Refine search
Actions for selected content:
53182 results in Statistics and Probability
Dedication
-
- Book:
- Bibliography and Modern Book Production
- Published by:
- Wits University Press
- Published online:
- 17 April 2025
- Print publication:
- 01 August 2024, pp v-vi
-
- Chapter
- Export citation
Optimal drift rate control and two-sided impulse control for a Brownian system with the long-run average criterion
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 31 July 2024, pp. 271-304
- Print publication:
- March 2025
-
- Article
- Export citation
-
In this paper, we consider a joint drift rate control and two-sided impulse control problem in which the system manager adjusts the drift rate as well as the instantaneous relocation for a Brownian motion, with the objective of minimizing the total average state-related cost and control cost. The system state can be negative. Assuming that instantaneous upward and downward relocations take a different cost structure, which consists of both a setup cost and a variable cost, we prove that the optimal control policy takes an
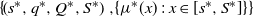 $\left\{ {\!\left( {{s^{\ast}},{q^{\ast}},{Q^{\ast}},{S^{\ast}}} \right),\!\left\{ {{\mu ^{\ast}}(x)\,:\,x \in [ {{s^{\ast}},{S^{\ast}}}]} \right\}} \right\}$ form. Specifically, the optimal impulse control policy is characterized by a quadruple
$\left\{ {\!\left( {{s^{\ast}},{q^{\ast}},{Q^{\ast}},{S^{\ast}}} \right),\!\left\{ {{\mu ^{\ast}}(x)\,:\,x \in [ {{s^{\ast}},{S^{\ast}}}]} \right\}} \right\}$ form. Specifically, the optimal impulse control policy is characterized by a quadruple 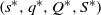 $\left( {{s^{\ast}},{q^{\ast}},{Q^{\ast}},{S^{\ast}}} \right)$, under which the system state will be immediately relocated upwardly to
$\left( {{s^{\ast}},{q^{\ast}},{Q^{\ast}},{S^{\ast}}} \right)$, under which the system state will be immediately relocated upwardly to 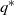 ${q^{\ast}}$ once it drops to
${q^{\ast}}$ once it drops to 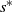 ${s^{\ast}}$ and be immediately relocated downwardly to
${s^{\ast}}$ and be immediately relocated downwardly to 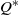 ${Q^{\ast}}$ once it rises to
${Q^{\ast}}$ once it rises to 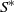 ${S^{\ast}}$; the optimal drift rate control policy will depend solely on the current system state, which is characterized by a function
${S^{\ast}}$; the optimal drift rate control policy will depend solely on the current system state, which is characterized by a function 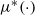 ${\mu ^{\ast}}\!\left( \cdot \right)$ for the system state staying in
${\mu ^{\ast}}\!\left( \cdot \right)$ for the system state staying in 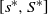 $[ {{s^{\ast}},{S^{\ast}}}]$. By analyzing an associated free boundary problem consisting of an ordinary differential equation and several free boundary conditions, we obtain these optimal policy parameters and show the optimality of the proposed policy using a lower-bound approach. Finally, we investigate the effect of the system parameters on the optimal policy parameters as well as the optimal system’s long-run average cost numerically.
$[ {{s^{\ast}},{S^{\ast}}}]$. By analyzing an associated free boundary problem consisting of an ordinary differential equation and several free boundary conditions, we obtain these optimal policy parameters and show the optimality of the proposed policy using a lower-bound approach. Finally, we investigate the effect of the system parameters on the optimal policy parameters as well as the optimal system’s long-run average cost numerically.
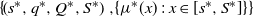
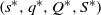
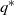
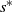
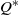
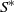
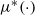
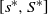
Tail variance and confidence of using tail conditional expectation: Analytical representation, capital adequacy, and asymptotics
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 31 July 2024, pp. 346-369
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the speed of convergence of discrete Pickands constants to continuous ones
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 31 July 2024, pp. 111-135
- Print publication:
- March 2025
-
- Article
- Export citation
-
In this manuscript, we address open questions raised by Dieker and Yakir (2014), who proposed a novel method of estimating (discrete) Pickands constants
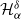 $\mathcal{H}^\delta_\alpha$ using a family of estimators
$\mathcal{H}^\delta_\alpha$ using a family of estimators 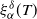 $\xi^\delta_\alpha(T)$,
$\xi^\delta_\alpha(T)$, 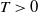 $T>0$, where
$T>0$, where 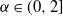 $\alpha\in(0,2]$ is the Hurst parameter, and
$\alpha\in(0,2]$ is the Hurst parameter, and 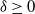 $\delta\geq0$ is the step size of the regular discretization grid. We derive an upper bound for the discretization error
$\delta\geq0$ is the step size of the regular discretization grid. We derive an upper bound for the discretization error 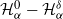 $\mathcal{H}_\alpha^0 - \mathcal{H}_\alpha^\delta$, whose rate of convergence agrees with Conjecture 1 of Dieker and Yakir (2014) in the case
$\mathcal{H}_\alpha^0 - \mathcal{H}_\alpha^\delta$, whose rate of convergence agrees with Conjecture 1 of Dieker and Yakir (2014) in the case 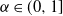 $\alpha\in(0,1]$ and agrees up to logarithmic terms for
$\alpha\in(0,1]$ and agrees up to logarithmic terms for 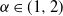 $\alpha\in(1,2)$. Moreover, we show that all moments of
$\alpha\in(1,2)$. Moreover, we show that all moments of 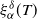 $\xi_\alpha^\delta(T)$ are uniformly bounded and the bias of the estimator decays no slower than
$\xi_\alpha^\delta(T)$ are uniformly bounded and the bias of the estimator decays no slower than 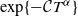 $\exp\{-\mathcal CT^{\alpha}\}$, as T becomes large.
$\exp\{-\mathcal CT^{\alpha}\}$, as T becomes large.
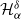
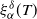
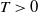
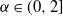
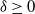
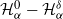
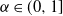
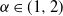
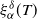
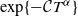
Optimal risk sharing for lambda value-at-risk
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 29 July 2024, pp. 171-203
- Print publication:
- March 2025
-
- Article
- Export citation
Tail asymptotics and precise large deviations for some Poisson cluster processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 26 July 2024, pp. 204-240
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Error bounds for one-dimensional constrained Langevin approximations for nearly density-dependent Markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 26 July 2024, pp. 825-867
- Print publication:
- September 2024
-
- Article
- Export citation
Convergence of hybrid slice sampling via spectral gap
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 25 July 2024, pp. 1440-1466
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Change of measure in a Heston–Hawkes stochastic volatility model
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 24 July 2024, pp. 1370-1399
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contents
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp v-vi
-
- Chapter
- Export citation
3 - Attitude Formation at the Individual Level
- from Part I - The Fundamentals of Public Opinion
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 25-37
-
- Chapter
- Export citation
Graphs
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp ix-x
-
- Chapter
- Export citation
5 - Understanding Bias and Error
- from Part II - The Pollster as Data Scientist
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 55-82
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp xvii-xviii
-
- Chapter
- Export citation
Part IV - The Pollster as Spin Doctor
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 167-222
-
- Chapter
- Export citation
Index
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 223-231
-
- Chapter
- Export citation
2 - What Is Public Opinion?
- from Part I - The Fundamentals of Public Opinion
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 15-24
-
- Chapter
- Export citation
12 - Communicating in the Brazilian Presidential Election
- from Part IV - The Pollster as Spin Doctor
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 190-209
-
- Chapter
- Export citation
Tables
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp xiii-xvi
-
- Chapter
- Export citation
6 - Assessing a Single Poll during the 2016 US Presidential Election
- from Part II - The Pollster as Data Scientist
-
- Book:
- Polls, Pollsters, and Public Opinion
- Published online:
- 01 November 2024
- Print publication:
- 04 July 2024, pp 83-93
-
- Chapter
- Export citation
