Refine search
Actions for selected content:
53182 results in Statistics and Probability
A large-scale particle system with independent jumps and distributed synchronization
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 04 October 2024, pp. 677-707
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study a system consisting of n particles, moving forward in jumps on the real line. Each particle can make both independent jumps, whose sizes have some distribution, and ‘synchronization’ jumps, which allow it to join a randomly chosen other particle if the latter happens to be ahead of it. The system state is the empirical distribution of particle locations. We consider the mean-field asymptotic regime where
 $n\to\infty$. We prove that
$n\to\infty$. We prove that 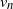 $v_n$, the steady-state speed of advance of the particle system, converges, as
$v_n$, the steady-state speed of advance of the particle system, converges, as 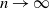 $n\to\infty$, to a limit
$n\to\infty$, to a limit  $v_{**}$ which can easily be found from a minimum speed selection principle. Also we prove that as
$v_{**}$ which can easily be found from a minimum speed selection principle. Also we prove that as  $n\to\infty$, the system dynamics converges to that of a deterministic mean-field limit (MFL). We show that the average speed of advance of any MFL is lower-bounded by
$n\to\infty$, the system dynamics converges to that of a deterministic mean-field limit (MFL). We show that the average speed of advance of any MFL is lower-bounded by  $v_{**}$, and the speed of a ‘benchmark’ MFL, resulting from all particles initially being co-located, is equal to
$v_{**}$, and the speed of a ‘benchmark’ MFL, resulting from all particles initially being co-located, is equal to 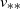 $v_{**}$. In the special case of exponentially distributed independent jump sizes, we prove that a traveling-wave MFL with speed v exists if and only if
$v_{**}$. In the special case of exponentially distributed independent jump sizes, we prove that a traveling-wave MFL with speed v exists if and only if  $v\ge v_{**}$, with
$v\ge v_{**}$, with  $v_{**}$ having a simple explicit form; we also show the existence of traveling waves for the modified systems with a left or right boundary moving at a constant speed v. We provide bounds on an MFL’s average speed of advance, depending on the right tail exponent of its initial state. We conjecture that these results for exponential jump sizes extend to general jump sizes.
$v_{**}$ having a simple explicit form; we also show the existence of traveling waves for the modified systems with a left or right boundary moving at a constant speed v. We provide bounds on an MFL’s average speed of advance, depending on the right tail exponent of its initial state. We conjecture that these results for exponential jump sizes extend to general jump sizes.

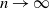



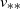


Trends in shigellosis notifications in England, January 2016 to March 2023
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 04 October 2024, e115
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An outbreak associated with Escherichia albertii in a junior high school, China
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 04 October 2024, e117
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the rate of convergence for an α-stable central limit theorem under sublinear expectation
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 209-233
- Print publication:
- March 2025
-
- Article
- Export citation
-
We propose a monotone approximation scheme for a class of fully nonlinear degenerate partial integro-differential equations which characterize nonlinear
 $\alpha$-stable Lévy processes under a sublinear expectation space with
$\alpha$-stable Lévy processes under a sublinear expectation space with 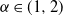 $\alpha\in(1,2)$. We further establish the error bounds for the monotone approximation scheme. This in turn yields an explicit Berry–Esseen bound and convergence rate for the
$\alpha\in(1,2)$. We further establish the error bounds for the monotone approximation scheme. This in turn yields an explicit Berry–Esseen bound and convergence rate for the  $\alpha$-stable central limit theorem under sublinear expectation.
$\alpha$-stable central limit theorem under sublinear expectation.


A queue with independent and identically distributed arrivals
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 319-346
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Finite element approximations for stochastic control problems with unbounded state space
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 367-394
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Maximum likelihood estimation for spinal-structured trees
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 October 2024, pp. 234-268
- Print publication:
- March 2025
-
- Article
- Export citation
-
We investigate some aspects of the problem of the estimation of birth distributions (BDs) in multi-type Galton–Watson trees (MGWs) with unobserved types. More precisely, we consider two-type MGWs called spinal-structured trees. This kind of tree is characterized by a spine of special individuals whose BD
 $\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by
$\nu$ is different from the other individuals in the tree (called normal, and whose BD is denoted by 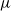 $\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate
$\mu$). In this work, we show that even in such a very structured two-type population, our ability to distinguish the two types and estimate 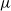 $\mu$ and
$\mu$ and  $\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of
$\nu$ is constrained by a trade-off between the growth-rate of the population and the similarity of 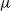 $\mu$ and
$\mu$ and  $\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if
$\nu$. Indeed, if the growth-rate is too large, large deviation events are likely to be observed in the sampling of the normal individuals, preventing us from distinguishing them from special ones. Roughly speaking, our approach succeeds if 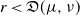 $r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and
$r\lt \mathfrak{D}(\mu,\nu)$, where r is the exponential growth-rate of the population and 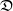 $\mathfrak{D}$ is a divergence measuring the dissimilarity between
$\mathfrak{D}$ is a divergence measuring the dissimilarity between 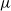 $\mu$ and
$\mu$ and  $\nu$.
$\nu$.


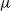

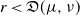
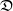
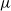

Mpox in UK households: estimating secondary attack rates and factors associated with transmission, May–November 2022
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 02 October 2024, e113
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Risk factors for COVID-19 transmission in England: a multilevel modelling study using routine contact tracing data
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 02 October 2024, e112
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The not-so-forbidden triad: Evaluating the assumptions of the Strength of Weak Ties
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 October 2024, pp. 289-304
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing the seasonality of tuberculosis case notifications in the UK, 2000–2018
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 01 October 2024, e108
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interleukins in the pathogenesis of influenza and other acute respiratory viral infections
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 30 September 2024, e109
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Everything but the kitchen sink: The use of multiple hypothesis generation methods to investigate an outbreak of Salmonella Enteritidis associated with frozen profiteroles and eclairs
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 30 September 2024, e107
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A multi-provincial outbreak of Salmonella Newport infections associated with red onions: A report of the largest Salmonella outbreak in Canada in over 20 years
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 30 September 2024, e106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Combined visualization of genomic and epidemiological data for outbreaks
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 30 September 2024, e110
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Varicella vaccine effectiveness evaluation in Wuxi, China: A retrospective cohort study
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 30 September 2024, e105
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Essential Epidemiology
- An Introduction for Students and Health Professionals
-
- Published online:
- 27 September 2024
- Print publication:
- 12 November 2024
-
- Textbook
- Export citation
The incubation for urethral gonorrhoea among men who have sex with men with and without oropharyngeal gonorrhoea
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 27 September 2024, e104
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Omicron incidence and seroprevalence among children in Montreal, Canada, in early 2023: final results from the longitudinal EnCORE serology study
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 25 September 2024, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Severe acute respiratory syndrome coronavirus 2-reactive salivary antibody detection in South Carolina emergency healthcare workers, September 2019–March 2020
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 25 September 2024, e102
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
