Refine search
Actions for selected content:
48202 results in Computer Science
18 - Preprocessors
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 528-545
-
- Chapter
- Export citation
Forward Clusters for Degenerate Random Environments
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 24 May 2016, pp. 744-765
-
- Article
- Export citation
-
We consider connectivity properties and asymptotic slopes for certain random directed graphs on ℤ2 in which the set of points
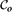 $\mathcal{C}_o$ that the origin connects to is always infinite. We obtain conditions under which the complement of $\mathcal{C}_o$ has no infinite connected component. Applying these results to one of the most interesting such models leads to an improved lower bound for the critical occupation probability for oriented site percolation on the triangular lattice in two dimensions.
$\mathcal{C}_o$ that the origin connects to is always infinite. We obtain conditions under which the complement of $\mathcal{C}_o$ has no infinite connected component. Applying these results to one of the most interesting such models leads to an improved lower bound for the critical occupation probability for oriented site percolation on the triangular lattice in two dimensions.
7 - Operators and Expressions
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 74-97
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp i-iv
-
- Chapter
- Export citation
10 - Loop Statements
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 171-223
-
- Chapter
- Export citation
19 - Linked List
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 546-578
-
- Chapter
- Export citation
13 - Function
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 320-366
-
- Chapter
- Export citation
List of Tables
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp xv-xvi
-
- Chapter
- Export citation
Model Question Set-4 - Answer to Model Question Set-4
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 596-601
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp xix-xx
-
- Chapter
- Export citation
12 - String Handling
-
- Book:
- Basic Computation and Programming with C
- Published online:
- 17 July 2025
- Print publication:
- 24 May 2016, pp 268-319
-
- Chapter
- Export citation
NWS volume 4 issue 2 Cover and Back matter
-
- Journal:
- Network Science / Volume 4 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 23 May 2016, pp. b1-b5
-
- Article
-
- You have access
- Export citation
A model of collaboration network formation with heterogeneous skills
-
- Journal:
- Network Science / Volume 4 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 23 May 2016, pp. 188-215
-
- Article
- Export citation
NWS volume 4 issue 2 Cover and Front matter
-
- Journal:
- Network Science / Volume 4 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 23 May 2016, pp. f1-f3
-
- Article
-
- You have access
- Export citation
Interplay between signaling network design and swarm dynamics
-
- Journal:
- Network Science / Volume 4 / Issue 2 / June 2016
- Published online by Cambridge University Press:
- 23 May 2016, pp. 244-265
-
- Article
- Export citation
Foreword: special issue on coalgebraic logic
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 7 / October 2017
- Published online by Cambridge University Press:
- 20 May 2016, pp. 1108-1110
-
- Article
-
- You have access
- Export citation
The genus of regular languages
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 1 / January 2018
- Published online by Cambridge University Press:
- 20 May 2016, pp. 14-44
-
- Article
- Export citation
EROL GELENBE: A CAREER IN MULTI-DISCIPLINARY PROBABILITY MODELS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 3 / July 2016
- Published online by Cambridge University Press:
- 20 May 2016, pp. 308-325
-
- Article
-
- You have access
- Open access
- Export citation
