Refine search
Actions for selected content:
48287 results in Computer Science
ON THE DISTRIBUTION OF MAXIMAL PERCENTAGES IN PÓLYA'S URN
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 31 / Issue 3 / July 2017
- Published online by Cambridge University Press:
- 22 September 2016, pp. 357-365
-
- Article
- Export citation
1 - Turing the Man
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 11-20
-
- Chapter
- Export citation
6 - Matters Arising from Early Turing Tests
- from PART ONE
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 81-96
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp i-iv
-
- Chapter
- Export citation
On the expressiveness of π-calculus for encoding mobile ambients
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 2 / February 2018
- Published online by Cambridge University Press:
- 22 September 2016, pp. 202-240
-
- Article
-
- You have access
- Export citation
Gradual type-and-effect systems
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 26 / 2016
- Published online by Cambridge University Press:
- 22 September 2016, e19
-
- Article
-
- You have access
- Export citation
3 - A Brief Introduction to Artificial Intelligence
- from PART ONE
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 41-55
-
- Chapter
- Export citation
Introduction
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 1-10
-
- Chapter
- Export citation
11 - The Reaction to Turing2014
- from PART TWO
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 187-193
-
- Chapter
- Export citation
PART ONE
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 21-22
-
- Chapter
- Export citation
10 - Turing2014: Tests at The Royal Society, June 2014
- from PART TWO
-
- Book:
- Turing's Imitation Game
- Published online:
- 12 October 2016
- Print publication:
- 22 September 2016, pp 171-186
-
- Chapter
- Export citation
Active balancing and turning for alpine skiing robots
-
- Journal:
- The Knowledge Engineering Review / Volume 32 / 2017
- Published online by Cambridge University Press:
- 20 September 2016, e6
-
- Article
- Export citation
PRIVATIVE NEGATION IN THE PORT ROYAL LOGIC
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 4 / December 2016
- Published online by Cambridge University Press:
- 19 September 2016, pp. 664-685
- Print publication:
- December 2016
-
- Article
- Export citation
Saturated Subgraphs of the Hypercube
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 19 September 2016, pp. 52-67
-
- Article
- Export citation
-
We say a graph is (Q n ,Q m )-saturated if it is a maximal Q m -free subgraph of the n-dimensional hypercube Q n . A graph is said to be (Q n ,Q m )-semi-saturated if it is a subgraph of Q n and adding any edge forms a new copy of Q m . The minimum number of edges a (Q n ,Q m )-saturated graph (respectively (Q n ,Q m )-semi-saturated graph) can have is denoted by sat(Q n ,Q m ) (respectively s-sat(Q n ,Q m )). We prove that
for fixed m, disproving a conjecture of Santolupo that, when m=2, this limit is 1/4. Further, we show by a different method that sat(Q n , Q 2)=O(2n ), and that s-sat(Q n , Q m )=O(2n ), for fixed m. We also prove the lower bound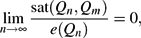 $$\begin{linenomath}\lim_{n\to\infty}\ffrac{\sat(Q_n,Q_m)}{e(Q_n)}=0,\end{linenomath}$$ thus determining sat(Q n ,Q 2) to within a constant factor, and discuss some further questions.
$$\begin{linenomath}\lim_{n\to\infty}\ffrac{\sat(Q_n,Q_m)}{e(Q_n)}=0,\end{linenomath}$$ thus determining sat(Q n ,Q 2) to within a constant factor, and discuss some further questions.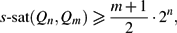 $$\begin{linenomath}\ssat(Q_n,Q_m)\geq \ffrac{m+1}{2}\cdot 2^n,\end{linenomath}$$
$$\begin{linenomath}\ssat(Q_n,Q_m)\geq \ffrac{m+1}{2}\cdot 2^n,\end{linenomath}$$
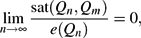
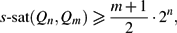
PES volume 30 issue 4 Cover and Front matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 4 / October 2016
- Published online by Cambridge University Press:
- 16 September 2016, pp. f1-f2
-
- Article
-
- You have access
- Export citation
ON THE QUASI-STATIONARY DISTRIBUTION OF SIS MODELS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 4 / October 2016
- Published online by Cambridge University Press:
- 16 September 2016, pp. 622-639
-
- Article
- Export citation
PES volume 30 issue 4 Cover and Back matter
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 4 / October 2016
- Published online by Cambridge University Press:
- 16 September 2016, pp. b1-b2
-
- Article
-
- You have access
- Export citation
ON THE IDENTIFICATION AND MITIGATION OF WEAKNESSES IN THE KNOWLEDGE GRADIENT POLICY FOR MULTI-ARMED BANDITS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 31 / Issue 2 / April 2017
- Published online by Cambridge University Press:
- 13 September 2016, pp. 239-263
-
- Article
- Export citation
A QUEUEING MODEL WITH RANDOMIZED DEPLETION OF INVENTORY
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 31 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 13 September 2016, pp. 43-59
-
- Article
- Export citation
