Refine listing
Actions for selected content:
126 results in 62Fxx
Restricted quasi-score estimating functions for sample survey data
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 41 / Issue A / 2004
- Published online by Cambridge University Press:
- 14 July 2016, pp. 119-130
- Print publication:
- 2004
-
- Article
- Export citation
Asymptotic inference for nearly unstable INAR(1) models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 750-765
- Print publication:
- September 2003
-
- Article
- Export citation
Statistical properties of a system reliability estimator using the Littlewood software reliability model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 40 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 14 July 2016, pp. 766-778
- Print publication:
- September 2003
-
- Article
- Export citation
Estimation of the directional measure of planar random sets by digitization
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 35 / Issue 3 / September 2003
- Published online by Cambridge University Press:
- 01 July 2016, pp. 583-602
- Print publication:
- September 2003
-
- Article
- Export citation
Distribution of the number of words with a prescribed frequency and tests of randomness
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 34 / Issue 4 / December 2002
- Published online by Cambridge University Press:
- 01 July 2016, pp. 775-797
- Print publication:
- December 2002
-
- Article
- Export citation
On filtering in Markovian term structure models: an approximation approach
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 33 / Issue 4 / December 2001
- Published online by Cambridge University Press:
- 01 July 2016, pp. 794-809
- Print publication:
- December 2001
-
- Article
- Export citation
Estimation of the upper cutoff parameter for the tapered Pareto distribution
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 158-175
- Print publication:
- 2001
-
- Article
- Export citation
Misspecified change-point estimation problem for a Poisson process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 38 / Issue A / 2001
- Published online by Cambridge University Press:
- 14 July 2016, pp. 122-130
- Print publication:
- 2001
-
- Article
- Export citation
-
Consider an inhomogeneous Poisson process X on [0, T] whose unknown intensity function ‘switches' from a lower function g∗ to an upper function h∗ at some unknown point θ∗. What is known are continuous bounding functions g and h such that g∗ (t) ≤ g(t) ≤ h(t) ≤ h∗ (t) for 0 ≤ t ≤ T. It is shown that on the basis of n observations of the process X the maximum likelihood estimate
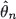 of θ∗ is consistent for n →∞, and also that
of θ∗ is consistent for n →∞, and also that 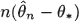 converges in law and in pth moment to limits described in terms of the unknown functions g∗ and h ∗.
converges in law and in pth moment to limits described in terms of the unknown functions g∗ and h ∗.
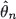 of
of 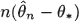 converges in law and in
converges in law and in Weakly approaching sequences of random distributions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 3 / September 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 807-822
- Print publication:
- September 2000
-
- Article
- Export citation
Hypothesis testing and Skorokhod stochastic integration
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 2 / June 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 560-574
- Print publication:
- June 2000
-
- Article
- Export citation
Approximate entropy for testing randomness
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 37 / Issue 1 / March 2000
- Published online by Cambridge University Press:
- 14 July 2016, pp. 88-100
- Print publication:
- March 2000
-
- Article
- Export citation
Estimation of the parameters of a branching process from migrating binomial observations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 30 / Issue 4 / December 1998
- Published online by Cambridge University Press:
- 01 July 2016, pp. 948-967
- Print publication:
- December 1998
-
- Article
- Export citation
Partition structures and sufficient statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 35 / Issue 3 / September 1998
- Published online by Cambridge University Press:
- 14 July 2016, pp. 622-632
- Print publication:
- September 1998
-
- Article
- Export citation
Convergence Properties of Perturbed Markov Chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 35 / Issue 1 / March 1998
- Published online by Cambridge University Press:
- 14 July 2016, pp. 1-11
- Print publication:
- March 1998
-
- Article
- Export citation
A Bayesian analysis of layered defense systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 34 / Issue 2 / June 1997
- Published online by Cambridge University Press:
- 14 July 2016, pp. 449-457
- Print publication:
- June 1997
-
- Article
- Export citation
Large deviations and the Bayesian estimation of higher-order Markov transition functions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 33 / Issue 1 / March 1996
- Published online by Cambridge University Press:
- 14 July 2016, pp. 18-27
- Print publication:
- March 1996
-
- Article
- Export citation
Robustness of the Ewens sampling formula
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 32 / Issue 3 / September 1995
- Published online by Cambridge University Press:
- 14 July 2016, pp. 609-622
- Print publication:
- September 1995
-
- Article
- Export citation
Consistency of Hill's estimator for dependent data
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 32 / Issue 1 / March 1995
- Published online by Cambridge University Press:
- 14 July 2016, pp. 139-167
- Print publication:
- March 1995
-
- Article
- Export citation
Likelihood ratios for the infinite alleles model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 31 / Issue 3 / September 1994
- Published online by Cambridge University Press:
- 14 July 2016, pp. 595-605
- Print publication:
- September 1994
-
- Article
- Export citation
Stochastic annealing for nearest-neighbour point processes with application to object recognition
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 26 / Issue 2 / June 1994
- Published online by Cambridge University Press:
- 01 July 2016, pp. 281-300
- Print publication:
- June 1994
-
- Article
- Export citation
