Refine search
Actions for selected content:
48294 results in Computer Science
Modeling industrial engineering change processes using the design structure matrix for sequence analysis: a comparison of multiple projects
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 16 March 2020, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Demonstration, extension, and refinement of the re-proposed notion of design abduction
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Trustworthy Online Controlled Experiments
- A Practical Guide to A/B Testing
-
- Published online:
- 13 March 2020
- Print publication:
- 02 April 2020
A Review of Dynamic Balancing for Robotic Mechanisms
-
- Article
-
- You have access
- Open access
- Export citation
ENTROPY-BASED AND NON-ENTROPY-BASED GOODNESS OF FIT TEST FOR THE INVERSE RAYLEIGH DISTRIBUTION WITH PROGRESSIVELY TYPE-II CENSORED DATA
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 11 March 2020, pp. 631-649
-
- Article
- Export citation
Interdisciplinary engineering of cyber-physical production systems: highlighting the benefits of a combined interdisciplinary modelling approach on the basis of an industrial case
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 11 March 2020, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
User research enabled by makerspaces: bringing functionality to classical experience prototypes
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fine-grained analysis of language varieties and demographics
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 10 March 2020, pp. 641-661
-
- Article
- Export citation
Classification of regional and genre varieties of Chinese: A correspondence analysis approach based on comparable balanced corpora
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 09 March 2020, pp. 613-640
-
- Article
- Export citation
Matching biodiversity and ecology ontologies: challenges and evaluation results
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 09 March 2020, e9
-
- Article
- Export citation
Computable analysis with applications to dynamic systems
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 2 / February 2020
- Published online by Cambridge University Press:
- 09 March 2020, pp. 173-233
-
- Article
-
- You have access
- Open access
- Export citation
On minimal Ramsey graphs and Ramsey equivalence in multiple colours
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 4 / July 2020
- Published online by Cambridge University Press:
- 09 March 2020, pp. 537-554
-
- Article
- Export citation
-
For an integer q ⩾ 2, a graph G is called q-Ramsey for a graph H if every q-colouring of the edges of G contains a monochromatic copy of H. If G is q-Ramsey for H yet no proper subgraph of G has this property, then G is called q-Ramsey-minimal for H. Generalizing a statement by Burr, Nešetřil and Rödl from 1977, we prove that, for q ⩾ 3, if G is a graph that is not q-Ramsey for some graph H, then G is contained as an induced subgraph in an infinite number of q-Ramsey-minimal graphs for H as long as H is 3-connected or isomorphic to the triangle. For such H, the following are some consequences.
For 2 ⩽ r < q, every r-Ramsey-minimal graph for H is contained as an induced subgraph in an infinite number of q-Ramsey-minimal graphs for H.
For every q ⩾ 3, there are q-Ramsey-minimal graphs for H of arbitrarily large maximum degree, genus and chromatic number.
The collection
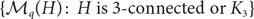 $\{\mathcal M_q(H) \colon H \text{ is 3-connected or } K_3\}$ forms an antichain with respect to the subset relation, where
$\{\mathcal M_q(H) \colon H \text{ is 3-connected or } K_3\}$ forms an antichain with respect to the subset relation, where 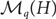 $\mathcal M_q(H)$ denotes the set of all graphs that are q-Ramsey-minimal for H.
$\mathcal M_q(H)$ denotes the set of all graphs that are q-Ramsey-minimal for H.
We also address the question of which pairs of graphs satisfy
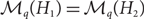 $\mathcal M_q(H_1)=\mathcal M_q(H_2)$, in which case H1 and H2 are called q-equivalent. We show that two graphs H1 and H2 are q-equivalent for even q if they are 2-equivalent, and that in general q-equivalence for some q ⩾ 3 does not necessarily imply 2-equivalence. Finally we indicate that for connected graphs this implication may hold: results by Nešetřil and Rödl and by Fox, Grinshpun, Liebenau, Person and Szabó imply that the complete graph is not 2-equivalent to any other connected graph. We prove that this is the case for an arbitrary number of colours.
$\mathcal M_q(H_1)=\mathcal M_q(H_2)$, in which case H1 and H2 are called q-equivalent. We show that two graphs H1 and H2 are q-equivalent for even q if they are 2-equivalent, and that in general q-equivalence for some q ⩾ 3 does not necessarily imply 2-equivalence. Finally we indicate that for connected graphs this implication may hold: results by Nešetřil and Rödl and by Fox, Grinshpun, Liebenau, Person and Szabó imply that the complete graph is not 2-equivalent to any other connected graph. We prove that this is the case for an arbitrary number of colours.
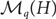
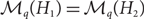
Out of sync, out of society: Political beliefs and social networks
-
- Journal:
- Network Science / Volume 8 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 09 March 2020, pp. 445-468
-
- Article
- Export citation
COMPARISONS ON LARGEST ORDER STATISTICS FROM HETEROGENEOUS GAMMA SAMPLES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 09 March 2020, pp. 611-630
-
- Article
- Export citation
A model for the dynamics of face-to-face interactions in social groups
-
- Journal:
- Network Science / Volume 8 / Issue S1 / July 2020
- Published online by Cambridge University Press:
- 06 March 2020, pp. S4-S25
-
- Article
- Export citation
Nonuniform language in technical writing: Detection and correction
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 3 / May 2021
- Published online by Cambridge University Press:
- 06 March 2020, pp. 293-314
-
- Article
- Export citation
Toll-based reinforcement learning for efficient equilibria in route choice
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 05 March 2020, e8
-
- Article
- Export citation
Long-term cultivation using ineffective MDM2 inhibitor concentrations alters the drug sensitivity profiles of PL21 leukaemia cells
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 05 March 2020, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Saccharide sources do not influence the biofilm formation in Scedosporium/Lomentospora species
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 05 March 2020, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
New tools for the visualization of glial fibrillary acidic protein in living cells
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 05 March 2020, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
