Refine search
Actions for selected content:
48413 results in Computer Science
BAYESIAN ANALYSIS OF DOUBLY STOCHASTIC MARKOV PROCESSES IN RELIABILITY
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 08 April 2020, pp. 708-729
-
- Article
- Export citation
NLE volume 26 issue 3 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Heterogeneous binary random-access lists
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 30 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e10
-
- Article
-
- You have access
- Open access
- Export citation
NLE volume 26 issue 3 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. b1-b2
-
- Article
-
- You have access
- Export citation
A network tool to analyse and improve robustness of system architectures
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Emerging trends: Subwords, seriously?
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. 375-382
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Open Petri nets
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 3 / March 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. 314-341
-
- Article
-
- You have access
- Open access
- Export citation
-
The reachability semantics for Petri nets can be studied using open Petri nets. For us, an “open” Petri net is one with certain places designated as inputs and outputs via a cospan of sets. We can compose open Petri nets by gluing the outputs of one to the inputs of another. Open Petri nets can be treated as morphisms of a category Open(Petri), which becomes symmetric monoidal under disjoint union. However, since the composite of open Petri nets is defined only up to isomorphism, it is better to treat them as morphisms of a symmetric monoidal double category
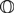 ${\mathbb O}$pen(Petri). We describe two forms of semantics for open Petri nets using symmetric monoidal double functors out of ${\mathbb O}$pen(Petri). The first, an operational semantics, gives for each open Petri net a category whose morphisms are the processes that this net can carry out. This is done in a compositional way, so that these categories can be computed on smaller subnets and then glued together. The second, a reachability semantics, simply says which markings of the outputs can be reached from a given marking of the inputs.
${\mathbb O}$pen(Petri). We describe two forms of semantics for open Petri nets using symmetric monoidal double functors out of ${\mathbb O}$pen(Petri). The first, an operational semantics, gives for each open Petri net a category whose morphisms are the processes that this net can carry out. This is done in a compositional way, so that these categories can be computed on smaller subnets and then glued together. The second, a reachability semantics, simply says which markings of the outputs can be reached from a given marking of the inputs.
Robot magic show: human–robot interaction
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e15
-
- Article
- Export citation
Text classification with semantically enriched word embeddings
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 06 April 2020, pp. 391-425
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research perspectives in ecodesign
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 06 April 2020, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Investigating translated Chinese and its variants using machine learning
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 03 April 2020, pp. 339-372
-
- Article
- Export citation
Egonets as systematically biased windows on society
-
- Journal:
- Network Science / Volume 8 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 03 April 2020, pp. 399-417
-
- Article
- Export citation
Where you are, what you want, and what you can do: The role of master statuses, personality traits, and social cognition in shaping ego network size, structure, and composition
-
- Journal:
- Network Science / Volume 8 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 03 April 2020, pp. 356-380
-
- Article
- Export citation
SMT-based verification of data-aware processes: a model-theoretic approach
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 3 / March 2020
- Published online by Cambridge University Press:
- 03 April 2020, pp. 271-313
-
- Article
- Export citation
17 - The Statistics behind Online Controlled Experiments
- from Part V - Advanced Topics for Analyzing Experiments
-
- Book:
- Trustworthy Online Controlled Experiments
- Published online:
- 13 March 2020
- Print publication:
- 02 April 2020, pp 185-192
-
- Chapter
- Export citation
Index
-
- Book:
- Trustworthy Online Controlled Experiments
- Published online:
- 13 March 2020
- Print publication:
- 02 April 2020, pp 266-272
-
- Chapter
- Export citation
3 - Techniques
- from Part I - Conceptual Introductions
-
- Book:
- A Hands-On Introduction to Data Science
- Published online:
- 01 February 2020
- Print publication:
- 02 April 2020, pp 66-96
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- A Hands-On Introduction to Data Science
- Published online:
- 01 February 2020
- Print publication:
- 02 April 2020, pp xxii-xxiv
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Trustworthy Online Controlled Experiments
- Published online:
- 13 March 2020
- Print publication:
- 02 April 2020, pp xvii-xviii
-
- Chapter
- Export citation
