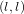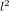Refine search
Actions for selected content:
48202 results in Computer Science
ON THE LOGIC OF FACTUAL EQUIVALENCE
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 07 August 2015, pp. 103-122
- Print publication:
- March 2016
-
- Article
-
- You have access
- Export citation
44 - Kronecker IV
- from PART SIX - Algebraic Solving
-
- Book:
- Solving Polynomial Equation Systems III
- Published online:
- 05 August 2015
- Print publication:
- 07 August 2015, pp 222-246
-
- Chapter
- Export citation
Isomorphism of intersection and union types†
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 5 / June 2017
- Published online by Cambridge University Press:
- 07 August 2015, pp. 603-625
-
- Article
- Export citation
39 - Trinks
- from PART SIX - Algebraic Solving
-
- Book:
- Solving Polynomial Equation Systems III
- Published online:
- 05 August 2015
- Print publication:
- 07 August 2015, pp 3-18
-
- Chapter
- Export citation
Preface
-
- Book:
- Solving Polynomial Equation Systems III
- Published online:
- 05 August 2015
- Print publication:
- 07 August 2015, pp xi-xii
-
- Chapter
- Export citation
Taming the wild ant-lion; a counterexample to a conjecture of Böhm
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 5 / June 2017
- Published online by Cambridge University Press:
- 07 August 2015, pp. 734-737
-
- Article
- Export citation
INFORMAL PROOF, FORMAL PROOF, FORMALISM
-
- Journal:
- The Review of Symbolic Logic / Volume 9 / Issue 1 / March 2016
- Published online by Cambridge University Press:
- 07 August 2015, pp. 23-43
- Print publication:
- March 2016
-
- Article
- Export citation
Index
-
- Book:
- Solving Polynomial Equation Systems III
- Published online:
- 05 August 2015
- Print publication:
- 07 August 2015, pp 273-275
-
- Chapter
- Export citation
Computational logics and verification techniques of multi-agent commitments: survey
-
- Journal:
- The Knowledge Engineering Review / Volume 30 / Issue 5 / November 2015
- Published online by Cambridge University Press:
- 06 August 2015, pp. 564-606
-
- Article
- Export citation
Understanding beginners' mistakes with Haskell
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 25 / 2015
- Published online by Cambridge University Press:
- 06 August 2015, e11
-
- Article
-
- You have access
- Export citation

Solving Polynomial Equation Systems III
-
- Published online:
- 05 August 2015
- Print publication:
- 07 August 2015
Preface
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 2 / February 2017
- Published online by Cambridge University Press:
- 05 August 2015, pp. 92-93
-
- Article
-
- You have access
- Export citation

Bayesian Speech and Language Processing
-
- Published online:
- 05 August 2015
- Print publication:
- 15 July 2015

Secure Multiparty Computation and Secret Sharing
-
- Published online:
- 05 August 2015
- Print publication:
- 15 July 2015

Inequalities for Graph Eigenvalues
-
- Published online:
- 05 August 2015
- Print publication:
- 23 July 2015
Modernising historical Slovene words
-
- Journal:
- Natural Language Engineering / Volume 22 / Issue 6 / November 2016
- Published online by Cambridge University Press:
- 03 August 2015, pp. 881-905
-
- Article
- Export citation
Examples of CM curves of genus two defined over the reflex field
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 August 2015, pp. 507-538
-
- Article
-
- You have access
- Export citation
-
Van Wamelen [Math. Comp. 68 (1999) no. 225, 307–320] lists 19 curves of genus two over
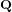 $\mathbf{Q}$ with complex multiplication (CM). However, for each curve, the CM-field turns out to be cyclic Galois over
$\mathbf{Q}$ with complex multiplication (CM). However, for each curve, the CM-field turns out to be cyclic Galois over 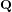 $\mathbf{Q}$ , and the generic case of a non-Galois quartic CM-field did not feature in this list. The reason is that the field of definition in that case always contains the real quadratic subfield of the reflex field.
$\mathbf{Q}$ , and the generic case of a non-Galois quartic CM-field did not feature in this list. The reason is that the field of definition in that case always contains the real quadratic subfield of the reflex field.We extend Van Wamelen’s list to include curves of genus two defined over this real quadratic field. Our list therefore contains the smallest ‘generic’ examples of CM curves of genus two.
We explain our methods for obtaining this list, including a new height-reduction algorithm for arbitrary hyperelliptic curves over totally real number fields. Unlike Van Wamelen, we also give a proof of our list, which is made possible by our implementation of denominator bounds of Lauter and Viray for Igusa class polynomials.
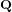
Hyperelliptic modular curves
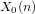 $X_{0}(n)$ and isogenies of elliptic curves over quadratic fields
$X_{0}(n)$ and isogenies of elliptic curves over quadratic fields
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 August 2015, pp. 578-602
-
- Article
-
- You have access
- Export citation
-
We study elliptic curves over quadratic fields with isogenies of certain degrees. Let
 $n$ be a positive integer such that the modular curve
$n$ be a positive integer such that the modular curve 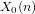 $X_{0}(n)$ is hyperelliptic of genus
$X_{0}(n)$ is hyperelliptic of genus 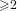 ${\geqslant}2$ and such that its Jacobian has rank
${\geqslant}2$ and such that its Jacobian has rank  $0$ over
$0$ over 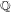 $\mathbb{Q}$ . We determine all points of
$\mathbb{Q}$ . We determine all points of 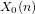 $X_{0}(n)$ defined over quadratic fields, and we give a moduli interpretation of these points. We show that, with a finite number of exceptions up to
$X_{0}(n)$ defined over quadratic fields, and we give a moduli interpretation of these points. We show that, with a finite number of exceptions up to 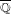 $\overline{\mathbb{Q}}$ -isomorphism, every elliptic curve over a quadratic field
$\overline{\mathbb{Q}}$ -isomorphism, every elliptic curve over a quadratic field 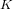 $K$ admitting an
$K$ admitting an  $n$ -isogeny is
$n$ -isogeny is  $d$ -isogenous, for some
$d$ -isogenous, for some 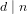 $d\mid n$ , to the twist of its Galois conjugate by a quadratic extension
$d\mid n$ , to the twist of its Galois conjugate by a quadratic extension  $L$ of
$L$ of 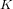 $K$ . We determine
$K$ . We determine  $d$ and
$d$ and  $L$ explicitly, and we list all exceptions. As a consequence, again with a finite number of exceptions up to
$L$ explicitly, and we list all exceptions. As a consequence, again with a finite number of exceptions up to 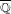 $\overline{\mathbb{Q}}$ -isomorphism, all elliptic curves with
$\overline{\mathbb{Q}}$ -isomorphism, all elliptic curves with  $n$ -isogenies over quadratic fields are in fact
$n$ -isogenies over quadratic fields are in fact 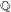 $\mathbb{Q}$ -curves.
$\mathbb{Q}$ -curves.
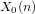


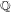
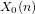
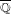


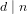

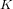



Schubert presentation of the cohomology ring of flag manifolds
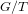 $G/T$
$G/T$
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 August 2015, pp. 489-506
-
- Article
-
- You have access
- Export citation
-
Let
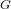 $G$ be a compact connected Lie group with a maximal torus
$G$ be a compact connected Lie group with a maximal torus 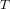 $T$ . In the context of Schubert calculus we present the integral cohomology
$T$ . In the context of Schubert calculus we present the integral cohomology 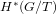 $H^{\ast }(G/T)$ by a minimal system of generators and relations.
$H^{\ast }(G/T)$ by a minimal system of generators and relations.
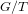
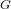
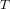
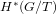
Computing functions on Jacobians and their quotients
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 18 / Issue 1 / 2015
- Published online by Cambridge University Press:
- 01 August 2015, pp. 555-577
-
- Article
-
- You have access
- Export citation
-
We show how to efficiently evaluate functions on Jacobian varieties and their quotients. We deduce an algorithm to compute
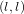 $(l,l)$ isogenies between Jacobians of genus two curves in quasi-linear time in the degree
$(l,l)$ isogenies between Jacobians of genus two curves in quasi-linear time in the degree 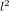 $l^{2}$ .
$l^{2}$ .