Refine search
Actions for selected content:
53182 results in Statistics and Probability
A non-homogeneous alternating renewal process model for interval censoring
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 16 September 2024, pp. 494-515
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Quenched worst-case scenario for root deletion in targeted cutting of random recursive trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 September 2024, pp. 67-83
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We propose a method for cutting down a random recursive tree that focuses on its higher-degree vertices. Enumerate the vertices of a random recursive tree of size n according to the decreasing order of their degrees; namely, let
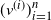 $(v^{(i)})_{i=1}^{n}$ be such that
$(v^{(i)})_{i=1}^{n}$ be such that 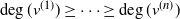 $\deg(v^{(1)}) \geq \cdots \geq \deg (v^{(n)})$. The targeted vertex-cutting process is performed by sequentially removing vertices
$\deg(v^{(1)}) \geq \cdots \geq \deg (v^{(n)})$. The targeted vertex-cutting process is performed by sequentially removing vertices 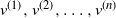 $v^{(1)}, v^{(2)}, \ldots, v^{(n)}$ and keeping only the subtree containing the root after each removal. The algorithm ends when the root is picked to be removed. The total number of steps for this procedure,
$v^{(1)}, v^{(2)}, \ldots, v^{(n)}$ and keeping only the subtree containing the root after each removal. The algorithm ends when the root is picked to be removed. The total number of steps for this procedure, 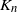 $K_n$, is upper bounded by
$K_n$, is upper bounded by 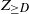 $Z_{\geq D}$, which denotes the number of vertices that have degree at least as large as the degree of the root. We prove that
$Z_{\geq D}$, which denotes the number of vertices that have degree at least as large as the degree of the root. We prove that 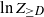 $\ln Z_{\geq D}$ grows as
$\ln Z_{\geq D}$ grows as 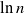 $\ln n$ asymptotically and obtain its limiting behavior in probability. Moreover, we obtain that the kth moment of
$\ln n$ asymptotically and obtain its limiting behavior in probability. Moreover, we obtain that the kth moment of 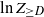 $\ln Z_{\geq D}$ is proportional to
$\ln Z_{\geq D}$ is proportional to 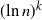 $(\!\ln n)^k$. As a consequence, we obtain that the first-order growth of
$(\!\ln n)^k$. As a consequence, we obtain that the first-order growth of 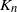 $K_n$ is upper bounded by
$K_n$ is upper bounded by 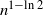 $n^{1-\ln 2}$, which is substantially smaller than the required number of removals if, instead, the vertices were selected uniformly at random.
$n^{1-\ln 2}$, which is substantially smaller than the required number of removals if, instead, the vertices were selected uniformly at random.
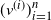
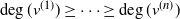
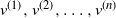
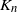
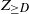
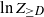
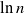
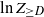
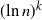
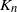
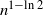
Stochastic gradient descent for barycenters in Wasserstein space
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 September 2024, pp. 15-43
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uncertainty quantification and confidence intervals for naive rare-event estimators
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 02 September 2024, pp. 84-110
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Tail risk driven by investment losses and exogenous shocks
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 712-737
- Print publication:
- September 2024
-
- Article
- Export citation
Optimal annuitization under stochastic interest rates
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 09 October 2024, pp. 626-651
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A study of one-factor copula models from a tail dependence perspective
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 04 October 2024, pp. 679-711
- Print publication:
- September 2024
-
- Article
- Export citation
Multiple yield curve modeling and forecasting using deep learning
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 04 October 2024, pp. 463-494
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal surrender policy for reverse mortgage loans
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 24 September 2024, pp. 600-625
- Print publication:
- September 2024
-
- Article
- Export citation
Impact of correlation between interest rates and mortality rates on the valuation of various life insurance products
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 09 September 2024, pp. 569-599
- Print publication:
- September 2024
-
- Article
- Export citation
ASB volume 54 issue 3 Cover and Front matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 23 October 2024, pp. f1-f2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
Optimal defined-contribution pension management with financial and mortality risks
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 24 September 2024, pp. 546-568
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
JPR volume 61 issue 3 Cover and Front matter
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 18 September 2024, pp. f1-f2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
JPR volume 61 issue 3 Cover and Back matter
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 18 September 2024, pp. b1-b2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
APR volume 56 issue 3 Cover and Front matter
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 19 September 2024, pp. f1-f2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
Optimal reinsurance design under distortion risk measures and reinsurer’s default risk with partial recovery
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 04 October 2024, pp. 738-766
- Print publication:
- September 2024
-
- Article
- Export citation
ASB volume 54 issue 3 Cover and Back matter
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 23 October 2024, pp. b1-b2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
APR volume 56 issue 3 Cover and Back matter
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 19 September 2024, pp. b1-b2
- Print publication:
- September 2024
-
- Article
-
- You have access
- Export citation
A governance and legal framework for getting to “yes” with enterprise-level data integration
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring African skills 4.0 required for 4IR industry: a systematic literature review
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 30 August 2024, e36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
