Refine search
Actions for selected content:
48529 results in Computer Science
ROB volume 38 issue 11 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ROB volume 38 issue 11 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Structures of an extradiol catechol dioxygenase – C23O64, from 3-nitrotoluene degrading Diaphorobacter sp. strain DS2 in substrate-free, substrate-bound and substrate analog-bound states
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 26 October 2020, e48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modal descent
-
- Journal:
- Mathematical Structures in Computer Science / Volume 31 / Issue 4 / April 2021
- Published online by Cambridge University Press:
- 26 October 2020, pp. 363-391
-
- Article
- Export citation
-
Any modality in homotopy type theory gives rise to an orthogonal factorization system of which the left class is stable under pullbacks. We show that there is a second orthogonal factorization system associated with any modality, of which the left class is the class of ○-equivalences and the right class is the class of ○-étale maps. This factorization system is called the modal reflective factorization system of a modality, and we give a precise characterization of the orthogonal factorization systems that arise as the modal reflective factorization system of a modality. In the special case of the n-truncation, the modal reflective factorization system has a simple description: we show that the n-étale maps are the maps that are right orthogonal to the map
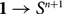 $${\rm{1}} \to {\rm{ }}{{\rm{S}}^{n + 1}}$$. We use the ○-étale maps to prove a modal descent theorem: a map with modal fibers into ○X is the same thing as a ○-étale map into a type X. We conclude with an application to real-cohesive homotopy type theory and remark how ○-étale maps relate to the formally etale maps from algebraic geometry.
$${\rm{1}} \to {\rm{ }}{{\rm{S}}^{n + 1}}$$. We use the ○-étale maps to prove a modal descent theorem: a map with modal fibers into ○X is the same thing as a ○-étale map into a type X. We conclude with an application to real-cohesive homotopy type theory and remark how ○-étale maps relate to the formally etale maps from algebraic geometry.
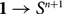
A simplified disproof of Beck’s three permutations conjecture and an application to root-mean-squared discrepancy
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 30 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 26 October 2020, pp. 398-411
-
- Article
- Export citation
-
A k-permutation family on n vertices is a set-system consisting of the intervals of k permutations of the integers 1 to n. The discrepancy of a set-system is the minimum over all red–blue vertex colourings of the maximum difference between the number of red and blue vertices in any set in the system. In 2011, Newman and Nikolov disproved a conjecture of Beck that the discrepancy of any 3-permutation family is at most a constant independent of n. Here we give a simpler proof that Newman and Nikolov’s sequence of 3-permutation families has discrepancy
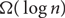 $\Omega (\log \,n)$. We also exhibit a sequence of 6-permutation families with root-mean-squared discrepancy
$\Omega (\log \,n)$. We also exhibit a sequence of 6-permutation families with root-mean-squared discrepancy 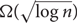 $\Omega (\sqrt {\log \,n} )$; that is, in any red–blue vertex colouring, the square root of the expected squared difference between the number of red and blue vertices in an interval of the system is $\Omega (\sqrt {\log \,n} )$.
$\Omega (\sqrt {\log \,n} )$; that is, in any red–blue vertex colouring, the square root of the expected squared difference between the number of red and blue vertices in an interval of the system is $\Omega (\sqrt {\log \,n} )$.
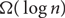
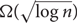
Greater autism knowledge and contact with autistic people are independently associated with favourable attitudes towards autistic people
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 23 October 2020, e46
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Nanoparticle Interactions and Molecular Relaxation in PLA/PBAT/Nanoclay Blends
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 23 October 2020, e47
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Small Summaries for Big Data
-
- Published online:
- 22 October 2020
- Print publication:
- 12 November 2020
PES volume 34 issue 4 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 4 / October 2020
- Published online by Cambridge University Press:
- 22 October 2020, pp. f1-f2
-
- Article
-
- You have access
- Export citation
PES volume 34 issue 4 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 4 / October 2020
- Published online by Cambridge University Press:
- 22 October 2020, pp. b1-b2
-
- Article
-
- You have access
- Export citation
DOING WITHOUT ACTION TYPES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 380-410
- Print publication:
- June 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of population functional connectivity data via multilayer network embeddings
-
- Journal:
- Network Science / Volume 9 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 99-122
-
- Article
- Export citation
SUPPORT FOR GEOMETRIC POOLING
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 21 October 2020, pp. 298-337
- Print publication:
- March 2023
-
- Article
- Export citation
EXPLORING THE LANDSCAPE OF RELATIONAL SYLLOGISTIC LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 728-765
- Print publication:
- September 2021
-
- Article
- Export citation
SEMANTICS FOR PURE THEORIES OF CONNEXIVE IMPLICATION
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 591-606
- Print publication:
- September 2022
-
- Article
- Export citation
KOLMOGOROV CONDITIONALIZERS CAN BE DUTCH BOOKED (IF AND ONLY IF THEY ARE EVIDENTIALLY UNCERTAIN)
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 October 2020, pp. 722-757
- Print publication:
- September 2022
-
- Article
- Export citation
TRACTARIAN LOGICISM: OPERATIONS, NUMBERS, INDUCTION
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 973-1010
- Print publication:
- December 2021
-
- Article
- Export citation
-
In his Tractatus, Wittgenstein maintained that arithmetic consists of equations arrived at by the practice of calculating outcomes of operations
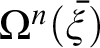 $\Omega ^{n}(\bar {\xi })$ defined with the help of numeral exponents. Since
$\Omega ^{n}(\bar {\xi })$ defined with the help of numeral exponents. Since 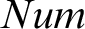 $Num$(x) and quantification over numbers seem ill-formed, Ramsey wrote that the approach is faced with “insuperable difficulties.” This paper takes Wittgenstein to have assumed that his audience would have an understanding of the implicit general rules governing his operations. By employing the Tractarian logicist interpretation that the N-operator
$Num$(x) and quantification over numbers seem ill-formed, Ramsey wrote that the approach is faced with “insuperable difficulties.” This paper takes Wittgenstein to have assumed that his audience would have an understanding of the implicit general rules governing his operations. By employing the Tractarian logicist interpretation that the N-operator 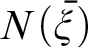 $N(\bar {\xi })$ and recursively defined arithmetic operators
$N(\bar {\xi })$ and recursively defined arithmetic operators 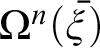 $\Omega ^{n}(\bar {\xi })$ are not different in kind, we can address Ramsey’s problem. Moreover, we can take important steps toward better understanding how Wittgenstein might have imagined emulating proof by mathematical induction.
$\Omega ^{n}(\bar {\xi })$ are not different in kind, we can address Ramsey’s problem. Moreover, we can take important steps toward better understanding how Wittgenstein might have imagined emulating proof by mathematical induction.
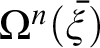
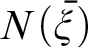
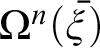
RIGOUR AND PROOF
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 21 October 2020, pp. 480-508
- Print publication:
- June 2023
-
- Article
- Export citation
