Refine search
Actions for selected content:
53191 results in Statistics and Probability
The distribution of the maximum protection number in simply generated trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 12 April 2024, pp. 518-553
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The protection number of a vertex
 $v$ in a tree is the length of the shortest path from
$v$ in a tree is the length of the shortest path from  $v$ to any leaf contained in the maximal subtree where
$v$ to any leaf contained in the maximal subtree where  $v$ is the root. In this paper, we determine the distribution of the maximum protection number of a vertex in simply generated trees, thereby refining a recent result of Devroye, Goh, and Zhao. Two different cases can be observed: if the given family of trees allows vertices of outdegree
$v$ is the root. In this paper, we determine the distribution of the maximum protection number of a vertex in simply generated trees, thereby refining a recent result of Devroye, Goh, and Zhao. Two different cases can be observed: if the given family of trees allows vertices of outdegree 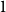 $1$, then the maximum protection number is on average logarithmic in the tree size, with a discrete double-exponential limiting distribution. If no such vertices are allowed, the maximum protection number is doubly logarithmic in the tree size and concentrated on at most two values. These results are obtained by studying the singular behaviour of the generating functions of trees with bounded protection number. While a general distributional result by Prodinger and Wagner can be used in the first case, we prove a variant of that result in the second case.
$1$, then the maximum protection number is on average logarithmic in the tree size, with a discrete double-exponential limiting distribution. If no such vertices are allowed, the maximum protection number is doubly logarithmic in the tree size and concentrated on at most two values. These results are obtained by studying the singular behaviour of the generating functions of trees with bounded protection number. While a general distributional result by Prodinger and Wagner can be used in the first case, we prove a variant of that result in the second case.



Machine Learning with High-Cardinality Categorical Features in Actuarial Applications
- Part of
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 11 April 2024, pp. 213-238
- Print publication:
- May 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From bias to black boxes: understanding and managing the risks of AI – an actuarial perspective
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A stand-alone proximity-based gaming wearable for remote physical activity monitoring
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 11 April 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using graph neural networks for wall modeling in compressible anisothermal flows
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 10 April 2024, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Network analysis in peace and state building: revealing power elites
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 09 April 2024, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generating preferential attachment graphs via a Pólya urn with expanding colors
-
- Journal:
- Network Science / Volume 12 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 08 April 2024, pp. 139-159
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Buffon’s problem determines Gaussian curvature in three geometries
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 08 April 2024, pp. 1127-1138
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Decreased risk of non-influenza respiratory infection after influenza B virus infection in children
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 08 April 2024, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Algorithms for the ferromagnetic Potts model on expanders
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 05 April 2024, pp. 487-517
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We give algorithms for approximating the partition function of the ferromagnetic
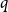 $q$-color Potts model on graphs of maximum degree
$q$-color Potts model on graphs of maximum degree 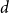 $d$. Our primary contribution is a fully polynomial-time approximation scheme for
$d$. Our primary contribution is a fully polynomial-time approximation scheme for 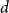 $d$-regular graphs with an expansion condition at low temperatures (that is, bounded away from the order-disorder threshold). The expansion condition is much weaker than in previous works; for example, the expansion exhibited by the hypercube suffices. The main improvements come from a significantly sharper analysis of standard polymer models; we use extremal graph theory and applications of Karger’s algorithm to count cuts that may be of independent interest. It is #BIS-hard to approximate the partition function at low temperatures on bounded-degree graphs, so our algorithm can be seen as evidence that hard instances of #BIS are rare. We also obtain efficient algorithms in the Gibbs uniqueness region for bounded-degree graphs. While our high-temperature proof follows more standard polymer model analysis, our result holds in the largest-known range of parameters
$d$-regular graphs with an expansion condition at low temperatures (that is, bounded away from the order-disorder threshold). The expansion condition is much weaker than in previous works; for example, the expansion exhibited by the hypercube suffices. The main improvements come from a significantly sharper analysis of standard polymer models; we use extremal graph theory and applications of Karger’s algorithm to count cuts that may be of independent interest. It is #BIS-hard to approximate the partition function at low temperatures on bounded-degree graphs, so our algorithm can be seen as evidence that hard instances of #BIS are rare. We also obtain efficient algorithms in the Gibbs uniqueness region for bounded-degree graphs. While our high-temperature proof follows more standard polymer model analysis, our result holds in the largest-known range of parameters 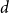 $d$ and
$d$ and 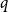 $q$.
$q$.
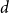
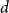
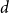
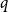
Super-replication of life-contingent options under the Black–Scholes framework
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 05 April 2024, pp. 1263-1277
- Print publication:
- December 2024
-
- Article
- Export citation
Coherent distributions on the square–extreme points and asymptotics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 05 April 2024, pp. 1240-1262
- Print publication:
- December 2024
-
- Article
- Export citation
-
Let
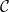 $\mathcal{C}$ denote the family of all coherent distributions on the unit square
$\mathcal{C}$ denote the family of all coherent distributions on the unit square 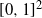 $[0,1]^2$, i.e. all those probability measures
$[0,1]^2$, i.e. all those probability measures 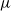 $\mu$ for which there exists a random vector
$\mu$ for which there exists a random vector 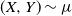 $(X,Y)\sim \mu$, a pair
$(X,Y)\sim \mu$, a pair 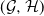 $(\mathcal{G},\mathcal{H})$ of
$(\mathcal{G},\mathcal{H})$ of 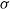 $\sigma$-fields, and an event E such that
$\sigma$-fields, and an event E such that 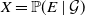 $X=\mathbb{P}(E\mid\mathcal{G})$,
$X=\mathbb{P}(E\mid\mathcal{G})$, 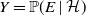 $Y=\mathbb{P}(E\mid\mathcal{H})$ almost surely. We examine the set
$Y=\mathbb{P}(E\mid\mathcal{H})$ almost surely. We examine the set 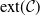 $\mathrm{ext}(\mathcal{C})$ of extreme points of
$\mathrm{ext}(\mathcal{C})$ of extreme points of 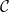 $\mathcal{C}$ and provide its general characterisation. Moreover, we establish several structural properties of finitely-supported elements of
$\mathcal{C}$ and provide its general characterisation. Moreover, we establish several structural properties of finitely-supported elements of 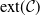 $\mathrm{ext}(\mathcal{C})$. We apply these results to obtain the asymptotic sharp bound
$\mathrm{ext}(\mathcal{C})$. We apply these results to obtain the asymptotic sharp bound 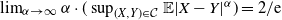 $\lim_{\alpha \to \infty}\alpha\cdot(\sup_{(X,Y)\in \mathcal{C}}\mathbb{E}|X-Y|^{\alpha}) = {2}/{\mathrm{e}}$.
$\lim_{\alpha \to \infty}\alpha\cdot(\sup_{(X,Y)\in \mathcal{C}}\mathbb{E}|X-Y|^{\alpha}) = {2}/{\mathrm{e}}$.
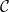
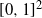
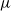
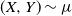
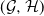
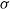
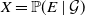
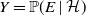
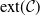
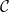
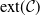
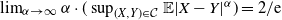
Signature-based validation of real-world economic scenarios
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 04 April 2024, pp. 410-440
- Print publication:
- May 2024
-
- Article
- Export citation
An extreme worst-case risk measure by expectile
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 02 April 2024, pp. 1195-1214
- Print publication:
- December 2024
-
- Article
- Export citation
-
Expectiles have received increasing attention as a risk measure in risk management because of their coherency and elicitability at the level
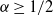 $\alpha\geq1/2$. With a view to practical risk assessments, this paper delves into the worst-case expectile, where only partial information on the underlying distribution is available and there is no closed-form representation. We explore the asymptotic behavior of the worst-case expectile on two specified ambiguity sets: one is through the Wasserstein distance from a reference distribution and transforms this problem into a convex optimization problem via the well-known Kusuoka representation, and the other is induced by higher moment constraints. We obtain precise results in some special cases; nevertheless, there are no unified closed-form solutions. We aim to fully characterize the extreme behaviors; that is, we pursue an approximate solution as the level
$\alpha\geq1/2$. With a view to practical risk assessments, this paper delves into the worst-case expectile, where only partial information on the underlying distribution is available and there is no closed-form representation. We explore the asymptotic behavior of the worst-case expectile on two specified ambiguity sets: one is through the Wasserstein distance from a reference distribution and transforms this problem into a convex optimization problem via the well-known Kusuoka representation, and the other is induced by higher moment constraints. We obtain precise results in some special cases; nevertheless, there are no unified closed-form solutions. We aim to fully characterize the extreme behaviors; that is, we pursue an approximate solution as the level  $\alpha $ tends to 1, which is aesthetically pleasing. As an application of our technique, we investigate the ambiguity set induced by higher moment conditions. Finally, we compare our worst-case expectile approach with a more conservative method based on stochastic order, which is referred to as ‘model aggregation’.
$\alpha $ tends to 1, which is aesthetically pleasing. As an application of our technique, we investigate the ambiguity set induced by higher moment conditions. Finally, we compare our worst-case expectile approach with a more conservative method based on stochastic order, which is referred to as ‘model aggregation’.

Convergence of the height process of supercritical Galton–Watson forests with an application to the configuration model in the critical window
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 02 April 2024, pp. 1064-1105
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Topological reconstruction of compact supports of dependent stationary random variables
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 02 April 2024, pp. 1339-1369
- Print publication:
- December 2024
-
- Article
- Export citation
-
In this paper we extend results on reconstruction of probabilistic supports of independent and identically distributed random variables to supports of dependent stationary
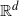 ${\mathbb R}^d$-valued random variables. All supports are assumed to be compact of positive reach in Euclidean space. Our main results involve the study of the convergence in the Hausdorff sense of a cloud of stationary dependent random vectors to their common support. A novel topological reconstruction result is stated, and a number of illustrative examples are presented. The example of the Möbius Markov chain on the circle is treated at the end with simulations.
${\mathbb R}^d$-valued random variables. All supports are assumed to be compact of positive reach in Euclidean space. Our main results involve the study of the convergence in the Hausdorff sense of a cloud of stationary dependent random vectors to their common support. A novel topological reconstruction result is stated, and a number of illustrative examples are presented. The example of the Möbius Markov chain on the circle is treated at the end with simulations.
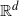
AN ASYMPTOTIC THEORY FOR JUMP DIFFUSION MODELS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 02 April 2024, pp. 844-906
-
- Article
-
- You have access
- Open access
- Export citation
Data-driven healthcare indicators via precision gaming: With application to India
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of COVID-19 on the degree of compliance with hand hygiene: a repeated cross-sectional study
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e69
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TIME-VARYING PARAMETER REGRESSIONS WITH STATIONARY PERSISTENT DATA
-
- Journal:
- Econometric Theory / Volume 41 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 01 April 2024, pp. 817-843
-
- Article
-
- You have access
- Open access
- Export citation
