Refine search
Actions for selected content:
2567 results in Computational Science
Computation of Galois groups of rational polynomials
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 141-158
-
- Article
-
- You have access
- Export citation
-
Computational Galois theory, in particular the problem of computing the Galois group of a given polynomial, is a very old problem. Currently, the best algorithmic solution is Stauduhar’s method. Computationally, one of the key challenges in the application of Stauduhar’s method is to find, for a given pair of groups
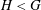 $H<G$ , a
$H<G$ , a 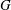 $G$ -relative
$G$ -relative 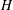 $H$ -invariant, that is a multivariate polynomial
$H$ -invariant, that is a multivariate polynomial 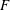 $F$ that is
$F$ that is 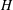 $H$ -invariant, but not
$H$ -invariant, but not 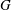 $G$ -invariant. While generic, theoretical methods are known to find such
$G$ -invariant. While generic, theoretical methods are known to find such 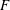 $F$ , in general they yield impractical answers. We give a general method for computing invariants of large degree which improves on previous known methods, as well as various special invariants that are derived from the structure of the groups. We then apply our new invariants to the task of computing the Galois groups of polynomials over the rational numbers, resulting in the first practical degree independent algorithm.
$F$ , in general they yield impractical answers. We give a general method for computing invariants of large degree which improves on previous known methods, as well as various special invariants that are derived from the structure of the groups. We then apply our new invariants to the task of computing the Galois groups of polynomials over the rational numbers, resulting in the first practical degree independent algorithm.
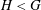
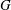
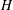
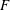
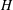
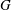
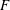
A note on magnitude bounds for the mask coefficients of the interpolatory Dubuc–Deslauriers subdivision scheme
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 226-232
-
- Article
-
- You have access
- Export citation
-
We analyse the mask associated with the
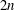 $2n$ -point interpolatory Dubuc–Deslauriers subdivision scheme
$2n$ -point interpolatory Dubuc–Deslauriers subdivision scheme 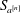 $S_{a^{[n]}}$ . Sharp bounds are presented for the magnitude of the coefficients
$S_{a^{[n]}}$ . Sharp bounds are presented for the magnitude of the coefficients 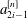 $a^{[n]}_{2i-1}$ of the mask. For scales
$a^{[n]}_{2i-1}$ of the mask. For scales 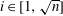 $i \in [1,\sqrt{n}]$ it is shown that
$i \in [1,\sqrt{n}]$ it is shown that 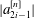 $|a^{[n]}_{2i-1}|$ is comparable to
$|a^{[n]}_{2i-1}|$ is comparable to 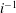 $i^{-1}$ , and for larger power scales, exponentially decaying bounds are obtained. Using our bounds, we may precisely analyse the summability of the mask as a function of
$i^{-1}$ , and for larger power scales, exponentially decaying bounds are obtained. Using our bounds, we may precisely analyse the summability of the mask as a function of  $n$ by identifying which coefficients of the mask contribute to the essential behaviour in
$n$ by identifying which coefficients of the mask contribute to the essential behaviour in  $n$ , recovering and refining the recent result of Deng–Hormann–Zhang that the operator norm of
$n$ , recovering and refining the recent result of Deng–Hormann–Zhang that the operator norm of 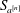 $S_{a^{[n]}}$ on
$S_{a^{[n]}}$ on 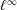 $\ell ^\infty $ grows logarithmically in
$\ell ^\infty $ grows logarithmically in  $n$ .
$n$ .
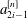
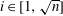
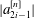
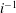


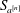
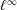

A note on uniform approximation of functions having a double pole
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 233-244
-
- Article
-
- You have access
- Export citation
-
We consider the classical problem of finding the best uniform approximation by polynomials of
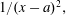 $1/(x-a)^2,$ where
$1/(x-a)^2,$ where 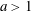 $a>1$ is given, on the interval
$a>1$ is given, on the interval 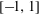 $[-\! 1,1]$ . First, using symbolic computation tools we derive the explicit expressions of the polynomials of best approximation of low degrees and then give a parametric solution of the problem in terms of elliptic functions. Symbolic computation is invoked then once more to derive a recurrence relation for the coefficients of the polynomials of best uniform approximation based on a Pell-type equation satisfied by the solutions.
$[-\! 1,1]$ . First, using symbolic computation tools we derive the explicit expressions of the polynomials of best approximation of low degrees and then give a parametric solution of the problem in terms of elliptic functions. Symbolic computation is invoked then once more to derive a recurrence relation for the coefficients of the polynomials of best uniform approximation based on a Pell-type equation satisfied by the solutions.
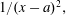
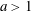
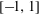
Approximations for the Bessel and Airy functions with an explicit error term
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 209-225
-
- Article
-
- You have access
- Export citation
-
We show how one can obtain an asymptotic expression for some special functions with a very explicit error term starting from appropriate upper bounds. We will work out the details for the Bessel function
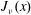 $J_\nu (x)$ and the Airy function
$J_\nu (x)$ and the Airy function 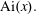 ${\rm Ai}(x).$ In particular, we answer a question raised by Olenko and find a sharp bound on the difference between
${\rm Ai}(x).$ In particular, we answer a question raised by Olenko and find a sharp bound on the difference between 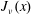 $J_\nu (x)$ and its standard asymptotics. We also give a very simple and surprisingly precise approximation for the zeros
$J_\nu (x)$ and its standard asymptotics. We also give a very simple and surprisingly precise approximation for the zeros 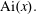 ${\rm Ai}(x).$
${\rm Ai}(x).$
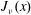
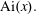
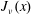
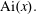
Minimal genus and fibering of canonical surfaces via disk decomposition
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 May 2014, pp. 77-108
-
- Article
-
- You have access
- Export citation
Classification of subgroups isomorphic to
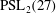 $\mathrm{PSL}_2(27)$ in the Monster
$\mathrm{PSL}_2(27)$ in the Monster
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 33-46
-
- Article
-
- You have access
- Export citation
-
As a contribution to an eventual solution of the problem of the determination of the maximal subgroups of the Monster we prove that the Monster does not contain any subgroup isomorphic to
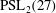 $\mathrm{PSL}_2(27)$ .
$\mathrm{PSL}_2(27)$ .
Computing fundamental domains for the Bruhat–Tits tree for
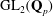 ${\rm GL}_2(\mathbf{Q}_p)$ ,
${\rm GL}_2(\mathbf{Q}_p)$ , 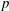 $p$ -adic automorphic forms, and the canonical embedding of Shimura curves
$p$ -adic automorphic forms, and the canonical embedding of Shimura curves
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 1-23
-
- Article
-
- You have access
- Export citation
On a conjecture of Rudin on squares in arithmetic progressions
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 58-76
-
- Article
-
- You have access
- Export citation
-
Let
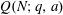 $Q(N;q,a)$ be the number of squares in the arithmetic progression
$Q(N;q,a)$ be the number of squares in the arithmetic progression 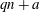 $qn+a$ , for
$qn+a$ , for 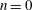 $n=0$ ,
$n=0$ , 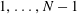 $1,\ldots,N-1$ , and let
$1,\ldots,N-1$ , and let 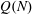 $Q(N)$ be the maximum of
$Q(N)$ be the maximum of 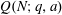 $Q(N;q,a)$ over all non-trivial arithmetic progressions
$Q(N;q,a)$ over all non-trivial arithmetic progressions 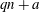 $qn + a$ . Rudin’s conjecture claims that
$qn + a$ . Rudin’s conjecture claims that 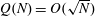 $Q(N)=O(\sqrt{N})$ , and in its stronger form that
$Q(N)=O(\sqrt{N})$ , and in its stronger form that 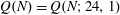 $Q(N)=Q(N;24,1)$ if
$Q(N)=Q(N;24,1)$ if 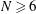 $N\ge 6$ . We prove the conjecture above for
$N\ge 6$ . We prove the conjecture above for 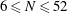 $6\le N\le 52$ . We even prove that the arithmetic progression
$6\le N\le 52$ . We even prove that the arithmetic progression 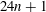 $24n+1$ is the only one, up to equivalence, that contains
$24n+1$ is the only one, up to equivalence, that contains 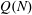 $Q(N)$ squares for the values of
$Q(N)$ squares for the values of 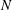 $N$ such that
$N$ such that 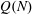 $Q(N)$ increases, for
$Q(N)$ increases, for 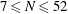 $7\le N\le 52$ (
$7\le N\le 52$ ( 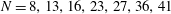 $N=8,13,16,23,27,36,41$ and
$N=8,13,16,23,27,36,41$ and 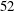 $52$ ).
$52$ ).
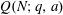
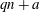
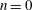
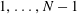
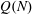
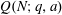
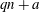
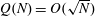
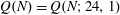
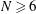
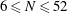
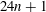
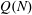
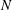
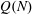
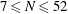
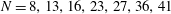
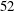
Wieferich pairs and Barker sequences, II
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 24-32
-
- Article
-
- You have access
- Export citation
-
We show that if a Barker sequence of length
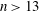 $n>13$ exists, then either n
$n>13$ exists, then either n  $=$ 3 979 201 339 721749 133 016 171 583 224 100, or
$=$ 3 979 201 339 721749 133 016 171 583 224 100, or 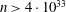 $n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly
$n > 4\cdot 10^{33}$ . This improves the lower bound on the length of a long Barker sequence by a factor of nearly 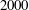 $2000$ . We also obtain eighteen additional integers
$2000$ . We also obtain eighteen additional integers 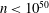 $n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates
$n<10^{50}$ that cannot be ruled out as the length of a Barker sequence, and find more than 237 000 additional candidates 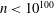 $n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on
$n<10^{100}$ . These results are obtained by completing extensive searches for Wieferich prime pairs and using them, together with a number of arithmetic restrictions on  $n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
$n$ , to construct qualifying integers below a given bound. We also report on some updated computations regarding open cases of the circulant Hadamard matrix problem.
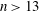

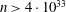
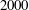
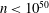
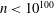

Deterministic polynomial factoring and association schemes
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 123-140
-
- Article
-
- You have access
- Export citation
-
The problem of finding a nontrivial factor of a polynomial
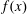 $f(x)$ over a finite field
$f(x)$ over a finite field 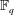 ${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let
${\mathbb{F}}_q$ has many known efficient, but randomized, algorithms. The deterministic complexity of this problem is a famous open question even assuming the generalized Riemann hypothesis (GRH). In this work we improve the state of the art by focusing on prime degree polynomials; let  $n$ be the degree. If
$n$ be the degree. If 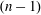 $(n-1)$ has a‘large’
$(n-1)$ has a‘large’  $r$ -smooth divisor
$r$ -smooth divisor  $s$ , then we find a nontrivial factor of
$s$ , then we find a nontrivial factor of 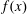 $f(x)$ in deterministic
$f(x)$ in deterministic 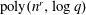 $\mbox{poly}(n^r,\log q)$ time, assuming GRH and that
$\mbox{poly}(n^r,\log q)$ time, assuming GRH and that 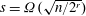 $s=\Omega (\sqrt{n/2^r})$ . Thus, for
$s=\Omega (\sqrt{n/2^r})$ . Thus, for 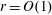 $r=O(1)$ our algorithm is polynomial time. Further, for
$r=O(1)$ our algorithm is polynomial time. Further, for 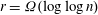 $r=\Omega (\log \log n)$ there are infinitely many prime degrees
$r=\Omega (\log \log n)$ there are infinitely many prime degrees  $n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of
$n$ for which our algorithm is applicable and better than the best known, assuming GRH. Our methods build on the algebraic-combinatorial framework of 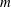 $m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the
$m$ -schemes initiated by Ivanyos, Karpinski and Saxena (ISSAC 2009). We show that the 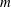 $m$ -scheme on
$m$ -scheme on  $n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.
$n$ points, implicitly appearing in our factoring algorithm, has an exceptional structure, leading us to the improved time complexity. Our structure theorem proves the existence of small intersection numbers in any association scheme that has many relations, and roughly equal valencies and indistinguishing numbers.
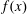
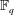

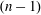


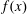
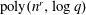
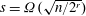
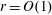
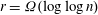

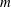
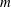

Calculating conjugacy classes in Sylow
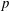 $p$ -subgroups of finite Chevalley groups of rank six and seven
$p$ -subgroups of finite Chevalley groups of rank six and seven
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 109-122
-
- Article
-
- You have access
- Export citation
-
Let
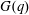 $G(q)$ be a finite Chevalley group, where
$G(q)$ be a finite Chevalley group, where 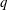 $q$ is a power of a good prime
$q$ is a power of a good prime 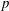 $p$ , and let
$p$ , and let 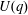 $U(q)$ be a Sylow
$U(q)$ be a Sylow 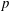 $p$ -subgroup of
$p$ -subgroup of 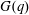 $G(q)$ . Then a generalized version of a conjecture of Higman asserts that the number
$G(q)$ . Then a generalized version of a conjecture of Higman asserts that the number 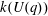 $k(U(q))$ of conjugacy classes in
$k(U(q))$ of conjugacy classes in 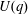 $U(q)$ is given by a polynomial in
$U(q)$ is given by a polynomial in 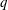 $q$ with integer coefficients. In [S. M. Goodwin and G. Röhrle, J. Algebra 321 (2009) 3321–3334], the first and the third authors of the present paper developed an algorithm to calculate the values of
$q$ with integer coefficients. In [S. M. Goodwin and G. Röhrle, J. Algebra 321 (2009) 3321–3334], the first and the third authors of the present paper developed an algorithm to calculate the values of 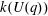 $k(U(q))$ . By implementing it into a computer program using
$k(U(q))$ . By implementing it into a computer program using 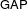 $\mathsf{GAP}$ , they were able to calculate
$\mathsf{GAP}$ , they were able to calculate 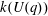 $k(U(q))$ for
$k(U(q))$ for 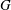 $G$ of rank at most five, thereby proving that for these cases
$G$ of rank at most five, thereby proving that for these cases 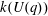 $k(U(q))$ is given by a polynomial in
$k(U(q))$ is given by a polynomial in 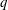 $q$ . In this paper we present some refinements and improvements of the algorithm that allow us to calculate the values of
$q$ . In this paper we present some refinements and improvements of the algorithm that allow us to calculate the values of 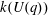 $k(U(q))$ for finite Chevalley groups of rank six and seven, except
$k(U(q))$ for finite Chevalley groups of rank six and seven, except 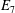 $E_7$ . We observe that
$E_7$ . We observe that 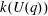 $k(U(q))$ is a polynomial, so that the generalized Higman conjecture holds for these groups. Moreover, if we write
$k(U(q))$ is a polynomial, so that the generalized Higman conjecture holds for these groups. Moreover, if we write 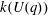 $k(U(q))$ as a polynomial in
$k(U(q))$ as a polynomial in 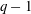 $q-1$ , then the coefficients are non-negative.
$q-1$ , then the coefficients are non-negative.Under the assumption that
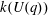 $k(U(q))$ is a polynomial in
$k(U(q))$ is a polynomial in 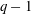 $q-1$ , we also give an explicit formula for the coefficients of
$q-1$ , we also give an explicit formula for the coefficients of 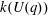 $k(U(q))$ of degrees zero, one and two.
$k(U(q))$ of degrees zero, one and two.
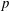
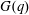
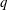
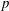
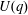
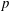
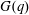
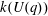
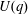
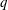
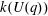
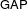
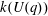
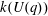
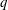
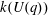
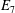
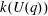
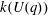
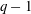
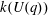
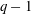
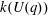
Bounds for zeros of Meixner and Kravchuk polynomials
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 17 / Issue 1 / 2014
- Published online by Cambridge University Press:
- 01 April 2014, pp. 47-57
-
- Article
-
- You have access
- Export citation
7 - Statistical analysis of mathematical models
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 121-167
-
- Chapter
- Export citation
5 - Strategies for simplifying mathematical models
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 53-80
-
- Chapter
- Export citation
6 - Numerical methods
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 81-120
-
- Chapter
- Export citation
3 - Model formulation
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 20-39
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp i-iv
-
- Chapter
- Export citation
Appendix A - Microscopic transport equations
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 168-169
-
- Chapter
- Export citation
4 - Empirical model building
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp 40-52
-
- Chapter
- Export citation
Contents
-
- Book:
- Mathematical Modeling in Chemical Engineering
- Published online:
- 05 June 2014
- Print publication:
- 20 March 2014, pp v-viii
-
- Chapter
- Export citation
