Refine search
Actions for selected content:
4990 results in Mathematical finance
State-space dynamic functional regression for multicurve fixed income spread analysis and stress testing
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 14 April 2026, pp. 1-34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the study of bivariate and conditional dynamic negative cumulative extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Privacy preserving neural network predictive modelling in insurance using horizontal federated learning
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 31 March 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiserver-job response time under multilevel scaling
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-41
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the multiserver-job setting in the load-focused multilevel scaling limit, where system load approaches capacity much faster than the growth of the number of servers
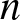 $n$. We consider the “1 and
$n$. We consider the “1 and 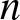 $n$” system, where each job requires either one server or all
$n$” system, where each job requires either one server or all 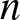 $n$. Within the multilevel scaling limit, we examine three regimes: load dominated by
$n$. Within the multilevel scaling limit, we examine three regimes: load dominated by 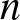 $n$-server jobs, 1-server jobs, or balanced. In each regime, we characterize the asymptotic growth rate of the boundary of the stability region and the scaled mean queue length. We demonstrate that mean queue length peaks near balanced load via theory, numerics, and simulation.
$n$-server jobs, 1-server jobs, or balanced. In each regime, we characterize the asymptotic growth rate of the boundary of the stability region and the scaled mean queue length. We demonstrate that mean queue length peaks near balanced load via theory, numerics, and simulation.
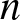
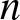
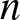
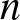
On technological and analytical innovations in insurance research and industry practice
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 25 March 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Intergenerational cross-subsidies in UK collective defined contribution funds
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 25 March 2026, pp. 1-33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Portfolio alignment metrics: what are they and how are they used in net zero investing?
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 03 March 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Relative and divergence measures based on extropy: dynamic forms and properties
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graduating mortality base tables: theory and practice part 2
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multi-state linear three-dimensional consecutive k-type systems
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Consecutive
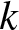 $k$-type systems have become important in both reliability theory and applications; in spite of a large literature existing on them, three-dimensional consecutive
$k$-type systems have become important in both reliability theory and applications; in spite of a large literature existing on them, three-dimensional consecutive 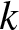 $k$-type systems have not yet been studied for multi-state case. In this paper, we introduce several different types of multi-state linear three-dimensional consecutive
$k$-type systems have not yet been studied for multi-state case. In this paper, we introduce several different types of multi-state linear three-dimensional consecutive 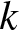 $k$-type systems for the first time, with due consideration to possible overlapping of failure blocks. The finite Markov chain imbedding approach is then used for the derivation of their reliability functions with state spaces and transition matrices provided in a novel way, and the involved computational process is illustrated through several numerical examples. Finally, some possible applications of the work and potential extensions are pointed out.
$k$-type systems for the first time, with due consideration to possible overlapping of failure blocks. The finite Markov chain imbedding approach is then used for the derivation of their reliability functions with state spaces and transition matrices provided in a novel way, and the involved computational process is illustrated through several numerical examples. Finally, some possible applications of the work and potential extensions are pointed out.
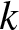
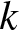
Graduating mortality base tables: theory and practice part 1
-
- Journal:
- British Actuarial Journal / Volume 31 / 2026
- Published online by Cambridge University Press:
- 02 March 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Risk Measures
- An Introduction to the Mathematical Theory
-
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026
Gaussian process models in actuarial science
-
- Journal:
- Annals of Actuarial Science / Volume 20 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 26 February 2026, pp. 1-6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ordering of extreme order statistics among
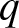 $q$-Weibull random variables
$q$-Weibull random variables
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The
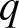 $q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the
$q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the 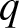 $q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous
$q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous 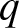 $q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
$q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
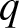
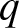
Discovering the complexity of residual lifetimes of live components in the coherent system using cumulative residual extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the complexity of residual lifetimes of live components in coherent systems through the lens of cumulative residual extropy and its divergence-based extension, Jensen-cumulative residual extropy. Unlike classical reliability metrics that focus on system inactivity or mean residual life, our framework quantifies the hidden informational structure of components that remain alive at the system failure time. We derive closed-form expressions for the cumulative residual extropy of conditional residual lifetimes using system signatures and establish stochastic bounds and comparisons that highlight the impact of structural configuration. A novel divergence measure, the Jensen-cumulative residual extropy, is introduced to capture discrepancies between coherent systems and benchmark
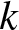 $k$-out-of-
$k$-out-of-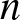 $n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.
$n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.
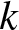
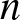
3 - Diversification, Convexity, and Coherence
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 29-42
-
- Chapter
- Export citation
9 - Law-Determined Risk Measures on Lp-Spaces
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 115-128
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp i-iv
-
- Chapter
- Export citation
7 - Constructions of Risk Measures
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 85-104
-
- Chapter
- Export citation
11 - Coherent Comonotonic Additive Risk Measures
-
- Book:
- Risk Measures
- Published online:
- 26 February 2026
- Print publication:
- 19 February 2026, pp 149-164
-
- Chapter
- Export citation
