Refine search
Actions for selected content:
238502 results in Physics and Astronomy
Some general principles of riboswitch structure and interactions with small-molecule ligands
-
- Journal:
- Quarterly Reviews of Biophysics / Volume 58 / 2025
- Published online by Cambridge University Press:
- 28 May 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Weighted sieves with switching
- Part of
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 179 / Issue 2 / September 2025
- Published online by Cambridge University Press:
- 28 May 2025, pp. 351-372
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Weighted sieves are used to detect numbers with at most S prime factors with
 $S \in \mathbb{N}$ as small as possible. When one studies problems with two variables in somewhat symmetric roles (such as Chen primes, that is primes p such that
$S \in \mathbb{N}$ as small as possible. When one studies problems with two variables in somewhat symmetric roles (such as Chen primes, that is primes p such that  $p+2$ has at most two prime factors), one can utilise the switching principle. Here we discuss how different sieve weights work in such a situation, concentrating in particular on detecting a prime along with a product of at most three primes.
$p+2$ has at most two prime factors), one can utilise the switching principle. Here we discuss how different sieve weights work in such a situation, concentrating in particular on detecting a prime along with a product of at most three primes.As applications, we improve on the works of Yang and Harman concerning Diophantine approximation with a prime and an almost prime, and prove that, in general, one can find a pair
 $(p, P_3)$ when both the original and the switched problem have level of distribution at least
$(p, P_3)$ when both the original and the switched problem have level of distribution at least  $0.267$.
$0.267$.





Motion of a rigid sphere penetrating a deep pool
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 28 May 2025, A5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

A unified framework for mean temperature analysis in compressible turbulent channel flows
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 28 May 2025, R2
-
- Article
- Export citation

Advanced Linear Algebra
- A Concise Text with Contemporary Applications
-
- Published online:
- 27 May 2025
- Print publication:
- 12 June 2025
-
- Textbook
- Export citation

Transient dynamics of stall and reattachment at low Reynolds number
-
- Journal:
- Journal of Fluid Mechanics / Volume 1011 / 25 May 2025
- Published online by Cambridge University Press:
- 27 May 2025, A38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Wind tunnel experiments are performed to investigate stall and reattachment transients for an aerofoil and wing model at low chord Reynolds numbers (
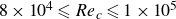 $8\times 10^4\leqslant {{Re}}_c\leqslant 1\times 10^5$) where a laminar separation bubble (LSB) may form on the suction surface. Direct force measurements and particle image velocimetry (PIV) are employed simultaneously to characterise the transient aerodynamic loading and flow field development. The imposed changes in operating conditions leading to stall and reattachment include changes in angle of attack at multiple pitch rates and changes in Reynolds number. The evolution of the lift coefficient is consistent with dynamic stall at higher Reynolds numbers, with a reduction in time delay between the passing of the static stall condition and the loss of lift for increasing pitch rate. During an increase in angle of attack, the separation bubble moves upstream prior to rapidly bursting, whereas for a decrease of Reynolds number, the LSB undergoes a more gradual monotonic increase in length prior to bursting. In contrast to notable differences in the aerodynamic loading and flow field development for different types of transients leading to LSB bursting, the process of LSB formation is less sensitive to the type of imposed change in operating conditions. Spanwise PIV measurements on the aerofoil and wing models indicate that the spanwise flow development is also insensitive to the type of imposed transient during LSB bursting and formation.
$8\times 10^4\leqslant {{Re}}_c\leqslant 1\times 10^5$) where a laminar separation bubble (LSB) may form on the suction surface. Direct force measurements and particle image velocimetry (PIV) are employed simultaneously to characterise the transient aerodynamic loading and flow field development. The imposed changes in operating conditions leading to stall and reattachment include changes in angle of attack at multiple pitch rates and changes in Reynolds number. The evolution of the lift coefficient is consistent with dynamic stall at higher Reynolds numbers, with a reduction in time delay between the passing of the static stall condition and the loss of lift for increasing pitch rate. During an increase in angle of attack, the separation bubble moves upstream prior to rapidly bursting, whereas for a decrease of Reynolds number, the LSB undergoes a more gradual monotonic increase in length prior to bursting. In contrast to notable differences in the aerodynamic loading and flow field development for different types of transients leading to LSB bursting, the process of LSB formation is less sensitive to the type of imposed change in operating conditions. Spanwise PIV measurements on the aerofoil and wing models indicate that the spanwise flow development is also insensitive to the type of imposed transient during LSB bursting and formation.
Dot to dot: High-z little red dots in
 $M_\mathrm{ bh}$–
$M_\mathrm{ bh}$– $M_\mathrm{ \star}$ diagrams with galaxy-morphology-specific scaling relations
$M_\mathrm{ \star}$ diagrams with galaxy-morphology-specific scaling relations
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 27 May 2025, e068
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The high redshift ‘little red dots’ (LRDs) detected with the James Webb Space Telescope are considered to be the cores of emerging galaxies that host active galactic nuclei (AGN). For the first time, we compare LRDs with local compact stellar systems and an array of galaxy-morphology-dependent stellar mass-black hole mass scaling relations in the
 $M_\mathrm{ bh}$–
$M_\mathrm{ bh}$– $M_{\star}$ diagrams. When considering the 2023–2024 masses for LRDs, they are not equivalent to nuclear star clusters (NSCs), with the latter having higher
$M_{\star}$ diagrams. When considering the 2023–2024 masses for LRDs, they are not equivalent to nuclear star clusters (NSCs), with the latter having higher  $M_\mathrm{ bh}/M_{\star}$ ratios. However, the least massive LRDs exhibit similar
$M_\mathrm{ bh}/M_{\star}$ ratios. However, the least massive LRDs exhibit similar  $M_\mathrm{ bh}$ and
$M_\mathrm{ bh}$ and  $M_\mathrm{ \star,gal}$ values as ultracompact dwarf (UCD) galaxies, believed to be the cores of stripped/threshed galaxies. We show that the LRDs span the
$M_\mathrm{ \star,gal}$ values as ultracompact dwarf (UCD) galaxies, believed to be the cores of stripped/threshed galaxies. We show that the LRDs span the  $M_\mathrm{ bh}$–
$M_\mathrm{ bh}$– $M_\mathrm{ \star,gal}$ diagram from UCD galaxies to primaeval lenticular galaxies. In contrast, local spiral galaxies and the subset of major-merger-built early-type galaxies define
$M_\mathrm{ \star,gal}$ diagram from UCD galaxies to primaeval lenticular galaxies. In contrast, local spiral galaxies and the subset of major-merger-built early-type galaxies define  $M_\mathrm{ bh}$–
$M_\mathrm{ bh}$– $M_{\star,gal}$ relations that are offset to higher stellar masses. Based on the emerging 2025 masses for LRDs, they may yet have similarities with NSCs, UCD galaxies, and green peas. Irrespective of this developing situation, we additionally observe that low-redshift galaxies with AGN align with the quasi-quadratic or steeper black hole scaling relations defined by local disc galaxies with directly measured black hole masses. This highlights the benefits of considering a galaxy’s morphology – which reflects its accretion and merger history – to understand the coevolution of galaxies and their black holes. Future studies of spatially resolved galaxies with secure masses at intermediate-to-high redshift hold the promise of detecting the emergence and evolution of the galaxy-morphology-dependent
$M_{\star,gal}$ relations that are offset to higher stellar masses. Based on the emerging 2025 masses for LRDs, they may yet have similarities with NSCs, UCD galaxies, and green peas. Irrespective of this developing situation, we additionally observe that low-redshift galaxies with AGN align with the quasi-quadratic or steeper black hole scaling relations defined by local disc galaxies with directly measured black hole masses. This highlights the benefits of considering a galaxy’s morphology – which reflects its accretion and merger history – to understand the coevolution of galaxies and their black holes. Future studies of spatially resolved galaxies with secure masses at intermediate-to-high redshift hold the promise of detecting the emergence and evolution of the galaxy-morphology-dependent  $M_\mathrm{ bh}$–
$M_\mathrm{ bh}$– $M_{\star}$ relations.
$M_{\star}$ relations.













WALLABY pilot survey: Properties of H i-selected dark sources and low surface brightness galaxies
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 27 May 2025, e087
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We examine the optical counterparts of the 1 829 neutral hydrogen (H i) detections in three pilot fields in the Widefield ASKAP L-band Legacy All-sky Blind surveY (WALLABY) using data from the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys DR10. We find that 17% (315) of the detections are optically low surface brightness galaxies (LSBGs; mean g-band surface brightness within 1
 $ R_e$ of
$ R_e$ of  $\gt 23$ mag arcsec
$\gt 23$ mag arcsec $^{-2}$) and 3% (55) are optically ‘dark’. We find that the gas-rich WALLABY LSBGs have low star formation efficiencies, and have stellar masses spanning five orders of magnitude, which highlights the diversity of properties across our sample. 75% of the LSBGs and all of the dark H i sources had not been catalogued prior to WALLABY. We examine the optically dark sample of the WALLABY pilot survey to verify the fidelity of the catalogue and investigate the implications for the full survey for identifying dark H i sources. We assess the H i detections without optical counterparts and identify 38 which pass further reliability tests. Of these, we find that 13 show signatures of tidal interactions. The remaining 25 detections have no obvious tidal origin, so are candidates for isolated galaxies with high H i masses, but low stellar masses and star-formation rates. Deeper H i and optical follow-up observations are required to verify the true nature of these dark sources.
$^{-2}$) and 3% (55) are optically ‘dark’. We find that the gas-rich WALLABY LSBGs have low star formation efficiencies, and have stellar masses spanning five orders of magnitude, which highlights the diversity of properties across our sample. 75% of the LSBGs and all of the dark H i sources had not been catalogued prior to WALLABY. We examine the optically dark sample of the WALLABY pilot survey to verify the fidelity of the catalogue and investigate the implications for the full survey for identifying dark H i sources. We assess the H i detections without optical counterparts and identify 38 which pass further reliability tests. Of these, we find that 13 show signatures of tidal interactions. The remaining 25 detections have no obvious tidal origin, so are candidates for isolated galaxies with high H i masses, but low stellar masses and star-formation rates. Deeper H i and optical follow-up observations are required to verify the true nature of these dark sources.



Euler Products at the Centre and Applications to Chebyshev’s Bias
- Part of
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 179 / Issue 2 / September 2025
- Published online by Cambridge University Press:
- 27 May 2025, pp. 331-349
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $\pi$ be an irreducible cuspidal automorphic representation of
$\pi$ be an irreducible cuspidal automorphic representation of  ${\mathrm{GL}}_n(\mathbb{A}_{\mathbb{Q}})$ with associated L-function
${\mathrm{GL}}_n(\mathbb{A}_{\mathbb{Q}})$ with associated L-function  $L(s, \pi)$. We study the behaviour of the partial Euler product of
$L(s, \pi)$. We study the behaviour of the partial Euler product of  $L(s, \pi)$ at the centre of the critical strip. Under the assumption of the Generalised Riemann Hypothesis for
$L(s, \pi)$ at the centre of the critical strip. Under the assumption of the Generalised Riemann Hypothesis for  $L(s, \pi)$ in conjunction with the Ramanujan–Petersson conjecture as necessary, we establish an asymptotic, off a set of finite logarithmic measure, for the partial Euler product at the central point, which confirms a conjecture of Kurokawa (2012). As an application, we obtain results towards Chebyshev’s bias in the recently proposed framework of Aoki–Koyama (2023).
$L(s, \pi)$ in conjunction with the Ramanujan–Petersson conjecture as necessary, we establish an asymptotic, off a set of finite logarithmic measure, for the partial Euler product at the central point, which confirms a conjecture of Kurokawa (2012). As an application, we obtain results towards Chebyshev’s bias in the recently proposed framework of Aoki–Koyama (2023).






Drift, diffusion and divergence
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 27 May 2025, F1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Evolutionary Map of the Universe: A new radio atlas for the southern hemisphere sky
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 27 May 2025, e071
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The GALAH survey: Data release 4
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 27 May 2025, e051
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Modelling of the atomic lines emission of fast moving pulsar nebulae
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 26 May 2025, e079
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Bow shocks generated by pulsars moving through weakly ionized interstellar medium (ISM) produce emission dominated by non-equilibrium atomic transitions. These bow shocks are primarily observed as H
 $\alpha$ nebulae. We developed a package, named Shu, that calculates non-LTE intensity maps in more than 150 spectral lines, taking into account geometrical properties of the pulsars’ motion and lines of sight. We argue here that atomic (C i, N i, O i) and ionic (S ii, N ii, O iii, Ne iv) transitions can be used as complementary and sensitive probes of ISM. We perform self-consistent 2D relativistic hydrodynamic calculations of the bow shock structure and generate non-LTE emissivity maps, combining global dynamics of relativistic flows, and detailed calculations of the non-equilibrium ionization states. We find that though typically
$\alpha$ nebulae. We developed a package, named Shu, that calculates non-LTE intensity maps in more than 150 spectral lines, taking into account geometrical properties of the pulsars’ motion and lines of sight. We argue here that atomic (C i, N i, O i) and ionic (S ii, N ii, O iii, Ne iv) transitions can be used as complementary and sensitive probes of ISM. We perform self-consistent 2D relativistic hydrodynamic calculations of the bow shock structure and generate non-LTE emissivity maps, combining global dynamics of relativistic flows, and detailed calculations of the non-equilibrium ionization states. We find that though typically 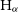 $\text{H}_\alpha$ emission is dominant, spectral fluxes in [O iii], [S ii] and [N ii] may become comparable for relatively slowly moving pulsars. Overall, morphology of non-LTE emission, especially of the ionic species, is a sensitive probe of the density structures of the ISM.
$\text{H}_\alpha$ emission is dominant, spectral fluxes in [O iii], [S ii] and [N ii] may become comparable for relatively slowly moving pulsars. Overall, morphology of non-LTE emission, especially of the ionic species, is a sensitive probe of the density structures of the ISM.


Towards a general theory of accelerating foils in the attached-flow regime
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 26 May 2025, R1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

The joint effects of planetary
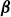 $ \boldsymbol{\beta} $, topography and friction on baroclinic instability in a two-layer quasi-geostrophic model
$ \boldsymbol{\beta} $, topography and friction on baroclinic instability in a two-layer quasi-geostrophic model
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 26 May 2025, A1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Liquid states in horizontal plate-inserted slits
-
- Journal:
- Journal of Fluid Mechanics / Volume 1012 / 10 June 2025
- Published online by Cambridge University Press:
- 26 May 2025, A2
-
- Article
- Export citation
Ion cyclotron resonance frequency slow wave simulations in the Joint European Torus tokamak
-
- Journal:
- Journal of Plasma Physics / Volume 91 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 26 May 2025, E81
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
BLINK: An end-to-end GPU high time resolution imaging pipeline for fast radio burst searches with the Murchison Widefield Array
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 42 / 2025
- Published online by Cambridge University Press:
- 26 May 2025, e074
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
FLM volume 1010 Cover and Front matter
-
- Journal:
- Journal of Fluid Mechanics / Volume 1010 / 10 May 2025
- Published online by Cambridge University Press:
- 26 May 2025, p. f1
-
- Article
-
- You have access
- Export citation
Weakly collisional steady state linear and nonlinear plasma waves
-
- Journal:
- Journal of Plasma Physics / Volume 91 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 23 May 2025, E80
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
