Refine search
Actions for selected content:
9084 results in Discrete Mathematics, Information Theory and Coding
On similar short sums
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 193-204
- Print publication:
- June 1999
-
- Article
- Export citation
-
In the paper [5] bounds are found for the sum,
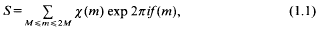
for a suitable Dirichlet character χ mod r, and real functionf(x). The proofs in that paper use Bombieri and Iwaniec's method [1], one formulation of which has as part of its first step the estimation of S in terms of a sum of many shorter sums of the form,
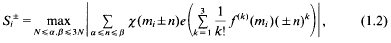
where e(x) = exp (2πix), mi∈ [M, 2M], and each mi, lies in its own interval, of length N ≥ M/4, that is disjoint from those of the others. This paper addresses a problem springing from above: to bound the numbers of ‘similar’ pairs, Si+, Si+, satisfying both

and
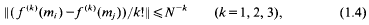
where ‖x‖ = min{|x − n|: n ∈ ℤ}. Lemma 5.2.1 of [3] (partial summation) shows that each sum in a similar pair is a bounded multiple of the other.
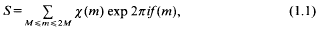
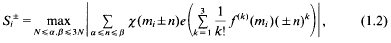

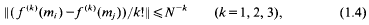
Flatness properties of acts over commutative, cancellative monoids
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 93-102
- Print publication:
- June 1999
-
- Article
- Export citation
Intersection bodies and polytopes
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 29-34
- Print publication:
- June 1999
-
- Article
- Export citation
Estimates of the least prime factor of a binomial coefficient
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 41-55
- Print publication:
- June 1999
-
- Article
- Export citation
-
Let k be a positive integer and g(k) be the least integer n > k + 1 such that all prime factors of
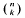 are >k. We prove that
are >k. We prove that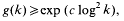
where c is an absolute positive constant. We also establish a new theorem on the distribution of fractional parts of a smooth function.
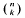 are >
are >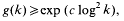
On the location of spectral concentration for perturbed discrete spectra
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 145-154
- Print publication:
- June 1999
-
- Article
- Export citation
-
We consider the spectral function
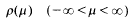
associated with the Sturm-Liouville equation
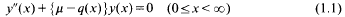
in situations where q(x) →−∞ as x → ∞ and (1.1) is in the Weyl limit-point case at ∞. As usual, q is real-valued and locally integrable in [0, ∞], and our particular concern is where q(x) has the form

where c (>0) is a parameter, s and p are non-negative on [0, ∞], p(x) → ∞ and p(x) = 0{s(x) } as x → ∞. As the boundary condition at x = 0, we take the Dirichlet condition y(0) = 0 for convenience: we can equally take the Neumann condition y′ (0) = 0 or generally a1y(0) + a2y′ (0) = 0 with real a1 and a2.
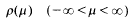
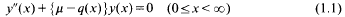

Convex bodies with non-convex cross-section bodies
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 127-129
- Print publication:
- June 1999
-
- Article
- Export citation
Rings which are residually ℤ
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 175-183
- Print publication:
- June 1999
-
- Article
- Export citation
-
Let
 be a class of structures for a first-order language and let n be a positive integer. A structure A for the language is said to be n-residually if, given elements a1, … an and b1, … bn of A with ai≠bi for 1 ≤i≤n, there exist B ∈ and an epimorphism φ:A → B such that φ(ai≠φ(bi for 1 ≤i ≤ n. We abbreviate 1 -residually to residually , and A is said to be fully residually if it is n-residually for all n ≤ 1. We shall only be using two cases. One is where the language is the first-order language of groups, {·−1,1}, and A and all members of are groups. In this case we may take all the bi in the definition to be equal to 1. However, we are mainly interested in the first-order language of rings, {+,−·,0,1}. Again if A and all members of are rings, we may take all bi to be zero in the definition.
be a class of structures for a first-order language and let n be a positive integer. A structure A for the language is said to be n-residually if, given elements a1, … an and b1, … bn of A with ai≠bi for 1 ≤i≤n, there exist B ∈ and an epimorphism φ:A → B such that φ(ai≠φ(bi for 1 ≤i ≤ n. We abbreviate 1 -residually to residually , and A is said to be fully residually if it is n-residually for all n ≤ 1. We shall only be using two cases. One is where the language is the first-order language of groups, {·−1,1}, and A and all members of are groups. In this case we may take all the bi in the definition to be equal to 1. However, we are mainly interested in the first-order language of rings, {+,−·,0,1}. Again if A and all members of are rings, we may take all bi to be zero in the definition.
 be a class of structures for a first-order language and let
be a class of structures for a first-order language and let MTK volume 46 issue 1 Cover and Front matter
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. f1-f4
- Print publication:
- June 1999
-
- Article
-
- You have access
- Export citation
Non-vanishing of the partition function modulo odd primes l
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 185-192
- Print publication:
- June 1999
-
- Article
- Export citation
-
Let p(n) be the usual partition function. Let l be an odd prime, and let r (mod t) be any arithmetic progression. If there exists an integer n ≡ r (mod t) such that p(n) ≢ 0 (mod l), then, for large X,
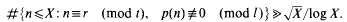
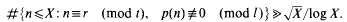
Convex intersection bodies in three and four dimensions
- Part of
-
- Journal:
- Mathematika / Volume 46 / Issue 1 / June 1999
- Published online by Cambridge University Press:
- 26 February 2010, pp. 15-27
- Print publication:
- June 1999
-
- Article
- Export citation
A Measure for the Non-Orthogonality of a Lattice Basis
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 281-291
-
- Article
- Export citation
Conditional Independences among Four Random Variables III: Final Conclusion
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 269-276
-
- Article
- Export citation
List Improper Colourings of Planar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 293-299
-
- Article
- Export citation
On the Expected Depth of Random Circuits
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 209-228
-
- Article
- Export citation
On Increasing Subsequences of I.I.D. Samples
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 247-263
-
- Article
- Export citation
On the Structure of Dense Triangle-Free Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 237-245
-
- Article
- Export citation
On the Density of Universal Sum-Free Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 277-280
-
- Article
- Export citation
On Systems of Small Sets with No Large Δ-Subsystems
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 265-268
-
- Article
- Export citation
On Poisson–Dirichlet Limits for Random Decomposable Combinatorial Structures
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 193-208
-
- Article
- Export citation
The Matroid Ramsey Number n(6,6)
-
- Journal:
- Combinatorics, Probability and Computing / Volume 8 / Issue 3 / May 1999
- Published online by Cambridge University Press:
- 01 May 1999, pp. 229-235
-
- Article
- Export citation
