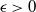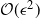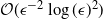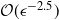Refine search
Actions for selected content:
53183 results in Statistics and Probability
The latent cognitive structures of social networks
-
- Journal:
- Network Science / Volume 12 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 25 April 2024, pp. 202-233
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Recurrence and transience of a Markov chain on
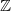 $\mathbb Z$+ and evaluation of prior distributions for a Poisson mean
$\mathbb Z$+ and evaluation of prior distributions for a Poisson mean
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 25 April 2024, pp. 1361-1379
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
UK Asbestos Working Party Update 2020
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 23 April 2024, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An inequality for log-concave functions and its use in the study of failure rates
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 23 April 2024, pp. 695-704
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Update from the UK asbestos working party
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 23 April 2024, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
De-risking in multi-state life and health insurance
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 2 / July 2024
- Published online by Cambridge University Press:
- 22 April 2024, pp. 423-441
-
- Article
- Export citation
Behaviour of the minimum degree throughout the
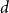 ${\textit{d}}$-process
${\textit{d}}$-process
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 22 April 2024, pp. 564-582
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The
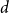 $d$-process generates a graph at random by starting with an empty graph with
$d$-process generates a graph at random by starting with an empty graph with  $n$ vertices, then adding edges one at a time uniformly at random among all pairs of vertices which have degrees at most
$n$ vertices, then adding edges one at a time uniformly at random among all pairs of vertices which have degrees at most 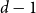 $d-1$ and are not mutually joined. We show that, in the evolution of a random graph with
$d-1$ and are not mutually joined. We show that, in the evolution of a random graph with  $n$ vertices under the
$n$ vertices under the 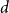 $d$-process with
$d$-process with 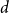 $d$ fixed, with high probability, for each
$d$ fixed, with high probability, for each 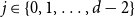 $j \in \{0,1,\dots,d-2\}$, the minimum degree jumps from
$j \in \{0,1,\dots,d-2\}$, the minimum degree jumps from 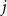 $j$ to
$j$ to 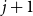 $j+1$ when the number of steps left is on the order of
$j+1$ when the number of steps left is on the order of 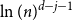 $\ln (n)^{d-j-1}$. This answers a question of Ruciński and Wormald. More specifically, we show that, when the last vertex of degree
$\ln (n)^{d-j-1}$. This answers a question of Ruciński and Wormald. More specifically, we show that, when the last vertex of degree 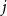 $j$ disappears, the number of steps left divided by
$j$ disappears, the number of steps left divided by 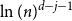 $\ln (n)^{d-j-1}$ converges in distribution to the exponential random variable of mean
$\ln (n)^{d-j-1}$ converges in distribution to the exponential random variable of mean 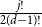 $\frac{j!}{2(d-1)!}$; furthermore, these
$\frac{j!}{2(d-1)!}$; furthermore, these 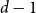 $d-1$ distributions are independent.
$d-1$ distributions are independent.
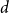

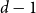

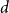
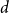
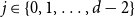
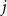
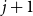
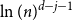
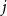
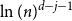
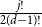
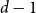
Exploring the practices of “data-driven innovation” in the European public sector
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Characteristics and biomarkers associated with mortality in COVID-19 patients presenting to the emergency department
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e76
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comments on the Solvency II Risk Margin and proposed amendments
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A granular examination of gender and racial disparities in federal procurement
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The exercise of discretion on commutation factors in defined benefit schemes: time for change?
-
- Journal:
- British Actuarial Journal / Volume 29 / 2024
- Published online by Cambridge University Press:
- 19 April 2024, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discounted cost exponential semi-Markov decision processes with unbounded transition rates: a service rate control problem with impatient customers
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 4 / October 2024
- Published online by Cambridge University Press:
- 18 April 2024, pp. 668-694
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Strategic underreporting and optimal deductible insurance
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 54 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 18 April 2024, pp. 767-790
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Macrolide resistance of Mycoplasma pneumoniae in several regions of China from 2013 to 2019
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 18 April 2024, e75
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Population and contact tracer uptake of New Zealand’s QR-code-based digital contact tracing app for COVID-19
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 17 April 2024, e66
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ENCOMPASSING TESTS FOR NONPARAMETRIC REGRESSIONS
-
- Journal:
- Econometric Theory / Volume 41 / Issue 3 / June 2025
- Published online by Cambridge University Press:
- 17 April 2024, pp. 709-738
-
- Article
- Export citation
-
We set up a formal framework to characterize encompassing of nonparametric models through the
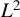 $L^2$ distance. We contrast it to previous literature on the comparison of nonparametric regression models. We then develop testing procedures for the encompassing hypothesis that are fully nonparametric. Our test statistics depend on kernel regression, raising the issue of bandwidth’s choice. We investigate two alternative approaches to obtain a “small bias property” for our test statistics. We show the validity of a wild bootstrap method. We empirically study the use of a data-driven bandwidth and illustrate the attractive features of our tests for small and moderate samples.
$L^2$ distance. We contrast it to previous literature on the comparison of nonparametric regression models. We then develop testing procedures for the encompassing hypothesis that are fully nonparametric. Our test statistics depend on kernel regression, raising the issue of bandwidth’s choice. We investigate two alternative approaches to obtain a “small bias property” for our test statistics. We show the validity of a wild bootstrap method. We empirically study the use of a data-driven bandwidth and illustrate the attractive features of our tests for small and moderate samples.
A generalization of Bondy’s pancyclicity theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 33 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 17 April 2024, pp. 554-563
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The bipartite independence number of a graph
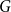 $G$, denoted as
$G$, denoted as 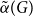 $\tilde \alpha (G)$, is the minimal number
$\tilde \alpha (G)$, is the minimal number 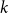 $k$ such that there exist positive integers
$k$ such that there exist positive integers  $a$ and
$a$ and 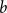 $b$ with
$b$ with 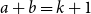 $a+b=k+1$ with the property that for any two disjoint sets
$a+b=k+1$ with the property that for any two disjoint sets 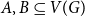 $A,B\subseteq V(G)$ with
$A,B\subseteq V(G)$ with 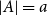 $|A|=a$ and
$|A|=a$ and 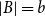 $|B|=b$, there is an edge between
$|B|=b$, there is an edge between 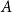 $A$ and
$A$ and 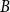 $B$. McDiarmid and Yolov showed that if
$B$. McDiarmid and Yolov showed that if 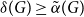 $\delta (G)\geq \tilde \alpha (G)$ then
$\delta (G)\geq \tilde \alpha (G)$ then 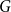 $G$ is Hamiltonian, extending the famous theorem of Dirac which states that if
$G$ is Hamiltonian, extending the famous theorem of Dirac which states that if 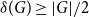 $\delta (G)\geq |G|/2$ then
$\delta (G)\geq |G|/2$ then 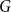 $G$ is Hamiltonian. In 1973, Bondy showed that, unless
$G$ is Hamiltonian. In 1973, Bondy showed that, unless 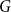 $G$ is a complete bipartite graph, Dirac’s Hamiltonicity condition also implies pancyclicity, i.e., existence of cycles of all the lengths from
$G$ is a complete bipartite graph, Dirac’s Hamiltonicity condition also implies pancyclicity, i.e., existence of cycles of all the lengths from 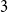 $3$ up to
$3$ up to  $n$. In this paper, we show that
$n$. In this paper, we show that 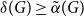 $\delta (G)\geq \tilde \alpha (G)$ implies that
$\delta (G)\geq \tilde \alpha (G)$ implies that 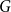 $G$ is pancyclic or that
$G$ is pancyclic or that 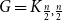 $G=K_{\frac{n}{2},\frac{n}{2}}$, thus extending the result of McDiarmid and Yolov, and generalizing the classic theorem of Bondy.
$G=K_{\frac{n}{2},\frac{n}{2}}$, thus extending the result of McDiarmid and Yolov, and generalizing the classic theorem of Bondy.

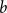
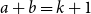
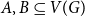
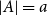
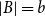
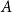
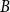
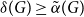
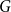
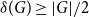
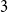

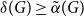
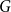
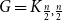
A genetically related cluster of Salmonella Typhimurium cases in humans associated with ruminant livestock and related food chains, United Kingdom, August 2021–December 2022
-
- Journal:
- Epidemiology & Infection / Volume 152 / 2024
- Published online by Cambridge University Press:
- 16 April 2024, e89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Antithetic multilevel particle filters
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 16 April 2024, pp. 1400-1439
- Print publication:
- December 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we consider the filtering of partially observed multidimensional diffusion processes that are observed regularly at discrete times. This is a challenging problem which requires the use of advanced numerical schemes based upon time-discretization of the diffusion process and then the application of particle filters. Perhaps the state-of-the-art method for moderate-dimensional problems is the multilevel particle filter of Jasra et al. (SIAM J. Numer. Anal. 55 (2017), 3068–3096). This is a method that combines multilevel Monte Carlo and particle filters. The approach in that article is based intrinsically upon an Euler discretization method. We develop a new particle filter based upon the antithetic truncated Milstein scheme of Giles and Szpruch (Ann. Appl. Prob. 24 (2014), 1585–1620). We show empirically for a class of diffusion problems that, for
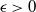 $\epsilon>0$ given, the cost to produce a mean squared error (MSE) of
$\epsilon>0$ given, the cost to produce a mean squared error (MSE) of 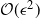 $\mathcal{O}(\epsilon^2)$ in the estimation of the filter is
$\mathcal{O}(\epsilon^2)$ in the estimation of the filter is 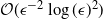 $\mathcal{O}(\epsilon^{-2}\log(\epsilon)^2)$. In the case of multidimensional diffusions with non-constant diffusion coefficient, the method of Jasra et al. (2017) requires a cost of
$\mathcal{O}(\epsilon^{-2}\log(\epsilon)^2)$. In the case of multidimensional diffusions with non-constant diffusion coefficient, the method of Jasra et al. (2017) requires a cost of 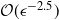 $\mathcal{O}(\epsilon^{-2.5})$ to achieve the same MSE.
$\mathcal{O}(\epsilon^{-2.5})$ to achieve the same MSE.