Refine search
Actions for selected content:
48202 results in Computer Science
Analyzing heterogeneity in the effects of physical activity in children on social network structure and peer selection dynamics
-
- Journal:
- Network Science / Volume 4 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 12 May 2016, pp. 336-363
-
- Article
- Export citation
Corrigendum: Multi-contact bipedal robotic locomotion
-
- Article
-
- You have access
- Export citation
-
In Eq. (22), the x symbol was incorrectly represented by an @ symbol, therefore the equation should correctly read as
Similar errors were also found in the sentence following Eq. (22). In this sentence, the correct math symbol should be yva (x) and yvd (x) instead of yva (@) and yvd (@).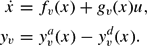 \begin{eqnarray*}\dot x &=& {f_v}(x) + {g_v}(x)u,\\{y_v} &=& y_v^a(x) - y_v^d(x).\end{eqnarray*}
\begin{eqnarray*}\dot x &=& {f_v}(x) + {g_v}(x)u,\\{y_v} &=& y_v^a(x) - y_v^d(x).\end{eqnarray*}
Friendship networks and sun safety behavior among children
-
- Journal:
- Network Science / Volume 4 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 10 May 2016, pp. 314-335
-
- Article
- Export citation
The co-evolution of power and friendship networks in an organization
-
- Journal:
- Network Science / Volume 4 / Issue 3 / September 2016
- Published online by Cambridge University Press:
- 10 May 2016, pp. 364-384
-
- Article
- Export citation
NERA 2.0: Improving coverage and performance of rule-based named entity recognition for Arabic*
-
- Journal:
- Natural Language Engineering / Volume 23 / Issue 3 / May 2017
- Published online by Cambridge University Press:
- 06 May 2016, pp. 441-472
-
- Article
- Export citation

Handbook of Computational Social Choice
-
- Published online:
- 05 May 2016
- Print publication:
- 25 April 2016
Asymptotic Structure of Graphs with the Minimum Number of Triangles
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 04 May 2016, pp. 138-160
-
- Article
-
- You have access
- Open access
- Export citation
Public investment and electric vehicle design: a model-based market analysis framework with application to a USA–China comparison study
- Part of
-
- Journal:
- Design Science / Volume 2 / 2016
- Published online by Cambridge University Press:
- 04 May 2016, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the Richter–Thomassen Conjecture about Pairwise Intersecting Closed Curves†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 04 May 2016, pp. 941-958
-
- Article
- Export citation
-
A long-standing conjecture of Richter and Thomassen states that the total number of intersection points between any n simple closed Jordan curves in the plane, so that any pair of them intersect and no three curves pass through the same point, is at least (1−o(1))n 2.
We confirm the above conjecture in several important cases, including the case (1) when all curves are convex, and (2) when the family of curves can be partitioned into two equal classes such that each curve from the first class touches every curve from the second class. (Two closed or open curves are said to be touching if they have precisely one point in common and at this point the two curves do not properly cross.)
An important ingredient of our proofs is the following statement. Let S be a family of n open curves in ℝ2, so that each curve is the graph of a continuous real function defined on ℝ, and no three of them pass through the same point. If there are nt pairs of touching curves in S, then the number of crossing points is
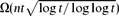 $\Omega(nt\sqrt{\log t/\log\log t})$ .
$\Omega(nt\sqrt{\log t/\log\log t})$ .
Shape Measures of Random Increasing k-trees†
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 25 / Issue 5 / September 2016
- Published online by Cambridge University Press:
- 04 May 2016, pp. 668-699
-
- Article
- Export citation
Range-based argumentation semantics as two-valued models
-
- Journal:
- Theory and Practice of Logic Programming / Volume 17 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 03 May 2016, pp. 75-90
-
- Article
- Export citation
The undecidability theorem for the Horn-like fragment of linear logic (Revisited)
-
- Journal:
- Mathematical Structures in Computer Science / Volume 26 / Issue 5 / June 2016
- Published online by Cambridge University Press:
- 03 May 2016, pp. 719-744
-
- Article
- Export citation
-
There has been an increased interest in the decision problems for linear logic and its fragments. Here, we give a fully self-contained, easy-to-follow, but fully detailed, direct and constructive proof of the undecidability of a very simple Horn-like fragment of linear logic, which is accessible to a wide range of people. Namely, we show that there is a direct correspondence between terminated computations of a Minsky machine M and cut-free linear logic derivations for a Horn-like sequent of the form
where ΦM consists only of Horn-like implications of the following simple forms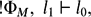 \begin{equation*}\bang{\Phi_M},\ l_1 \vdash l_0,\end{equation*}where l1, l0, l, l′, l″ and r stand for literals.
\begin{equation*}\bang{\Phi_M},\ l_1 \vdash l_0,\end{equation*}where l1, l0, l, l′, l″ and r stand for literals.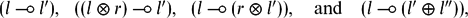 \begin{equation*}(l \llto l'),\ \ ((l\otimes r) \llto l'),\ \ (l\llto (r\otimes l')),\ \ and \ \ (l\llto (l'\oplus l'')),\end{equation*}
\begin{equation*}(l \llto l'),\ \ ((l\otimes r) \llto l'),\ \ (l\llto (r\otimes l')),\ \ and \ \ (l\llto (l'\oplus l'')),\end{equation*}Neither negation, nor &, nor constants, nor embedded implications/bangs are used here.
Furthermore, our particular correspondence constructed above provides decidability for each of the Horn-like fragments whenever we confine ourselves to any two forms of the above Horn-like implications, along with the complexity bounds that come from the proof.
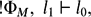
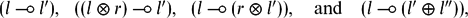
On definite program answers and least Herbrand models
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 4 / July 2016
- Published online by Cambridge University Press:
- 03 May 2016, pp. 498-508
-
- Article
- Export citation
Enablers and inhibitors in causal justifications of logic programs*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 17 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 03 May 2016, pp. 49-74
-
- Article
- Export citation
Realizability algebras III: some examples
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 1 / January 2018
- Published online by Cambridge University Press:
- 03 May 2016, pp. 45-76
-
- Article
- Export citation
