Refine search
Actions for selected content:
53182 results in Statistics and Probability
Professionalism: bridging the missing link between environmental MRV and carbon neutrality
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 11 October 2024, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sampling repulsive Gibbs point processes using random graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 October 2024, pp. 63-89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vertex-critical graphs far from edge-criticality
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 October 2024, pp. 151-157
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
 $r$ be any positive integer. We prove that for every sufficiently large
$r$ be any positive integer. We prove that for every sufficiently large 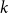 $k$ there exists a
$k$ there exists a 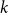 $k$-chromatic vertex-critical graph
$k$-chromatic vertex-critical graph 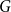 $G$ such that
$G$ such that  $\chi (G-R)=k$ for every set
$\chi (G-R)=k$ for every set 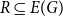 $R \subseteq E(G)$ with
$R \subseteq E(G)$ with 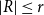 $|R|\le r$. This partially solves a problem posed by Erdős in 1985, who asked whether the above statement holds for
$|R|\le r$. This partially solves a problem posed by Erdős in 1985, who asked whether the above statement holds for 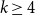 $k \ge 4$.
$k \ge 4$.

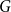

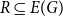
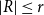
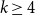
On transience of
 $\mathrm{M}/\mathrm{G}/\infty$ queues
$\mathrm{M}/\mathrm{G}/\infty$ queues
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 572-575
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider an
 $\mathrm{M}/\mathrm{G}/\infty$ queue with infinite expected service time. We then provide the transience/recurrence classification of the states (the system is said to be at state n if there are n customers being served), observing also that here (unlike irreducible Markov chains, for example) it is possible for recurrent and transient states to coexist. We also prove a lower bound on the growth speed in the transient case.
$\mathrm{M}/\mathrm{G}/\infty$ queue with infinite expected service time. We then provide the transience/recurrence classification of the states (the system is said to be at state n if there are n customers being served), observing also that here (unlike irreducible Markov chains, for example) it is possible for recurrent and transient states to coexist. We also prove a lower bound on the growth speed in the transient case.


Approximation of subgraph counts in the uniform attachment model
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 90-114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We use Stein’s method to obtain distributional approximations of subgraph counts in the uniform attachment model or random directed acyclic graph; we provide also estimates of rates of convergence. In particular, we give uni- and multi-variate Poisson approximations to the counts of cycles and normal approximations to the counts of unicyclic subgraphs; we also give a partial result for the counts of trees. We further find a class of multicyclic graphs whose subgraph counts are a.s. bounded as
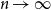 $n\to \infty$.
$n\to \infty$.
A note on extremal constructions for the Erdős–Rademacher problem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 October 2024, pp. 52-62
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For given positive integers
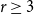 $r\ge 3$,
$r\ge 3$,  $n$ and
$n$ and 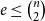 $e\le \binom{n}{2}$, the famous Erdős–Rademacher problem asks for the minimum number of
$e\le \binom{n}{2}$, the famous Erdős–Rademacher problem asks for the minimum number of  $r$-cliques in a graph with
$r$-cliques in a graph with  $n$ vertices and
$n$ vertices and  $e$ edges. A conjecture of Lovász and Simonovits from the 1970s states that, for every
$e$ edges. A conjecture of Lovász and Simonovits from the 1970s states that, for every 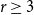 $r\ge 3$, if
$r\ge 3$, if  $n$ is sufficiently large then, for every
$n$ is sufficiently large then, for every  $e\le \binom{n}{2}$, at least one extremal graph can be obtained from a complete partite graph by adding a triangle-free graph into one part.
$e\le \binom{n}{2}$, at least one extremal graph can be obtained from a complete partite graph by adding a triangle-free graph into one part.In this note, we explicitly write the minimum number of
 $r$-cliques predicted by the above conjecture. Also, we describe what we believe to be the set of extremal graphs for any
$r$-cliques predicted by the above conjecture. Also, we describe what we believe to be the set of extremal graphs for any 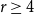 $r\ge 4$ and all large
$r\ge 4$ and all large  $n$, amending the previous conjecture of Pikhurko and Razborov.
$n$, amending the previous conjecture of Pikhurko and Razborov.
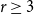




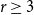



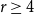

Evolution of cooperation in networks with well-connected cooperators
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 10 October 2024, pp. 305-320
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The challenge of etiologic diagnosis of subacute and chronic meningitis: an analysis of 183 patients
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 10 October 2024, e123
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment and comparison of model estimated and directly observed weather data for prediction of diarrhoea aetiology
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 09 October 2024, e122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Partial recovery and weak consistency in the non-uniform hypergraph stochastic block model
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 09 October 2024, pp. 1-51
-
- Article
- Export citation
-
We consider the community detection problem in sparse random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), a general model of random networks with community structure and higher-order interactions. When the random hypergraph has bounded expected degrees, we provide a spectral algorithm that outputs a partition with at least a
 $\gamma$ fraction of the vertices classified correctly, where
$\gamma$ fraction of the vertices classified correctly, where 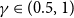 $\gamma \in (0.5,1)$ depends on the signal-to-noise ratio (SNR) of the model. When the SNR grows slowly as the number of vertices goes to infinity, our algorithm achieves weak consistency, which improves the previous results in Ghoshdastidar and Dukkipati ((2017) Ann. Stat. 45(1) 289–315.) for non-uniform HSBMs.
$\gamma \in (0.5,1)$ depends on the signal-to-noise ratio (SNR) of the model. When the SNR grows slowly as the number of vertices goes to infinity, our algorithm achieves weak consistency, which improves the previous results in Ghoshdastidar and Dukkipati ((2017) Ann. Stat. 45(1) 289–315.) for non-uniform HSBMs.Our spectral algorithm consists of three major steps: (1) Hyperedge selection: select hyperedges of certain sizes to provide the maximal signal-to-noise ratio for the induced sub-hypergraph; (2) Spectral partition: construct a regularised adjacency matrix and obtain an approximate partition based on singular vectors; (3) Correction and merging: incorporate the hyperedge information from adjacency tensors to upgrade the error rate guarantee. The theoretical analysis of our algorithm relies on the concentration and regularisation of the adjacency matrix for sparse non-uniform random hypergraphs, which can be of independent interest.

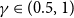
Drivers of human Leptospira infection in the Pacific Islands: A systematic review
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 08 October 2024, e118
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The k-core in percolated dense graph sequences
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 08 October 2024, pp. 298-318
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We determine the order of the k-core in a large class of dense graph sequences. Let
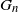 $G_n$ be a sequence of undirected, n-vertex graphs with edge weights
$G_n$ be a sequence of undirected, n-vertex graphs with edge weights 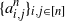 $\{a^n_{i,j}\}_{i,j \in [n]}$ that converges to a graphon
$\{a^n_{i,j}\}_{i,j \in [n]}$ that converges to a graphon 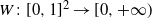 $W\colon[0,1]^2 \to [0,+\infty)$ in the cut metric. Keeping an edge (i,j) of
$W\colon[0,1]^2 \to [0,+\infty)$ in the cut metric. Keeping an edge (i,j) of 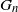 $G_n$ with probability
$G_n$ with probability 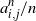 ${a^n_{i,j}}/{n}$ independently, we obtain a sequence of random graphs
${a^n_{i,j}}/{n}$ independently, we obtain a sequence of random graphs 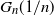 $G_n({1}/{n})$. Using a branching process and the theory of dense graph limits, under mild assumptions we obtain the order of the k-core of random graphs
$G_n({1}/{n})$. Using a branching process and the theory of dense graph limits, under mild assumptions we obtain the order of the k-core of random graphs 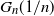 $G_n({1}/{n})$. Our result can also be used to obtain the threshold of appearance of a k-core of order n.
$G_n({1}/{n})$. Our result can also be used to obtain the threshold of appearance of a k-core of order n.
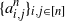
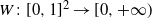
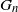
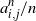
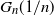
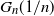
Superspreading of SARS-CoV-2: a systematic review and meta-analysis of event attack rates and individual transmission patterns
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 08 October 2024, e121
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Spatio-temporal distributions of COVID-19 vaccine doses uptake in the Netherlands: a Bayesian ecological modelling analysis
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 07 October 2024, e119
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Stationary measures and the continuous-state branching process conditioned on extinction
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 07 October 2024, pp. 576-602
- Print publication:
- June 2025
-
- Article
- Export citation
-
We consider continuous-state branching processes (CB processes) which become extinct almost surely. First, we tackle the problem of describing the stationary measures on
 $(0,+\infty)$ for such CB processes. We give a representation of the stationary measure in terms of scale functions of related Lévy processes. Then we prove that the stationary measure can be obtained from the vague limit of the potential measure, and, in the critical case, can also be obtained from the vague limit of a normalized transition probability. Next, we prove some limit theorems for the CB process conditioned on extinction in a near future and on extinction at a fixed time. We obtain non-degenerate limit distributions which are of the size-biased type of the stationary measure in the critical case and of the Yaglom distribution in the subcritical case. Finally we explore some further properties of the limit distributions.
$(0,+\infty)$ for such CB processes. We give a representation of the stationary measure in terms of scale functions of related Lévy processes. Then we prove that the stationary measure can be obtained from the vague limit of the potential measure, and, in the critical case, can also be obtained from the vague limit of a normalized transition probability. Next, we prove some limit theorems for the CB process conditioned on extinction in a near future and on extinction at a fixed time. We obtain non-degenerate limit distributions which are of the size-biased type of the stationary measure in the critical case and of the Yaglom distribution in the subcritical case. Finally we explore some further properties of the limit distributions.

Will COVID-19 become mild, like a cold?
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 07 October 2024, e120
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Boundary crossing problems and functional transformations for Ornstein–Uhlenbeck processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 07 October 2024, pp. 395-421
- Print publication:
- March 2025
-
- Article
- Export citation
Epidemiology of scarlet fever in Victoria, Australia, 2007–2017
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 04 October 2024, e116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bacteriological characteristics and changes of Streptococcus pneumoniae serotype 35B after vaccine implementation in Japan
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 04 October 2024, e114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hospitalizations and emergency attendance averted by influenza vaccination in Victoria, Australia, 2017 – 2019
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 04 October 2024, e111
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
