Refine search
Actions for selected content:
48178 results in Computer Science
LINEAR BIRTH/IMMIGRATION-DEATH PROCESS WITH BINOMIAL CATASTROPHES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 14 October 2015, pp. 79-111
-
- Article
- Export citation
D-SPECTRUM AND RELIABILITY OF A BINARY SYSTEM WITH TERNARY COMPONENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 30 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 14 October 2015, pp. 25-39
-
- Article
- Export citation
5 - Multiscale Geometric Transforms
-
- Book:
- Sparse Image and Signal Processing
- Published online:
- 05 October 2015
- Print publication:
- 14 October 2015, pp 94-124
-
- Chapter
- Export citation
10 - Dictionary Learning
-
- Book:
- Sparse Image and Signal Processing
- Published online:
- 05 October 2015
- Print publication:
- 14 October 2015, pp 263-274
-
- Chapter
- Export citation
12 - Multiscale Geometric Analysis on the Sphere
-
- Book:
- Sparse Image and Signal Processing
- Published online:
- 05 October 2015
- Print publication:
- 14 October 2015, pp 321-372
-
- Chapter
- Export citation
11 - Three-Dimensional Sparse Representations
-
- Book:
- Sparse Image and Signal Processing
- Published online:
- 05 October 2015
- Print publication:
- 14 October 2015, pp 275-320
-
- Chapter
- Export citation
A survey of graphs in natural language processing*
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 5 / November 2015
- Published online by Cambridge University Press:
- 12 October 2015, pp. 665-698
-
- Article
-
- You have access
- HTML
- Export citation
Resource convertibility and ordered commutative monoids
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 6 / September 2017
- Published online by Cambridge University Press:
- 12 October 2015, pp. 850-938
-
- Article
-
- You have access
- Export citation
-
Resources and their use and consumption form a central part of our life. Many branches of science and engineering are concerned with the question of which given resource objects can be converted into which target resource objects. For example, information theory studies the conversion of a noisy communication channel instance into an exchange of information. Inspired by work in quantum information theory, we develop a general mathematical toolbox for this type of question. The convertibility of resources into other ones and the possibility of combining resources is accurately captured by the mathematics of ordered commutative monoids. As an intuitive example, we consider chemistry, where chemical reaction equations such as
are concerned both with a convertibility relation ‘→’ and a combination operation ‘+.’ We study ordered commutative monoids from an algebraic and functional-analytic perspective and derive a wealth of results which should have applications to concrete resource theories, such as a formula for rates of conversion. As a running example showing that ordered commutative monoids are also of purely mathematical interest without the resource-theoretic interpretation, we exemplify our results with the ordered commutative monoid of graphs.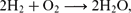 \mathrm{2H_2 + O_2} \lra \mathrm{2H_2O,}
\mathrm{2H_2 + O_2} \lra \mathrm{2H_2O,}While closely related to both Girard's linear logic and to Deutsch's constructor theory, our framework also produces results very reminiscent of the utility theorem of von Neumann and Morgenstern in decision theory and of a theorem of Lieb and Yngvason on the foundations of thermodynamics.
Concerning pure algebra, our observation is that some pieces of algebra can be developed in a context in which equality is not necessarily symmetric, i.e. in which the equality relation is replaced by an ordering relation. For example, notions like cancellativity or torsion-freeness are still sensible and very natural concepts in our ordered setting.
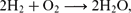
NLE volume 21 issue 5 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 5 / November 2015
- Published online by Cambridge University Press:
- 12 October 2015, pp. b1-b7
-
- Article
-
- You have access
- Export citation
NLE volume 21 issue 5 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 21 / Issue 5 / November 2015
- Published online by Cambridge University Press:
- 12 October 2015, pp. f1-f2
-
- Article
-
- You have access
- Export citation
OPTIMAL SWITCHING ON AND OFF THE ENTIRE SERVICE CAPACITY OF A PARALLEL QUEUE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 29 / Issue 4 / October 2015
- Published online by Cambridge University Press:
- 09 October 2015, pp. 483-506
-
- Article
- Export citation
A CONTINUOUS REVIEW MODEL WITH GENERAL SHELF AGE AND DELAY-DEPENDENT INVENTORY COSTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 29 / Issue 4 / October 2015
- Published online by Cambridge University Press:
- 09 October 2015, pp. 507-525
-
- Article
- Export citation
Review of “A functional start to computing with Python”, Ted Herman, CRC Press, 2014, ISBN 978-1-4665-0455-4
-
- Journal:
- Journal of Functional Programming / Volume 25 / 2015
- Published online by Cambridge University Press:
- 08 October 2015, e15
-
- Article
-
- You have access
- HTML
- Export citation
