Refine search
Actions for selected content:
2567 results in Computational Science
A sieve algorithm based on overlattices
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 49-70
-
- Article
-
- You have access
- Export citation
-
In this paper, we present a heuristic algorithm for solving exact, as well as approximate, shortest vector and closest vector problems on lattices. The algorithm can be seen as a modified sieving algorithm for which the vectors of the intermediate sets lie in overlattices or translated cosets of overlattices. The key idea is hence no longer to work with a single lattice but to move the problems around in a tower of related lattices. We initiate the algorithm by sampling very short vectors in an overlattice of the original lattice that admits a quasi-orthonormal basis and hence an efficient enumeration of vectors of bounded norm. Taking sums of vectors in the sample, we construct short vectors in the next lattice. Finally, we obtain solution vector(s) in the initial lattice as a sum of vectors of an overlattice. The complexity analysis relies on the Gaussian heuristic. This heuristic is backed by experiments in low and high dimensions that closely reflect these estimates when solving hard lattice problems in the average case.
This new approach allows us to solve not only shortest vector problems, but also closest vector problems, in lattices of dimension
 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}n$ in time
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}n$ in time 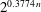 $2^{0.3774\, n}$ using memory
$2^{0.3774\, n}$ using memory 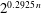 $2^{0.2925\, n}$. Moreover, the algorithm is straightforward to parallelize on most computer architectures.
$2^{0.2925\, n}$. Moreover, the algorithm is straightforward to parallelize on most computer architectures.

Minimal models for
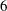 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}6$-coverings of elliptic curves
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}6$-coverings of elliptic curves
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 112-127
-
- Article
-
- You have access
- Export citation
-
In this paper we give a new formula for adding
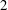 $2$-coverings and
$2$-coverings and 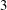 $3$-coverings of elliptic curves that avoids the need for any field extensions. We show that the
$3$-coverings of elliptic curves that avoids the need for any field extensions. We show that the 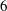 $6$-coverings obtained can be represented by pairs of cubic forms. We then prove a theorem on the existence of such models with integer coefficients and the same discriminant as a minimal model for the Jacobian elliptic curve. This work has applications to finding rational points of large height on elliptic curves.
$6$-coverings obtained can be represented by pairs of cubic forms. We then prove a theorem on the existence of such models with integer coefficients and the same discriminant as a minimal model for the Jacobian elliptic curve. This work has applications to finding rational points of large height on elliptic curves.
Computing Hasse–Witt matrices of hyperelliptic curves in average polynomial time
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 257-273
-
- Article
-
- You have access
- Export citation
-
We present an efficient algorithm to compute the Hasse–Witt matrix of a hyperelliptic curve
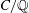 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}C/\mathbb{Q}$ modulo all primes of good reduction up to a given bound
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}C/\mathbb{Q}$ modulo all primes of good reduction up to a given bound 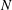 $N$, based on the average polynomial-time algorithm recently proposed by the first author. An implementation for hyperelliptic curves of genus 2 and 3 is more than an order of magnitude faster than alternative methods for
$N$, based on the average polynomial-time algorithm recently proposed by the first author. An implementation for hyperelliptic curves of genus 2 and 3 is more than an order of magnitude faster than alternative methods for 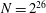 $N = 2^{26}$.
$N = 2^{26}$.
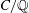
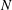
Computation of Mordell–Weil bases for ordinary elliptic curves in characteristic two
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 1-13
-
- Article
-
- You have access
- Export citation
-
In this paper we consider ordinary elliptic curves over global function fields of characteristic
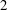 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}2$. We present a method for performing a descent by using powers of the Frobenius and the Verschiebung. An examination of the local images of the descent maps together with a duality theorem yields information about the global Selmer groups. Explicit models for the homogeneous spaces representing the elements of the Selmer groups are given and used to construct independent points on the elliptic curve. As an application we use descent maps to prove an upper bound for the naive height of an
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}2$. We present a method for performing a descent by using powers of the Frobenius and the Verschiebung. An examination of the local images of the descent maps together with a duality theorem yields information about the global Selmer groups. Explicit models for the homogeneous spaces representing the elements of the Selmer groups are given and used to construct independent points on the elliptic curve. As an application we use descent maps to prove an upper bound for the naive height of an  $S$-integral point on
$S$-integral point on 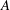 $A$. To illustrate our methods, a detailed example is presented.
$A$. To illustrate our methods, a detailed example is presented.
Computing Galois representations of modular abelian surfaces
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 36-48
-
- Article
-
- You have access
- Export citation
-
Let
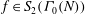 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}f\in S_2(\Gamma _0(N))$ be a normalized newform such that the abelian variety
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}f\in S_2(\Gamma _0(N))$ be a normalized newform such that the abelian variety 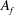 $A_f$ attached by Shimura to
$A_f$ attached by Shimura to 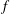 $f$ is the Jacobian of a genus-two curve. We give an efficient algorithm for computing Galois representations associated to such newforms.
$f$ is the Jacobian of a genus-two curve. We give an efficient algorithm for computing Galois representations associated to such newforms.
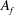
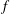
Hyper-and-elliptic-curve cryptography
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 181-202
-
- Article
-
- You have access
- Export citation
Subexponential class group and unit group computation in large degree number fields
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 385-403
-
- Article
-
- You have access
- Export citation
Nonvanishing of twists of
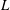 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}L$-functions attached to Hilbert modular forms
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}L$-functions attached to Hilbert modular forms
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 330-348
-
- Article
-
- You have access
- Export citation
-
We describe algorithms for computing central values of twists of
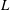 $L$-functions associated to Hilbert modular forms, carry out such computations for a number of examples, and compare the results of these computations to some heuristics and predictions from random matrix theory.
$L$-functions associated to Hilbert modular forms, carry out such computations for a number of examples, and compare the results of these computations to some heuristics and predictions from random matrix theory.
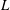
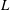
On the quaternion
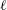 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\ell $-isogeny path problem
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\ell $-isogeny path problem
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 418-432
-
- Article
-
- You have access
- Export citation
-
Let
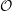 $\mathcal{O}$ be a maximal order in a definite quaternion algebra over
$\mathcal{O}$ be a maximal order in a definite quaternion algebra over 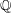 $\mathbb{Q}$ of prime discriminant
$\mathbb{Q}$ of prime discriminant 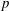 $p$, and
$p$, and 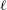 $\ell $ a small prime. We describe a probabilistic algorithm which, for a given left
$\ell $ a small prime. We describe a probabilistic algorithm which, for a given left 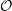 $\mathcal{O}$-ideal, computes a representative in its left ideal class of
$\mathcal{O}$-ideal, computes a representative in its left ideal class of 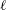 $\ell $-power norm. In practice the algorithm is efficient and, subject to heuristics on expected distributions of primes, runs in expected polynomial time. This solves the underlying problem for a quaternion analog of the Charles–Goren–Lauter hash function, and has security implications for the original CGL construction in terms of supersingular elliptic curves.
$\ell $-power norm. In practice the algorithm is efficient and, subject to heuristics on expected distributions of primes, runs in expected polynomial time. This solves the underlying problem for a quaternion analog of the Charles–Goren–Lauter hash function, and has security implications for the original CGL construction in terms of supersingular elliptic curves.
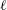
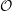
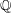
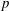
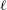
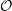
Examples of
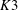 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}K3$ surfaces with real multiplication
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}K3$ surfaces with real multiplication
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 14-35
-
- Article
-
- You have access
- Export citation
-
We construct explicit
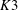 $K3$ surfaces over
$K3$ surfaces over 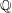 $\mathbb{Q}$ having real multiplication. Our examples are of geometric Picard rank 16. The standard method for the computation of the Picard rank provably fails for the surfaces constructed.
$\mathbb{Q}$ having real multiplication. Our examples are of geometric Picard rank 16. The standard method for the computation of the Picard rank provably fails for the surfaces constructed.
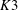
Parametrizing the moduli space of curves and applications to smooth plane quartics over finite fields
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 128-147
-
- Article
-
- You have access
- Export citation
Linear algebra over
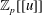 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\mathbb{Z}_p[[u]]$ and related rings
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\mathbb{Z}_p[[u]]$ and related rings
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 302-344
-
- Article
-
- You have access
- Export citation
-
Let
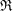 $\mathfrak{R}$ be a complete discrete valuation ring,
$\mathfrak{R}$ be a complete discrete valuation ring, 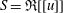 $S=\mathfrak{R}[[u]]$ and
$S=\mathfrak{R}[[u]]$ and 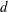 $d$ a positive integer. The aim of this paper is to explain how to efficiently compute usual operations such as sum and intersection of sub-
$d$ a positive integer. The aim of this paper is to explain how to efficiently compute usual operations such as sum and intersection of sub- 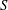 $S$ -modules of
$S$ -modules of 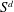 $S^d$ . As
$S^d$ . As 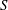 $S$ is not principal, it is not possible to have a uniform bound on the number of generators of the modules resulting from these operations. We explain how to mitigate this problem, following an idea of Iwasawa, by computing an approximation of the result of these operations up to a quasi-isomorphism. In the course of the analysis of the
$S$ is not principal, it is not possible to have a uniform bound on the number of generators of the modules resulting from these operations. We explain how to mitigate this problem, following an idea of Iwasawa, by computing an approximation of the result of these operations up to a quasi-isomorphism. In the course of the analysis of the 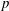 $p$ -adic and
$p$ -adic and  $u$ -adic precisions of the computations, we have to introduce more general coefficient rings that may be interesting for their own sake. Being able to perform linear algebra operations modulo quasi-isomorphism with
$u$ -adic precisions of the computations, we have to introduce more general coefficient rings that may be interesting for their own sake. Being able to perform linear algebra operations modulo quasi-isomorphism with 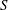 $S$ -modules has applications in Iwasawa theory and
$S$ -modules has applications in Iwasawa theory and 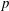 $p$ -adic Hodge theory. It is used in particular in Caruso and Lubicz (Preprint, 2013,arXiv:1309.4194) to compute the semi-simplified modulo
$p$ -adic Hodge theory. It is used in particular in Caruso and Lubicz (Preprint, 2013,arXiv:1309.4194) to compute the semi-simplified modulo 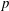 $p$ of a semi-stable representation.
$p$ of a semi-stable representation.
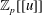
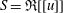
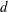
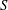
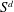
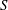
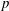

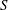
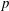
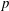
Computing in quotients of rings of integers
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 349-365
-
- Article
-
- You have access
- Export citation
The multiple number field sieve for medium- and high-characteristic finite fields
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue A / 2014
- Published online by Cambridge University Press:
- 01 August 2014, pp. 230-246
-
- Article
-
- You have access
- Export citation
-
In this paper we study the discrete logarithm problem in medium- and high-characteristic finite fields. We propose a variant of the number field sieve (NFS) based on numerous number fields. Our improved algorithm computes discrete logarithms in
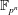 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\mathbb{F}_{p^n}$ for the whole range of applicability of the NFS and lowers the asymptotic complexity from
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}\mathbb{F}_{p^n}$ for the whole range of applicability of the NFS and lowers the asymptotic complexity from 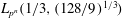 $L_{p^n}({1/3},({128/9})^{1/3})$ to
$L_{p^n}({1/3},({128/9})^{1/3})$ to 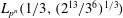 $L_{p^n}({1/3},(2^{13}/3^6)^{1/3})$ in the medium-characteristic case, and from
$L_{p^n}({1/3},(2^{13}/3^6)^{1/3})$ in the medium-characteristic case, and from 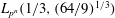 $L_{p^n}({1/3},({64/9})^{1/3})$ to
$L_{p^n}({1/3},({64/9})^{1/3})$ to 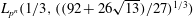 $L_{p^n}({1/3},((92 + 26 \sqrt{13})/27)^{1/3})$ in the high-characteristic case.
$L_{p^n}({1/3},((92 + 26 \sqrt{13})/27)^{1/3})$ in the high-characteristic case.
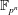
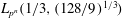
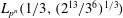
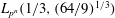
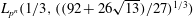
Appendix A - Installing a Python environment
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 205-209
-
- Chapter
- Export citation
Index
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 218-220
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 1-10
-
- Chapter
- Export citation
References
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 216-217
-
- Chapter
- Export citation
9 - Case study: multigrid
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 184-204
-
- Chapter
- Export citation
2 - Getting started with IPython
-
- Book:
- Python for Scientists
- Published online:
- 05 August 2014
- Print publication:
- 10 July 2014, pp 11-19
-
- Chapter
- Export citation
