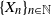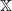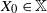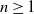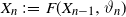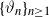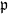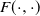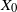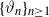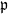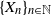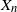Refine listing
Actions for selected content:
126 results in 62Fxx
Enhanced upper confidence limits via randomized tests in random sampling without replacement
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 09 October 2025, pp. 1-51
-
- Article
- Export citation
-
In this paper we study one-sided hypothesis testing under random sampling without replacement, which frequently appears in the cryptographic problem setting, including the verification of measurement-based quantum computation. Suppose that
 $n+1$ binary random variables
$n+1$ binary random variables  $X_1,\ldots, X_{n+1}$ follow a permutation invariant distribution and n binary random variables
$X_1,\ldots, X_{n+1}$ follow a permutation invariant distribution and n binary random variables  $X_1,\ldots, X_{n}$ are observed. Then, we propose randomized tests with a randomization parameter for the expectation of the
$X_1,\ldots, X_{n}$ are observed. Then, we propose randomized tests with a randomization parameter for the expectation of the  $(n+1)$th random variable
$(n+1)$th random variable  $X_{n+1}$ under a given significance level
$X_{n+1}$ under a given significance level  $\delta>0$. Our randomized tests significantly improve the upper confidence limit over deterministic tests. Our problem setting commonly appears in machine learning in addition to cryptographic scenarios by considering adversarial examples. Such studies are essential for expanding the applicable area of statistics. Although this paper addresses only binary random variables, a similar significant improvement by randomized tests can be expected for general non-binary random variables.
$\delta>0$. Our randomized tests significantly improve the upper confidence limit over deterministic tests. Our problem setting commonly appears in machine learning in addition to cryptographic scenarios by considering adversarial examples. Such studies are essential for expanding the applicable area of statistics. Although this paper addresses only binary random variables, a similar significant improvement by randomized tests can be expected for general non-binary random variables.






Estimation of on- and off-time distributions in a dynamic Erdős–Rényi random graph
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 09 October 2025, pp. 1-30
-
- Article
- Export citation
Asymptotic mixed normality of maximum-likelihood estimator for Ewens–Pitman partition
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 09 September 2025, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the asymptotic properties of parameter estimation for the Ewens–Pitman partition with parameters
 $0\lt\alpha\lt1$ and
$0\lt\alpha\lt1$ and  $\theta\gt-\alpha$. Specifically, we show that the maximum-likelihood estimator (MLE) of
$\theta\gt-\alpha$. Specifically, we show that the maximum-likelihood estimator (MLE) of  $\alpha$ is
$\alpha$ is  $n^{\alpha/2}$-consistent and converges to a variance mixture of normal distributions, where the variance is governed by the Mittag-Leffler distribution. Moreover, we show that a proper normalization involving a random statistic eliminates the randomness in the variance. Building on this result, we construct an approximate confidence interval for
$n^{\alpha/2}$-consistent and converges to a variance mixture of normal distributions, where the variance is governed by the Mittag-Leffler distribution. Moreover, we show that a proper normalization involving a random statistic eliminates the randomness in the variance. Building on this result, we construct an approximate confidence interval for  $\alpha$. Our proof relies on a stable martingale central limit theorem, which is of independent interest.
$\alpha$. Our proof relies on a stable martingale central limit theorem, which is of independent interest.





Market-based insurance ratemaking: Application to pet insurance
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 55 / Issue 2 / May 2025
- Published online by Cambridge University Press:
- 11 April 2025, pp. 263-286
- Print publication:
- May 2025
-
- Article
- Export citation
Extropy-based dynamic cumulative residual inaccuracy measure: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 461-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Copula-based reliability estimation of parallel-series system in the multicomponent stress–strength dependent model
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 22 January 2025, pp. 309-325
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the study of the cumulative residual extropy of mixed used systems and their complexity
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 26 November 2024, pp. 122-140
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
EFFICIENT INFERENCE FOR SPATIAL AND SPATIO-TEMPORAL STATISTICAL MODELS USING BASIS-FUNCTION AND DEEP-LEARNING METHODS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 111 / Issue 1 / February 2025
- Published online by Cambridge University Press:
- 04 October 2024, pp. 182-183
- Print publication:
- February 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximum likelihood estimation for spinal-structured trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 234-268
- Print publication:
- March 2025
-
- Article
- Export citation
-
We investigate some aspects of the problem of the estimation of birth distributions (BDs) in multi-type Galton–Watson trees (MGWs) with unobserved types. More precisely, we consider two-type MGWs called spinal-structured trees. This kind of tree is characterized by a spine of special individuals whose BD
 $\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by
$\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by 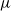 $\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate
$\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate 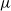 $\mu$ and
$\mu$ and  $\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of
$\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of 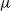 $\mu$ and
$\mu$ and  $\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if
$\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if 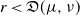 $r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and
$r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and 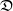 $\mathfrak{D}$ is a divergence measuring the dissimilarity between
$\mathfrak{D}$ is a divergence measuring the dissimilarity between 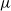 $\mu$ and
$\mu$ and  $\nu$.
$\nu$.

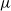

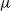

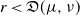
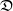
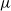

Exact recovery of community detection in k-community Gaussian mixture models
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 18 September 2024, pp. 491-523
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the community detection problem on a Gaussian mixture model, in which vertices are divided into
 $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.

BAYESIAN METHODS AND POLYNOMIAL CHAOS: APPLICATION TO FINDING CARDIAC BIDOMAIN PARAMETERS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 110 / Issue 1 / August 2024
- Published online by Cambridge University Press:
- 27 August 2024, pp. 167-169
- Print publication:
- August 2024
-
- Article
-
- You have access
- HTML
- Export citation
On the dynamic residual measure of inaccuracy based on extropy in order statistics
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 3 / July 2024
- Published online by Cambridge University Press:
- 11 January 2024, pp. 481-502
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trajectory fitting estimation for reflected stochastic linear differential equations of a large signal
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 31 October 2023, pp. 741-754
- Print publication:
- September 2024
-
- Article
- Export citation
BAYESIAN SPATIOTEMPORAL MODELS FOR INFECTIOUS DISEASES IN RELATION TO HEALTH INEQUALITY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 31 August 2023, pp. 516-517
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Extropy: Characterizations and dynamic versions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 June 2023, pp. 1333-1351
- Print publication:
- December 2023
-
- Article
- Export citation
Self-normalized Cramér moderate deviations for a supercritical Galton–Watson process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1281-1292
- Print publication:
- December 2023
-
- Article
- Export citation
-
Let
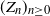 $(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
$(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
On Bayesian credibility mean for finite mixture distributions
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 29 March 2023, pp. 5-29
-
- Article
- Export citation
-
Consider the problem of determining the Bayesian credibility mean
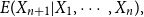 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 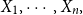 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 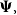 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 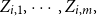 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 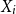 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 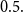 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
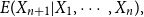
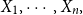
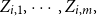
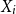
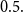
A new measure of inaccuracy for record statistics based on extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 207-225
-
- Article
-
- You have access
- HTML
- Export citation
Robustness of iterated function systems of Lipschitz maps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 921-944
- Print publication:
- September 2023
-
- Article
- Export citation
-
Let
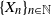 $\{X_n\}_{n\in{\mathbb{N}}}$ be an
$\{X_n\}_{n\in{\mathbb{N}}}$ be an 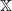 ${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as
${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as 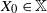 $X_0 \in {\mathbb{X}}$ and for
$X_0 \in {\mathbb{X}}$ and for 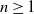 $n\geq 1$,
$n\geq 1$, 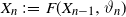 $X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where
$X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where 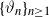 $\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution
$\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution 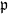 $\mathfrak{p}$,
$\mathfrak{p}$, 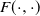 $F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and
$F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and 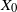 $X_0$ is independent of
$X_0$ is independent of 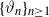 $\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and
$\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and 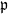 $\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of
$\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of 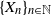 $\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of
$\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of 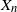 $X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
$X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.