Refine search
Actions for selected content:
2584 results in Computational Science
Copyright page
-
- Book:
- Generalized Vectorization, Cross-Products, and Matrix Calculus
- Published online:
- 05 February 2013
- Print publication:
- 11 February 2013, pp iv-iv
-
- Chapter
- Export citation
Five - New Matrix Calculus Results
-
- Book:
- Generalized Vectorization, Cross-Products, and Matrix Calculus
- Published online:
- 05 February 2013
- Print publication:
- 11 February 2013, pp 164-213
-
- Chapter
- Export citation
Preface
-
- Book:
- Generalized Vectorization, Cross-Products, and Matrix Calculus
- Published online:
- 05 February 2013
- Print publication:
- 11 February 2013, pp ix-xii
-
- Chapter
- Export citation

Generalized Vectorization, Cross-Products, and Matrix Calculus
-
- Published online:
- 05 February 2013
- Print publication:
- 11 February 2013

Complex Social Networks
-
- Published online:
- 05 January 2013
- Print publication:
- 08 January 2007

Econometric Modelling with Time Series
- Specification, Estimation and Testing
-
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012
Seven new champion linear codes
- Part of
-
- Journal:
- LMS Journal of Computation and Mathematics / Volume 16 / October 2013
- Published online by Cambridge University Press:
- 01 January 2013, pp. 109-117
-
- Article
-
- You have access
- Export citation
-
We exhibit seven linear codes exceeding the current best known minimum distance
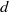 $d$ for their dimension
$d$ for their dimension 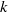 $k$ and block length
$k$ and block length  $n$ . Each code is defined over
$n$ . Each code is defined over 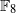 ${ \mathbb{F} }_{8} $ , and their invariants
${ \mathbb{F} }_{8} $ , and their invariants 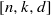 $[n, k, d] $ are given by
$[n, k, d] $ are given by 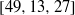 $[49, 13, 27] $ ,
$[49, 13, 27] $ , 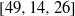 $[49, 14, 26] $ ,
$[49, 14, 26] $ , 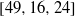 $[49, 16, 24] $ ,
$[49, 16, 24] $ , 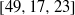 $[49, 17, 23] $ ,
$[49, 17, 23] $ , 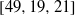 $[49, 19, 21] $ ,
$[49, 19, 21] $ , 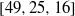 $[49, 25, 16] $ and
$[49, 25, 16] $ and 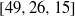 $[49, 26, 15] $ . Our method includes an exhaustive search of all monomial evaluation codes generated by points in the
$[49, 26, 15] $ . Our method includes an exhaustive search of all monomial evaluation codes generated by points in the 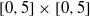 $[0, 5] \times [0, 5] $ lattice square.
$[0, 5] \times [0, 5] $ lattice square.
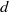
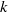

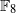
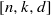
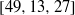
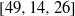
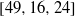
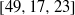
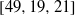
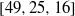
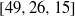
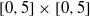
Appendix D - Additional Nonparametric Results
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 857-864
-
- Chapter
- Export citation
2 - Properties of Maximum Likelihood Estimators
- from PART ONE - Maximum Likelihood
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 33-86
-
- Chapter
- Export citation
PART SIX - Nonlinear Time Series
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 713-714
-
- Chapter
- Export citation
12 - Estimation by Simulation
- from PART THREE - Other Estimation Methods
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 432-464
-
- Chapter
- Export citation
20 - Nonlinearities in Variance
- from PART SIX - Nonlinear Time Series
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 758-811
-
- Chapter
- Export citation
9 - Quasi-Maximum Likelihood Estimation
- from PART THREE - Other Estimation Methods
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 307-351
-
- Chapter
- Export citation
4 - Hypothesis Testing
- from PART ONE - Maximum Likelihood
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 119-154
-
- Chapter
- Export citation
Contents
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp ix-xx
-
- Chapter
- Export citation
6 - Nonlinear Regression Models
- from PART TWO - Regression Models
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 194-227
-
- Chapter
- Export citation
5 - Linear Regression Models
- from PART TWO - Regression Models
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 157-193
-
- Chapter
- Export citation
Author Index
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 877-880
-
- Chapter
- Export citation
8 - Heteroskedastic Regression Models
- from PART TWO - Regression Models
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 272-304
-
- Chapter
- Export citation
PART ONE - Maximum Likelihood
-
- Book:
- Econometric Modelling with Time Series
- Published online:
- 05 January 2013
- Print publication:
- 28 December 2012, pp 1-2
-
- Chapter
- Export citation
