- Export citation
Preface
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp xix-xxii
-
- Chapter
- Export citation
Part III - Privacy, Security, and Protection
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 207-208
-
- Chapter
- Export citation
14 - Conclusion
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 360-364
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp iv-iv
-
- Chapter
- Export citation
Contents
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp v-x
-
- Chapter
- Export citation
12 - Detecting Fake or Deceptive Opinions
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 304-353
-
- Chapter
- Export citation
7 - Meanings and Applications of Structure in Networks of Dynamic Systems
- from Part II - Exploiting Structure for Control
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 162-206
-
- Chapter
- Export citation
2 - Effective Uncertainty Evaluation in Large-Scale Systems
- from Part I - Overcoming Uncertainty
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 25-50
-
- Chapter
- Export citation
15 - Wide-Area Management of Cyber-Physical Infrastructures: A Call to Action
- from Part V - Conclusion
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 417-435
-
- Chapter
- Export citation
5 - Joint Scheduling and Optimal Adaptive Event-Triggered Control of Distributed Cyber-Physical Systems
- from Part II - Exploiting Structure for Control
-
- Book:
- Principles of Cyber-Physical Systems
- Published online:
- 12 October 2020
- Print publication:
- 15 October 2020, pp 104-126
-
- Chapter
- Export citation
4 - Sentence Subjectivity and Sentiment Classification
-
- Book:
- Sentiment Analysis
- Published online:
- 23 September 2020
- Print publication:
- 15 October 2020, pp 89-114
-
- Chapter
- Export citation
