Refine search
Actions for selected content:
53182 results in Statistics and Probability
Private sector trust in data sharing: enablers in the European Union
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Designing data collaboratives’ governance dimensions for long-term stability: an empirical analysis
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e37
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What does a record have to do with it? Re-situating records management within Indian public data governance and policy
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward a trustworthy and inclusive data governance policy for the use of artificial intelligence in Africa
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The promise of machine learning in violent conflict forecasting
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Enhancing student performance in African smart cities: a web-based approach through advanced ensemble modeling and genetic feature optimization
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e33
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decision time: illuminating performance in India’s district courts
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Virtual laboratories: transforming research with AI
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 27 August 2024, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Limit theorems of occupation times of normalized binary contact path processes on lattices
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 27 August 2024, pp. 44-66
- Print publication:
- March 2025
-
- Article
- Export citation
Generic framework for a coherent integration of experience and exposure rating in reinsurance
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 27 August 2024, pp. 518-545
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
High Campylobacter diversity in retail chicken: epidemiologically important strains may be missed with current sampling methods
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 22 August 2024, e101
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Surveillance of SARS-CoV-2 prevalence from repeated pooled testing: application to Swiss routine data
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 22 August 2024, e100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Prevalence and persistence of Neisseria meningitidis carriage in Swedish university students – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 22 August 2024, e99
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A systematic review and meta-analysis of ambient temperature and precipitation with infections from five food-borne bacterial pathogens
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 22 August 2024, e98
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximizing the probability of visiting a set infinitely often for a Markov decision process with Borel state and action spaces
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 22 August 2024, pp. 1424-1447
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a Markov control model with Borel state space, metric compact action space, and transitions assumed to have a density function with respect to some probability measure satisfying some continuity conditions. We study the optimization problem of maximizing the probability of visiting some subset of the state space infinitely often, and we show that there exists an optimal stationary Markov policy for this problem. We endow the set of stationary Markov policies and the family of strategic probability measures with adequate topologies (namely, the narrow topology for Young measures and the
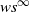 $ws^\infty$-topology, respectively) to obtain compactness and continuity properties, which allow us to obtain our main results.
$ws^\infty$-topology, respectively) to obtain compactness and continuity properties, which allow us to obtain our main results.
Non-hyperuniformity of Gibbs point processes with short-range interactions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 02 August 2024, pp. 1380-1406
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
II - Literature of Bibliography and Modern Book Production
-
- Book:
- Bibliography and Modern Book Production
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024, pp 15-76
-
- Chapter
- Export citation
Foreword
-
-
- Book:
- Bibliography and Modern Book Production
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024, pp xxi-xxii
-
- Chapter
- Export citation
V - Collation and Description of Books (Old and New) Their Structure and Parts
-
- Book:
- Bibliography and Modern Book Production
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024, pp 117-130
-
- Chapter
- Export citation
Appendix - Examination Questions
-
- Book:
- Bibliography and Modern Book Production
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024, pp 323-332
-
- Chapter
- Export citation
